library(tidyverse)
library(tidytext)
library(udpipe)
library(stopwords)10 Токенизация и лемматизация
Основные этапы NLP включают в себя токенизацию, морфологический и синтаксический анализ, а также семантический анализ В этом уроке речь пойдет про первые три этапа. Мы научимся разбивать текст на токены (слова), определять морфологические характеристики слов и находить их начальные формы (леммы), а также анализировать структуру предложения с использованием синтаксических парсеров.
10.1 Токенизация и анализ частотностей
10.1.1 Виды токенов
Токенизация — процесс разделения текста на составляющие (их называют «токенами»). Токенами могут быть слова, символьные или словесные энграмы (n-grams), то есть сочетания символов или слов, даже предложения или параграфы.
Токенизировать можно в базовом R с использованием регулярных выражений, и Jockers (2014) прекрасно показывает, как это можно делать. Но мы воспользуемся двумя пакетами, которые предназначены специально для работы с текстовыми данными и разделяют идеологию tidyverse: tidytext (Silge и Robinson 2017) и tokenizers (Hvitfeldt и Silge 2022).
Для анализа воспользуемся датасетом c латинским текстом “Записок о Галльской войне”, который мы подготовили в предыдущем уроке. Его можно забрать отсюда.
load("../data/caesar.RData")В нашем тексте есть макроны, которые можно убрать при помощи регулярных выражений.
caesar <- caesar |>
group_by(liber) |>
mutate(liber = cur_group_id()) |>
mutate(text = str_replace_all(text, c("ā"="a", "ī"="i", "ē"="e", "ō"="o", "ū"="u"))) |>
ungroup()
caesar Функция unnest_tokens() из пакета tidytext принимает на входе тиббл, название столбца, в котором хранится текст для токенизации, а также название нового столбца, куда будут “сложены” отдельные токены (зачастую это слова, но не обязательно).
unnest_tokens(
tbl,
output,
input,
token = "words",
format = c("text", "man", "latex", "html", "xml"),
to_lower = TRUE,
drop = TRUE,
collapse = NULL,
...
)Аргумент token принимает следующие значения:
- “words” (default),
- “characters”,
- “character_shingles”,
- “ngrams”,
- “skip_ngrams”,
- “sentences”,
- “lines”,
- “paragraphs”,
- “regex”,
- “ptb” (Penn Treebank).
Используя уже знакомую функцию map, можно запустить unnest_tokens() с разными аргументами:
test <- tibble(text = "Gallia est omnis divisa in partes tres, quarum unam incolunt Belgae, aliam Aquitani, tertiam qui ipsorum lingua Celtae, nostra Galli appellantur. Hi omnes lingua, institutis, legibus inter se differunt.")params <- tribble(
~tbl, ~output, ~input, ~token,
test, "word", "text", "words",
test, "sentence", "text", "sentences",
test, "char", "text", "characters",
)
paramsparams |>
pmap(unnest_tokens) [[1]]
# A tibble: 29 × 1
word
<chr>
1 gallia
2 est
3 omnis
4 divisa
5 in
6 partes
7 tres
8 quarum
9 unam
10 incolunt
# ℹ 19 more rows
[[2]]
# A tibble: 2 × 1
sentence
<chr>
1 gallia est omnis divisa in partes tres, quarum unam incolunt belgae, aliam aq…
2 hi omnes lingua, institutis, legibus inter se differunt.
[[3]]
# A tibble: 166 × 1
char
<chr>
1 g
2 a
3 l
4 l
5 i
6 a
7 e
8 s
9 t
10 o
# ℹ 156 more rowsСледующие значения аргумента token требуют также аргумента n:
params <- tribble(
~tbl, ~output, ~input, ~token, ~n,
test, "ngram", "text", "ngrams", 3,
test, "shingles", "text", "character_shingles", 3
)
params |>
pmap(unnest_tokens) |>
head()[[1]]
# A tibble: 27 × 1
ngram
<chr>
1 gallia est omnis
2 est omnis divisa
3 omnis divisa in
4 divisa in partes
5 in partes tres
6 partes tres quarum
7 tres quarum unam
8 quarum unam incolunt
9 unam incolunt belgae
10 incolunt belgae aliam
# ℹ 17 more rows
[[2]]
# A tibble: 164 × 1
shingles
<chr>
1 gal
2 all
3 lli
4 lia
5 iae
6 aes
7 est
8 sto
9 tom
10 omn
# ℹ 154 more rowsДальше мы будем работать со словами, поэтому сохраним токенизированный текст “Записок” в виде “опрятного” датасета (одно наблюдение - один ряд).
caesar_tokens <- caesar |>
unnest_tokens("word", "text")
caesar_tokensПри работе с данными в текстовом формате unnest_tokens() опирается на пакет tokenizers, из которого в нашем случае подтягивает функцию tokenize_words. У этой функции есть несколько полезных аргументов: strip_non_alphanum (удаляет пробельные символы и пунктуацию), strip_punct (удаляет пунктуацию), strip_numeric (удаляет числа).
Эти аргументы мы тоже можем задать через unnest_tokens(), поскольку у функции есть аргумент ... (загляните в документацию, чтобы убедиться).
caesar |>
unnest_tokens("word", "text", strip_punct = FALSE)10.1.2 Cтоп-слова
Большая часть слов, которые мы сейчас видим в корпусе – это стоп-слова, не несущие смысловой нагрузки. Для английского языка список стоп-слов уже доступен в пакете tidytext; в других случаях их следует загружать отдельно. Для многих языков стоп-слова доступны в пакете {stopwords}.
stopwords_getlanguages("stopwords-iso") [1] "af" "ar" "hy" "eu" "bn" "br" "bg" "ca" "zh" "hr" "cs" "da" "nl" "en" "eo"
[16] "et" "fi" "fr" "gl" "de" "el" "ha" "he" "hi" "hu" "id" "ga" "it" "ja" "ko"
[31] "ku" "la" "lt" "lv" "ms" "mr" "no" "fa" "pl" "pt" "ro" "ru" "sk" "sl" "so"
[46] "st" "es" "sw" "sv" "th" "tl" "tr" "uk" "ur" "vi" "yo" "zu"sw <- stopwords(language = "la", source = "ancient")
head(sw)[1] "a" "ab" "abiud" "abs" "ac" "ad" Расширенный список стоп-слов для латыни и греческого можно найти здесь.
caesar_words_tidy <- caesar_tokens |>
filter(!word %in% sw)
caesar_words_tidyУборка закончена, мы готовы к подсчетам.
10.1.3 Абсолютная частотность
Для начала посмотрим на самые частотные слова по книгам.
caesar_counts <- caesar_words_tidy |>
count(word, liber, sort = TRUE)
caesar_counts |>
group_by(liber) |>
slice_head(n = 10) |>
ungroup() |>
ggplot(aes(reorder_within(word, n, liber), n, fill = as.factor(liber))) +
geom_col(show.legend = F) +
scale_x_reordered() +
facet_wrap(~liber, nrow = 2, scales = "free") +
coord_flip() +
theme_light() +
xlab(NULL)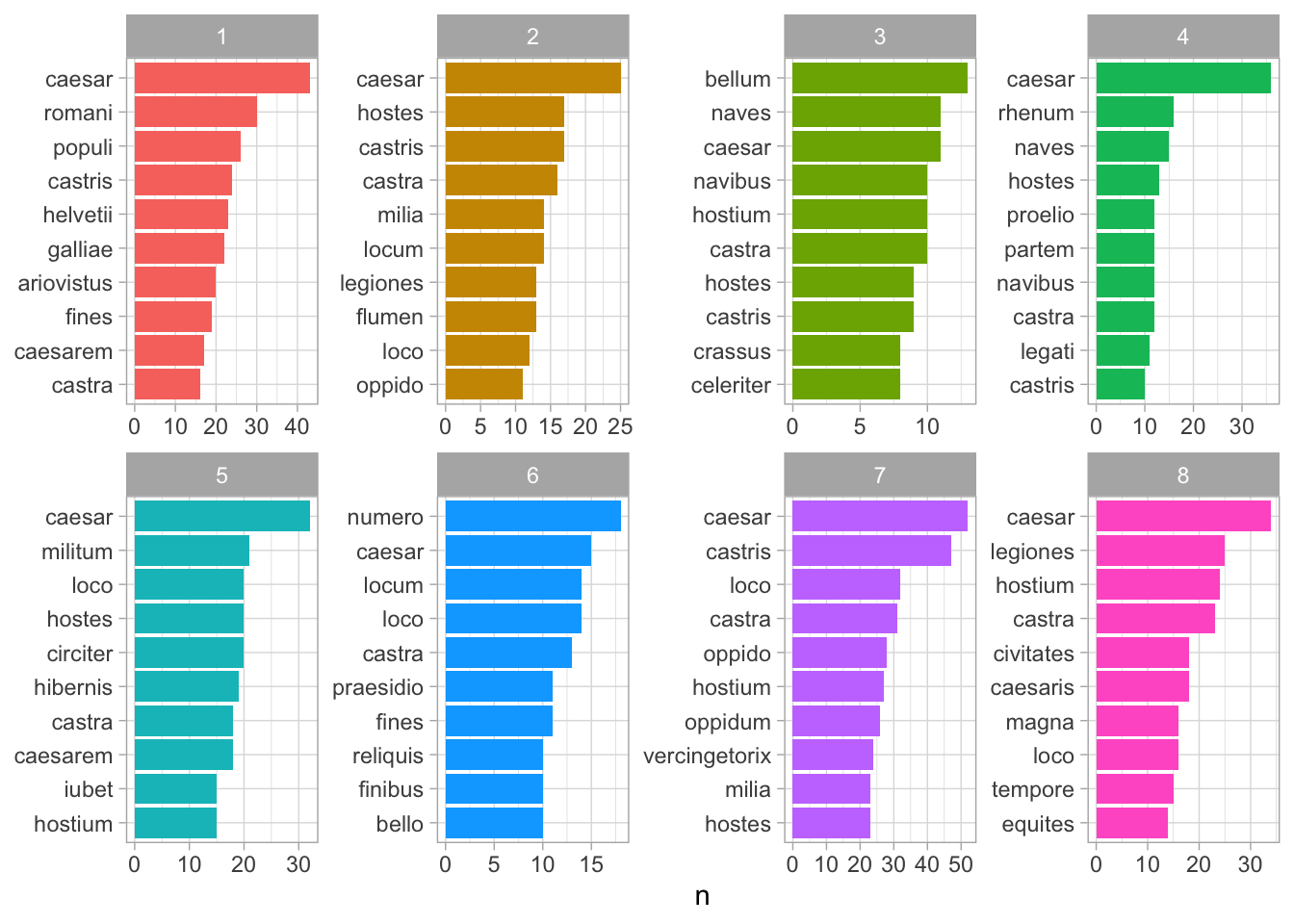
10.1.4 TF и закон Ципфа
Абсолютная частотность – плохой показатель для текстов разной длины. Чтобы тексты было проще сравнивать, разделим показатели частотности на общее число токенов в тексте. Этот показатель принято обозначать как tf (term frequency). Анализируя относительные частотности, важно иметь в виду, что подавляющее большинство слов встречается очень редко, а слов с высокой частотностью - мало. Считаем по токенам до удаления стоп-слов:
tokens_tf <- caesar_tokens |>
mutate(total = nrow(caesar_tokens)) |>
add_count(word, sort = TRUE) |>
distinct(word, total, n) |>
mutate(tf = n / total) |>
arrange(-tf)
tokens_tftokens_tf |>
ggplot(aes(tf)) +
geom_histogram(show.legend = FALSE,
fill = "aliceblue",
color = "grey",
bins = 50) +
theme_light() #+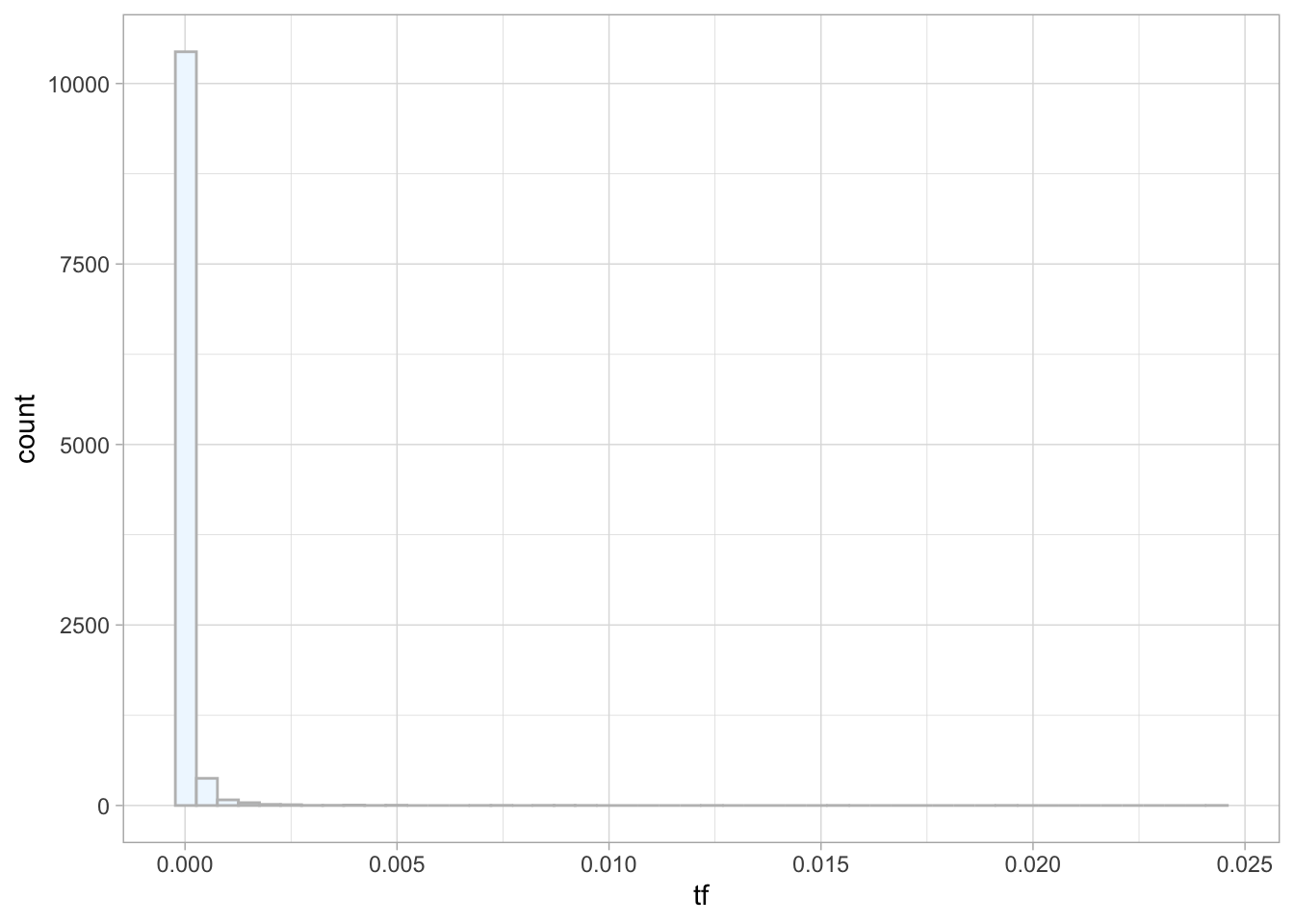
#coord_cartesian(ylim = c(NA, 3000), xlim = c(NA, 0.016))Подобная картина характерна для естественных языков. Распределения слов в них подчиняются закону Ципфа. Этот закон носит имя американского лингвиста Джорджа Ципфа (George Zipf) и утверждает следующее: если все слова языка или длинного текста упорядочить по убыванию частоты использования, частотность (tf) n-го слова в списке окажется обратно пропорциональной его рангу (r) в степени α. Это значит (в самом общем случае), что если ранг увеличится в n раз, то частотность во столько же раз должна упасть: второе слово в корпусе встречается примерно в два раза реже, чем первое (Savoy 2020, 24).
\[tf_{r_i} = \frac{c}{r^α_i}\]
Здесь c - это константа, которая оценивается для каждого случая отдельно, как и параметр α. Иначе говоря:
\[ tf_{r_i} \times r^α_i = c \] Посмотрим на ранги и частотность первых 50 слов.
tokens_tf_rank <- tokens_tf |>
mutate(rank = row_number())
tokens_tf_rank |>
ggplot(aes(rank, tf)) +
geom_line(linewidth = 1.1, alpha = 0.7, color = "navyblue") +
theme_light()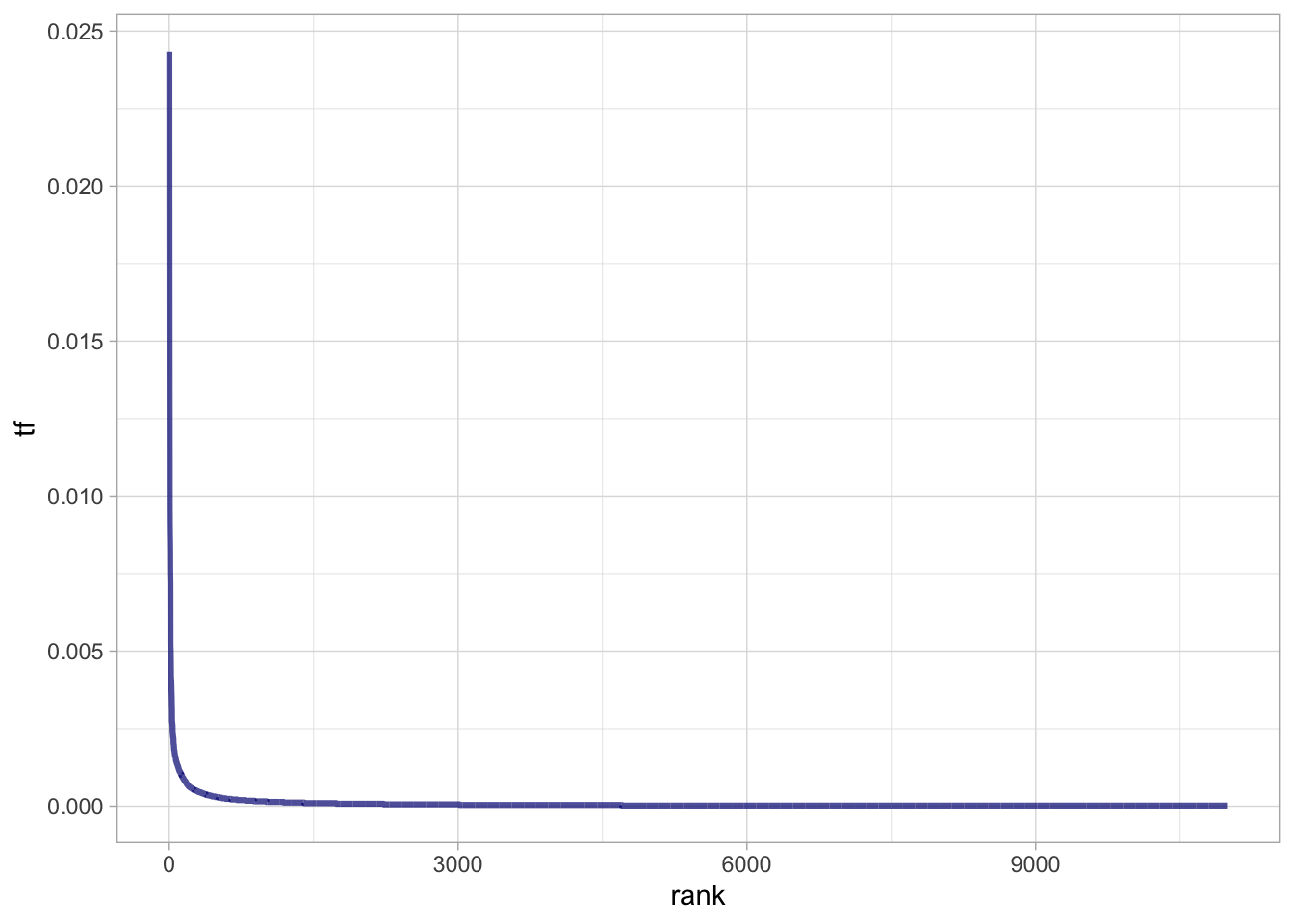
Вспомнив, что логарифм дроби равен разности логарифмов числителя и знаменателя, запишем:
\[log(tf_{r_i}) = c - α \times log(r_i) \]
Таким образом, мы получаем близкую к линейность зависимость, где константа c определяет точку пересечения оси y, a коэффициентα - угол наклона прямой. Графически это выглядит так:
tokens_tf_rank |>
ggplot(aes(rank, tf)) +
geom_line(size = 1.1, alpha = 0.7, color = "navyblue") +
scale_x_log10() +
scale_y_log10()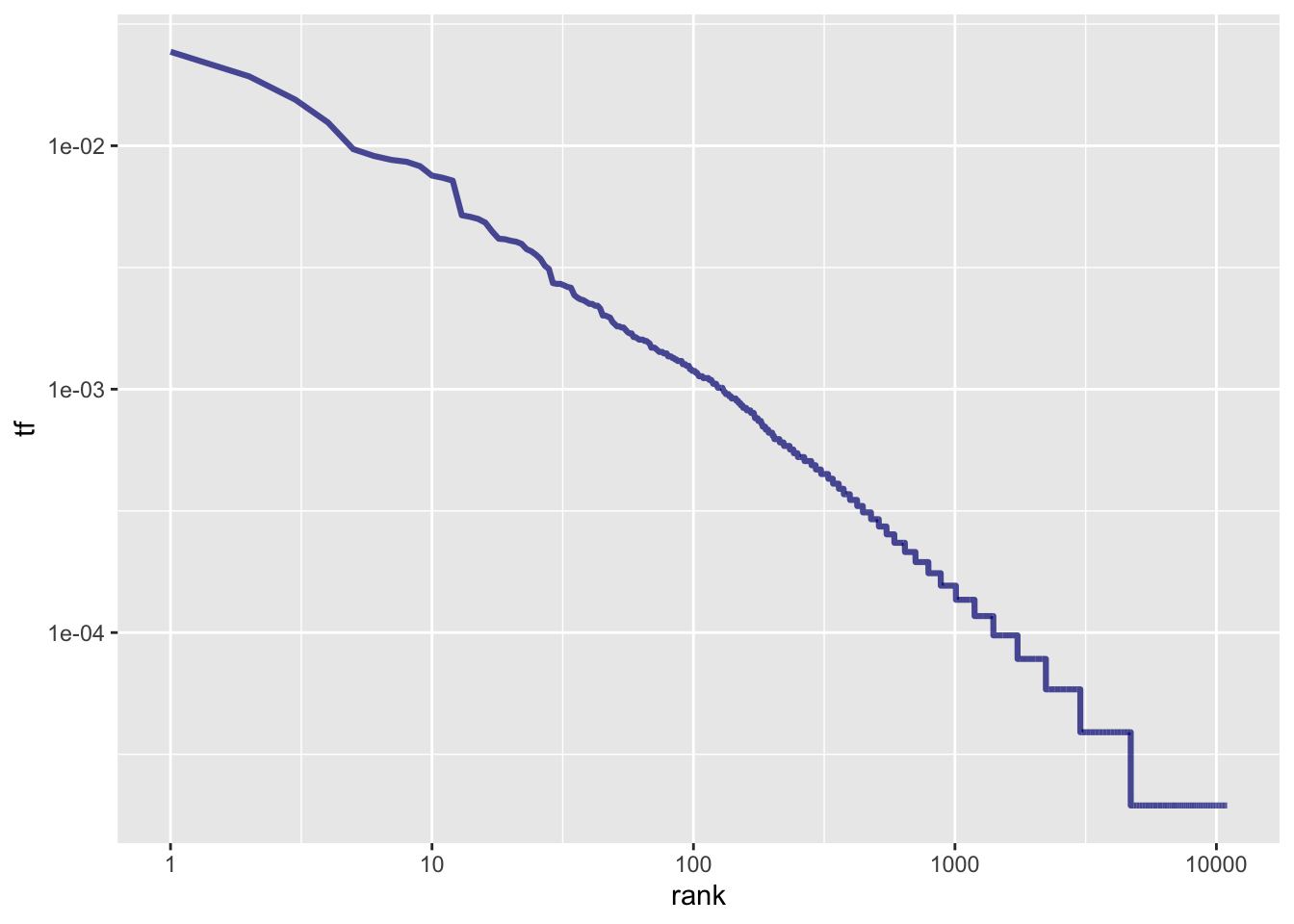
Чтобы узнать точные коэффициенты, придется подогнать линейную модель (об этом поговорим подробнее в следующих уроках):
tokens_tf_rank |>
ggplot(aes(rank, tf)) +
geom_line(size = 1.1, alpha = 0.7, color = "navyblue") +
geom_smooth(method = "lm",
linetype = 2,
color = "tomato") +
scale_x_log10() +
scale_y_log10() +
theme_light()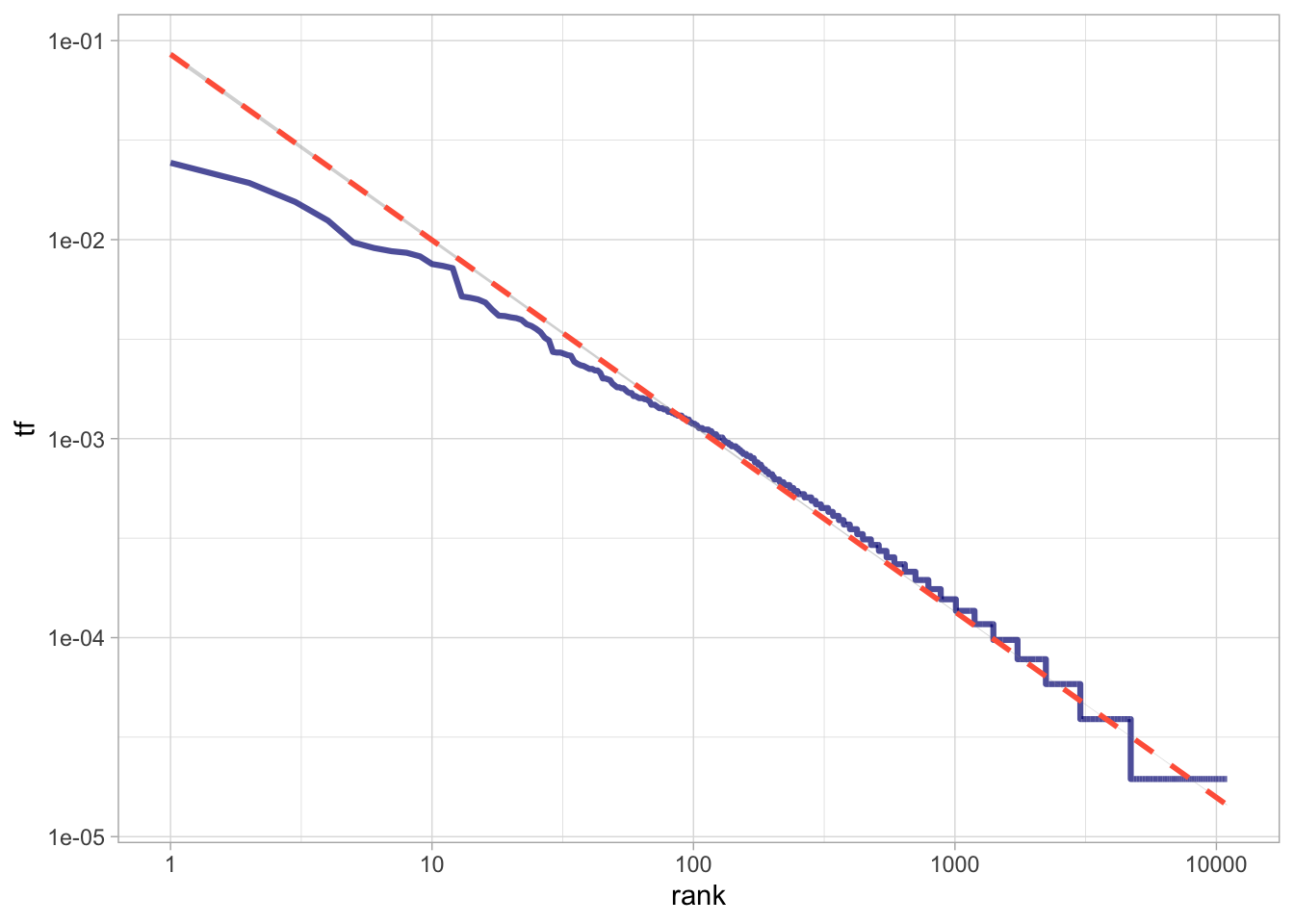
Отклонения от линии регрессии наиболее заметны в “хвостах” графика. Это характерно для многих корпусов: как очень редких, так и самых частотных слов не так много, как предсказывает закон Ципфа. Кроме того, внизу кривая почти всегда приобретает ступенчатый вид, потому что слова встречаются в корпусе дискретное число раз: ранг у них разный, а частотности одинаковые.
10.1.5 TF-IDF
Наиболее частотные слова (с низким рангом) наименее подвержены влиянию тематики, поэтому их используют для стилометрического анализа. Если отобрать наиболее частотные после удаления стоп-слов, то мы получим достаточно адекватное отражение тематики документов. Если же мы необходимо найти наиболее характерные для документов токены, то применяется другая мера, которая называется tf-idf (term frequency - inverse document frequency).
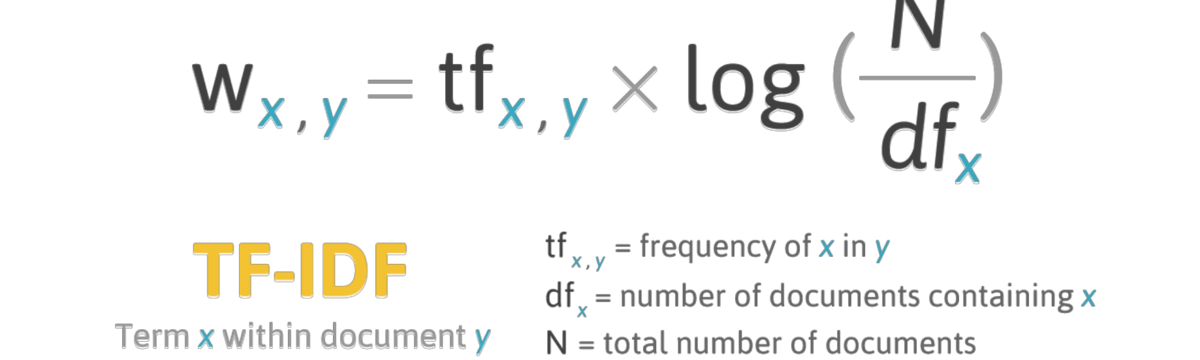
Логарифм единицы равен нулю, поэтому если слово встречается во всех документах, его tf-idf равно нулю. Чем выше tf-idf, тем более характерно некое слово для документа. При этом относительная частотность тоже учитывается.
Функция bind_tf_idf() принимает на входе тиббл с абсолютной частотностью для каждого слова.
caesar_tfidf <- caesar_counts |>
bind_tf_idf(word, liber, n)
caesar_tfidfСнова визуализируем.
caesar_tfidf |>
arrange(-tf_idf) |>
group_by(liber) |>
slice_head(n = 10) |>
ungroup() |>
ggplot(aes(reorder_within(word, tf_idf, liber), tf_idf, fill = as.factor(liber))) +
geom_col(show.legend = F) +
labs(x = NULL, y = "tf-idf") +
facet_wrap(~liber, scales = "free", nrow = 2) +
scale_x_reordered() +
coord_flip() +
theme_light()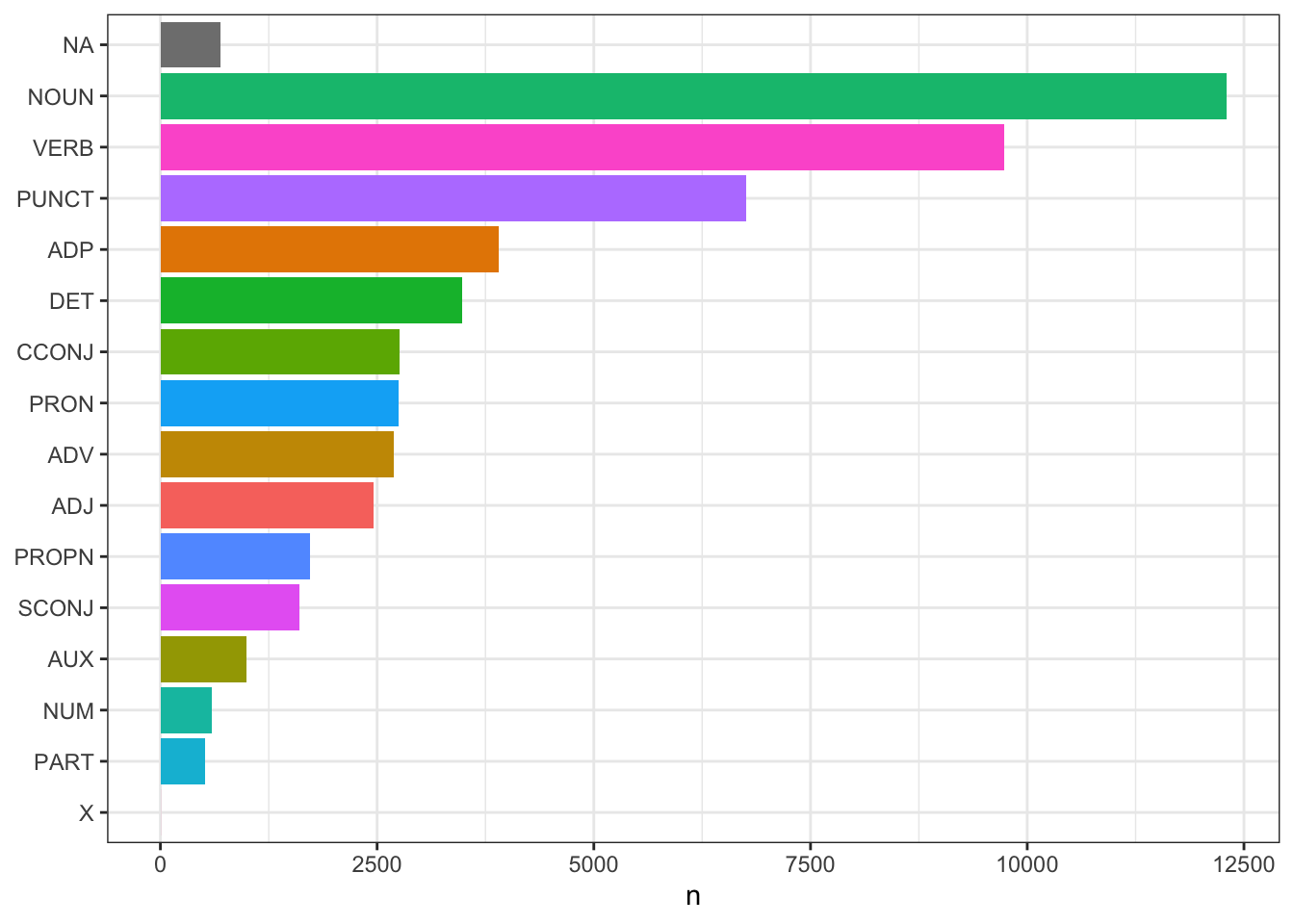
Заметим появление друидов в шестой книге, когда Цезарь добирается до Британии, и Квинта Цицерона – в пятой.
10.1.6 Сравнение при помощи диаграммы рассеяния
Столбиковая диаграмма – не единственный способ сравнить частотности слов. Еще один наглядный метод – это диаграмма рассеяния с относительными частотностями. Сначала “расширим” наш тиббл.
spread_freq <- caesar_tfidf |>
select(-n, -idf, -tf) |>
pivot_wider(names_from = liber, values_from = tf_idf,
values_fill = 0, names_prefix = "liber_")
spread_freqМожно визуализировать.
library(scales)
spread_freq |>
select(word, liber_1, liber_2) |>
filter(liber_1 > 0.0001 & liber_2 > 0.0001) |>
ggplot(aes(x = liber_1, y = liber_2)) +
geom_abline(color = "grey40", lty = 2) +
geom_jitter(alpha = 0.1, size = 2.5, width = 0.3,
height = 0.3, color = "darkblue") +
geom_text(aes(label = word), check_overlap = TRUE,
color = "grey30"
) +
scale_x_log10(labels = percent_format()) +
scale_y_log10(labels = percent_format()) +
theme(legend.position = "none") +
theme_minimal()
Как читать:
- ось X соответствует первой книге (liber_1), ось Y — второй;
- всё, что на линии, одинаково характерно для обеих книг, далеко от линии — характерно для одной;
- на самих осях ничего нет, т.к. мы отфильтровали нули.
Что можно заметить:
- первая книга: справа по оси X — haedui, provincia, rhenum, oratione, voluntate, gratia, iure. Это хорошо соответствует сюжету первой книги (дипломатия, переговорные формулы).
- вторая книга: вверху по оси Y — belgarum, oppidum, murus, cohortatus, conantes, latitudinem. Это типично для бельгийской кампании и осадно‑полевых описаний второй книги.
- характерный для двух книг военный словарь находится около диагонали: legiones, acies, milia, pila, signum, castra/iter и т.п.
Лемматизация латинского текста существенно улучшит картину.
10.2 Лемматизация и частеречная разметка
Лемматизация – приведение слов к начальной форме (лемме). Как правило, она проводится одновременно с частеречной разметкой (POS-tagging). Все это умеет делать UDPipe – обучаемый конвейер (trainable pipeline), для которого существует одноименный пакет в R.
Основным форматом файла для него является CoNLL-U. Файлы в таком формате хранятся в так называемых трибанках, то есть коллекциях уже размеченных текстов (название объясняется тем, что синтаксическая структура предложений представлена в них в виде древовидных графов). Файлы CoNLL-U используются для обучения нейросетей, но для большинства языков доступны хорошие предобученные модели, работать с которыми достаточно просто.
10.2.1 Udpipe
Пакет udpipe позволяет работать со множеством языков (всего 65), для многих из которых представлено несколько моделей, обученных на разных трибанках. Среди этих языков есть и латинский.
Прежде всего нужно выбрать и загрузить модель (список); в нашем случае это модель Perseus, но можно попробовать и другие доступные на сайте https://universaldependencies.org/.
Аннотировать лучше не разбитый на слова текст. Чтобы не потерять информацию о происхождении текста, добавим уникальный id к каждому параграфу.
caesar_id <- caesar |>
unite(id, c("liber", "cap"), sep = "_")
caesar_id# скачиваем модель в рабочую директорию
#udpipe_download_model(language = "latin-perseus")
# загружаем модель
latin_perseus <- udpipe_load_model(file = "latin-perseus-ud-2.5-191206.udpipe")
# аннотируем
caesar_annotate <- udpipe_annotate(latin_perseus, caesar_id$text, doc_id = caesar_id$id)Результат возвращается в формате CoNLL-U; это широко применяемый формат представления результат морфологического и синтаксического анализа текстов. Вот пример разбора предложения:
Cтроки слов содержат следующие поля:
ID: индекс слова, целое число, начиная с 1 для каждого нового предложения; может быть диапазоном токенов с несколькими словами.FORM: словоформа или знак препинания.LEMMA: Лемма или основа словоформы.UPOSTAG: тег части речи из универсального набора проекта UD, который создавался для того, чтобы аннотации разных языков были сравнимы между собой.XPOSTAG: тег части речи, который выбрали исследователи под конкретные нужды языкаFEATS: список морфологических характеристик.HEAD: идентификатор (номер) синтаксической вершины текущего токена. Если такой вершины нет, то ставят ноль (0).DEPREL: характер синтаксической зависимости.DEPS: Список вторичных зависимостей.MISC: любая другая аннотация.
Для работы данные удобнее трансформировать в прямоугольный формат.
caesar_pos <- caesar_annotate |>
as_tibble() |>
select(-paragraph_id)
caesar_pos 10.2.2 Обучение модели
Можно заметить, что модель Perseus 2.5 справилась не безупречно: все бельги оказались женского рода, а кельты и вовсе признаны глаголом. Есть ошибки в падежах и числах: например, “provinciae” в четвертом предложении, конечно, не именительный, а родительный падеж. Множество топонимов не опознано в качестве имен собственных.
Здесь есть два пути. Первый: пробовать другие модели, доступные в пакете udpipe. Например, для латыни это PROIEl, обученная не только на классических авторах, но и на Вульгате, или ITTB, обученная на сочинениях Фомы. Но если тексты в трибанках не очень похожи на ваш корпус, то это вряд ли сработает.
Второй путь - обучить модель самостоятельно. Например, для трибанка Perseus доступны более свежие версии (2.13 на момент написания этой главы) на GitHub.
Вот некоторые изменения:
- появилась метка
dep_relдля ablativus absolutus (advcl:abs); - исправлены аннотации для супина (
VerbForm=Conv,Aspect=Prosp), а также герундия и герундива (VerbForm=Part,Aspect=Prosp); - добавлен тип для местоимения (
PronType) и вид для глагола (Aspect) и др.
Инструкцию по обучению модели при помощи udpipe можно найти здесь (нужен VPN). Следуя этой инструкции и используя трибанк Perseus 2.13, мы обучили новую модель (это заняло около 8 часов на персональном компьютере), которую можно загрузить и использовать для аннотации.
Надо иметь в виду, что само по себе обновление трибанка еще не гарантирует того, что модель будет лучше справляться с парсингом: многое зависит от параметров обучения. В нашем случае, впрочем, некоторые улучшения есть: например, “provinciae” корректно опознано как родительный падеж. Но есть и потери: “fortissimi” в том же предложении выше - это nominativus pluralis, который ошибочно опознан как генитив единственного числа.
latin_perseus_new <- udpipe_load_model("../latin_model/la_perseus-2.13-20231115.udpipe")
caesar_annotate2 <- udpipe_annotate(latin_perseus_new, caesar_id$text, doc_id = caesar_id$id)
caesar_pos2 <- as_tibble(caesar_annotate2) |>
select(-paragraph_id)caesar_pos2Для многих задач достигнутой точности хватит, но есть способы ее повысить (часто за пределами R). Например, для латинского языка разработан пайплайн под названием LatinPipe, в 2024 г. победивший в конкурсе как лучший парсер для латинского языка. Это сложная конфигурация из различных нейросетей, которые учатся не на одном, а сразу на нескольких трибанках, что позволяет достичь большой точности. Мы обучили подобную модель и передали ей “Записки Цезаря”. Результат возвращается в формате CoNLL-U: прочитаем его в окружение и посмотрим, что получилось (скачать можно здесь).
caesar_pos3 <- udpipe_read_conllu("../files/bg_latinpipe.conllu") |>
select(-paragraph_id)
caesar_pos3Кельты признаны существительным, бельги мужского рода (в поле FEATS), а provinciae – генитив. Очень хорошо.
10.2.3 Лемматизация по API
Последние модели для лемматизации доступны здесь https://lindat.mff.cuni.cz/services/udpipe/ (нужен VPN). Можно загружать файлы вручную или через API.
Подробнее о лемматизации по API.
library(httr)
library(jsonlite)
# функция для лемматизации латинского текста
lemmatize_latin_text <- function(text, model = "latin-perseus-ud-2.15-241121") {
url <- "https://lindat.mff.cuni.cz/services/udpipe/api/process"
# Параметры запроса
params <- list(
model = model,
data = text,
tokenizer = "",
tagger = "",
parser = ""
)
# Отправка POST запроса
response <- POST(
url = url,
body = params,
encode = "form"
)
# Проверка статуса ответа
if (status_code(response) == 200) {
# Парсинг JSON ответа
result <- content(response, "parsed")
# Извлечение данных
if (!is.null(result$result)) {
return(result$result)
} else {
stop("Ошибка: результат не содержит данных")
}
} else {
stop(paste("Ошибка API:", status_code(response)))
}
}# пример использования
latin_text <- "Gallia est omnis divisa in partes tres, quarum unam incolunt Belgae, aliam Aquitani, tertiam qui ipsorum lingua Celtae, nostra Galli appellantur."
# лемматизация текста
result <- lemmatize_latin_text(latin_text)
cat(result)
# # generator = UDPipe 2, https://lindat.mff.cuni.cz/services/udpipe
# # udpipe_model = latin-perseus-ud-2.15-241121
# # udpipe_model_licence = CC BY-NC-SA
# # newdoc
# # newpar
# # sent_id = 1
# # text = Gallia est omnis divisa in partes tres, quarum unam incolunt Belgae, aliam Aquitani, tertiam qui ipsorum lingua Celtae, nostra Galli appellantur.
# 1 Gallia Gallia PROPN n-s---fn- Case=Nom|Gender=Fem|Number=Sing 4 nsubj:pass _ _
# 2 est sum AUX v3spia--- Aspect=Imp|Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin 4 aux:pass _ _
# 3 omnis omnis DET a-s---fn- Case=Acc|Gender=Fem|Number=Plur|PronType=Tot 1 det _ _
# 4 divisa divido VERB v-srppfn- Aspect=Perf|Case=Nom|Gender=Fem|Number=Sing|VerbForm=Part|Voice=Pass 0 root _ _
# 5 in in ADP r-------- _ 6 case _ _
# 6 partes pars NOUN n-p---fa- Case=Acc|Gender=Fem|Number=Plur 4 obl _ _
# 7 tres tres NUM C1|grn1|casM|gen2|vgr1 Case=Acc|Gender=Fem|Number=Plur|NumForm=Word|NumType=Card 6 nummod _ SpaceAfter=No
# 8 , , PUNCT u-------- _ 11 punct _ _
# 9 quarum qui PRON p-p---fg- Case=Gen|Gender=Fem|Number=Plur|PronType=Rel 10 nmod _ _
# 10 unam unus DET p-s---fa- Case=Acc|Gender=Fem|InflClass=LatPron|Number=Sing|NumType=Card|NumValue=1|PronType=Ind 11 obj _ _
# 11 incolunt incolo VERB v3ppia--- Aspect=Imp|Mood=Ind|Number=Plur|Person=3|Tense=Pres|VerbForm=Fin|Voice=Act 6 acl:relcl _ _
# 12 Belgae Belgae NOUN n-p---mn- Case=Nom|Gender=Masc|Number=Plur 11 nsubj _ SpaceAfter=No
# 13 , , PUNCT u-------- _ 15 punct _ _
# 14 aliam alius DET a-s---fa- Case=Acc|Gender=Fem|Number=Sing|PronType=Con 15 det _ _
# 15 Aquitani Aquitani NOUN n-p---mn- Case=Nom|Gender=Masc|Number=Plur 11 nsubj _ SpaceAfter=No
# 16 , , PUNCT u-------- _ 17 punct _ _
# 17 tertiam tertius ADJ a-s---fa- Case=Acc|Gender=Fem|Number=Sing|NumType=Ord 15 amod _ _
# 18 qui qui PRON p-p---mn- Case=Nom|Gender=Masc|Number=Plur|PronType=Rel 25 nsubj:pass _ _
# 19 ipsorum ipse DET p-p---mg- Case=Gen|Gender=Masc|Number=Plur|Person=3|PronType=Prs 20 nmod _ _
# 20 lingua lingua NOUN n-s---fb- Case=Abl|Gender=Fem|Number=Sing 21 obl _ _
# 21 Celtae Celta ADJ a-s---fg- Case=Gen|Gender=Fem|Number=Sing 25 xcomp _ SpaceAfter=No
# 22 , , PUNCT u-------- _ 21 punct _ _
# 23 nostra noster DET p-p---nn- Case=Abl|Gender=Fem|Number=Sing|Number[psor]=Plur|Person[psor]=1|Poss=Yes|PronType=Prs 24 det _ _
# 24 Galli Galli NOUN n-p---mn- Case=Nom|Gender=Masc|Number=Plur 25 nsubj:pass _ _
# 25 appellantur appello VERB v3ppip--- Aspect=Imp|Mood=Ind|Number=Plur|Person=3|Tense=Pres|VerbForm=Fin|Voice=Pass 15 acl:relcl _ SpaceAfter=No
# 26 . . PUNCT u-------- _ 4 punct _ SpaceAfter=NoСохраняем и парсим CoNLL-U как было показано выше.
write_lines(result, "test_conllu_caesar.txt")
udpipe_read_conllu("test_conllu_caesar.txt")10.2.4 Поле UPOS
Морфологическая аннотация, которую мы получили, дает возможность выбирать и группировать различные части речи. Например, местоимения.
caesar_pos3 |>
filter(upos == "PRON") |>
select(token, lemma, upos, xpos)Посчитать части речи можно так:
upos_counts <- caesar_pos3 |>
group_by(upos) |>
count() |>
arrange(-n)
upos_countsСтолбиковая диаграмма позволяет наглядно представить результаты подсчетов:
upos_counts |>
ggplot(aes(x = reorder(upos, n), y = n, fill = upos)) +
geom_bar(stat = "identity", show.legend = F) +
coord_flip() +
labs(x = NULL) +
theme_bw() 
Отберем наиболее частотные имена и имена собственные.
nouns <- caesar_pos3 |>
filter(upos %in% c("NOUN", "PROPN")) |>
count(lemma) |>
arrange(-n)
nounslibrary(wordcloud)
library(RColorBrewer)
pal <- RColorBrewer::brewer.pal(8, "Dark2")
wordcloud(nouns$lemma, nouns$n, colors = pal, max.words = 130)
10.2.5 Поле FEATS
Допустим, нам нужны не все местоимения, а лишь определенные их формы: например, относительные.
rel_pron <- caesar_pos3 |>
filter(str_detect(feats, "PronType=Rel")) |>
as_tibble()
rel_pron Посмотрим на некоторые местоимения в контексте.
rel_pron |>
filter(row_number() %in% c(1, 7)) |>
mutate(html_token = paste0("<mark>", token, "</mark>")) |>
mutate(html_sent = str_replace(sentence, token, html_token)) |>
pull(html_sent)[1] “Gallia est omnis divisa in partes tres, quarum unam incolunt Belgae, aliam Aquitani, tertiam qui ipsorum lingua Celtae, nostra Galli appellantur.”
[2] “Eorum una pars, quam Gallos obtinere dictum est, initium capit a flumine Rhodano, continetur Garumna flumine, Oceano, finibus Belgarum, attingit etiam ab Sequanis et Helvetiis flumen Rhenum, vergit ad septentriones.”
10.2.6 Поле XPOS
Чтение xpos требует сноровки: например причастие sublata там описывается так: v-srppfb-, где
v= verbum;-на месте лица;s= singularis;r= perfectum (неp, потому чтоp= praesens);p= participium;p= passivum;f= femininum;b= ablativus (неa, потому чтоa= accusativus).
Сравним с описанием личной формы глагола differunt v3ppia---:
v= verbum;3= 3. persona;p= pluralis;p= praesens;i= indicativus;a= activum;--на месте рода и падежа, т.к. форма личная.
Последнее “место” (Degree) у глаголов всегда свободно; в первой книге там стоит s (superlativus) лишь у florentissimis, что явно ошибка, потому что это не глагол.
Для удобства разобьем xpos на 9 столбцов.
caesar_pos3_sep <- caesar_pos3 |>
separate(xpos, into = c("POS", "xpos"), sep = 1) |>
separate(xpos, into = c("persona", "xpos"), sep = 1) |>
separate(xpos, into = c("numerus", "xpos"), sep = 1) |>
separate(xpos, into = c("tempus", "xpos"), sep = 1) |>
separate(xpos, into = c("modus", "xpos"), sep = 1) |>
separate(xpos, into = c("vox", "xpos"), sep = 1) |>
separate(xpos, into = c("genus", "xpos"), sep = 1) |>
separate(xpos, into = c("casus", "gradus"), sep = 1)
caesar_pos3_sepЭти столбцы тоже можно использовать для поиска конкретных признаков. Посмотрим, например, в каком числе и падеже чаще всего стоит относительное местоимения.
pron_rel_sum <- caesar_pos3_sep |>
filter(upos == "PRON") |>
filter(str_detect(feats, "PronType=Rel")) |>
group_by(numerus, casus) |>
summarise(n = n()) |>
arrange(-n)
pron_rel_sumДля удобства преобразуем сокращения.
pron_rel_sum <- pron_rel_sum |>
filter(casus != "-") |>
mutate(casus = case_when(casus == "n" ~ "nom",
casus == "g" ~ "gen",
casus == "d" ~ "dat",
casus == "a" ~ "acc",
casus == "b" ~ "abl")) |>
mutate(numerus = case_when(numerus == "s" ~ "sing",
numerus == "p" ~ "plur"))
pron_rel_sumФункция facet_wrap позволяет разбить график на две части на основании значения переменной numerus.
pron_rel_sum |>
ggplot(aes(casus, n, fill = casus)) +
geom_bar(stat = "identity", show.legend = FALSE) +
coord_flip() +
theme_light() +
facet_wrap(~numerus) +
labs(x = NULL, y = NULL, title = "Относительные местоимения в BG 1-7")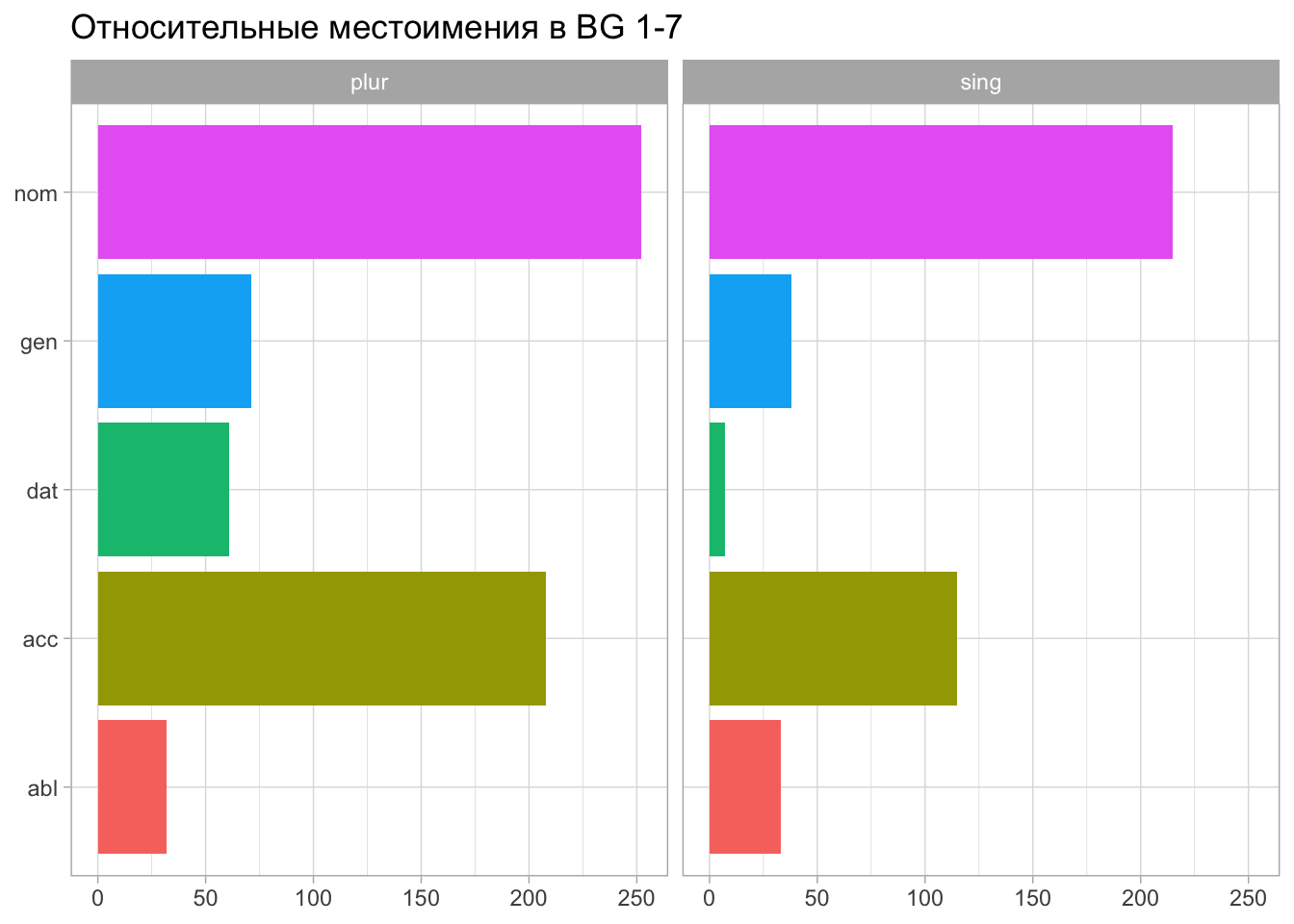
10.2.7 Поле DEP_REL
Аналогичным образом можно отбирать синтаксические признаки и их комбинации, а также визуализировать деревья зависимостей для отдельных предложений.
Дерево зависимостей – это направленный граф, который имеет единственную корневую вершину (сказуемое главного предложения) без входящих дуг (рёбер), при этом все остальные вершины имеют ровно одну входящую дугу. Иными словами, каждое слово зависит от другого, но только от одного. Это выглядит примерно так:
library(textplot)
sent <- caesar_pos3 |>
filter(doc_id == "doc1", sentence_id == 10)
sent |>
distinct(sentence) |>
pull(sentence) [1] "Apud Helvetios longe nobilissimus fuit et ditissimus Orgetorix."textplot_dependencyparser(sent, size = 3)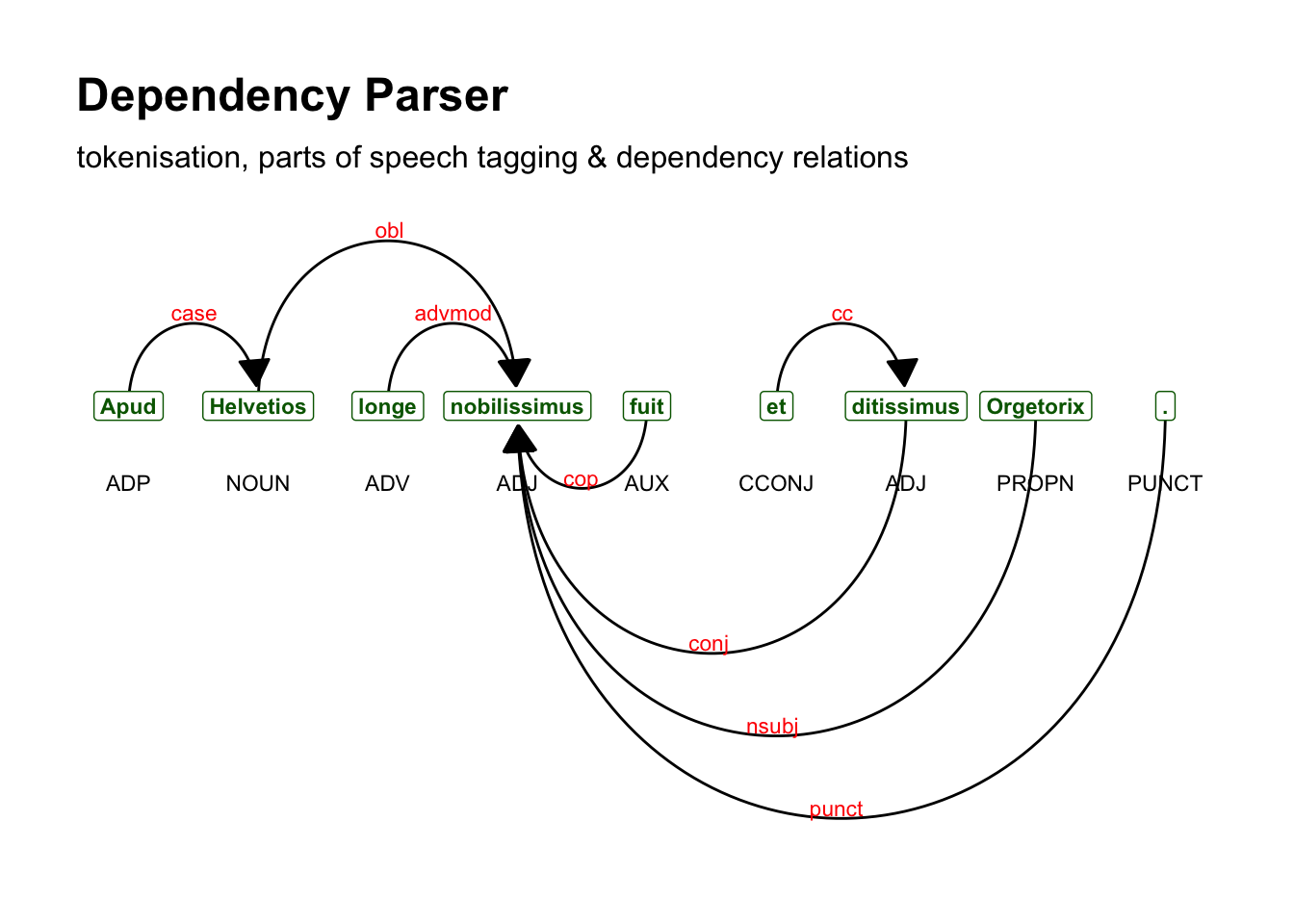
Прилагательные “nobilissiumus” и “ditissimus” верно опознаны в качестве именной части сказуемого при подлежащем “Оргеториг”. Информация, которая на графе представлена стрелками, хранится в таблице в полях token_id и head_token_id и dep_rel. Корень синтаксического дерева всегда имеет значение 0, то есть ни от чего не зависит.
sent |>
select(token_id, token, head_token_id, dep_rel)10.2.8 Сочетания признаков
Добудем все сложные предложения, в состав которых входят придаточные относительные (адноминальные).
# адноминальные предложения
acl_ids <- caesar_pos3 |>
filter(str_detect(dep_rel, "acl:relcl")) |>
unite(id, c("doc_id", "sentence_id")) |>
pull(id)acl <- caesar_pos3 |>
unite(id, c("doc_id", "sentence_id")) |>
filter(id %in% acl_ids) |>
as_tibble() |>
mutate(token_id = as.numeric(token_id),
head_token_id = as.numeric(head_token_id))
aclПосмотрим на одно из таких предложений, в котором проявилась характерная для Цезаря черта: повторять антецедент относительного местоимения в придаточном. Например, вместо “было два пути, которыми…” он говорит “было два пути, каковыми путями…”.
example_sentence <- acl |>
filter(id == "doc1_43") |>
select(-sentence, -deps, -misc) |>
relocate(dep_rel, .before = upos) |>
relocate(head_token_id, .before = upos)
example_sentenceТакие случаи можно попробовать выловить при помощи условия или нескольких условий, например достать такие относительные местоимения, сразу за которыми стоит их вершина:
out <- acl |>
filter(str_detect(feats, "PronType=Rel") &
dep_rel == "det" &
head_token_id == (token_id + 1)) |>
select(id, token_id, token, sentence) out |>
mutate(html_token = paste0("<mark>", token, "</mark>")) |>
mutate(html_sent = str_replace(sentence, token, html_token)) |>
pull(html_sent) |>
head(5)[1] “Erant omnino itinera duo, quibus itineribus domo exire possent:”
[2] “Omnibus rebus ad profectionem comparatis diem dicunt, qua die ad ripam Rhodani omnes conveniant.”
[3] “Ubi de eius adventu Helvetii certiores facti sunt, legatos ad eum mittunt nobilissimos civitatis, cuius legationis Nammeius et Verucloetius principem locum obtinebant, qui dicerent sibi esse in animo sine ullo maleficio iter per provinciam facere, propterea quod aliud iter haberent nullum:” [4] “Ita sive casu sive consilio deorum immortalium quae pars civitatis Helvetiae insignem calamitatem populo Romano intulerat, ea princeps poenam persolvit.”
[5] “cuius legationis Divico princeps fuit, qui bello Cassiano dux Helvetiorum fuerat.”
Так мы кое-что полезное поймали, но не все, потому что между местоимением и его антецедентом возможны другие слова (например, “каковыми опасными путями”). С другой стороны, есть и кое-что лишнее, а именно случаи инкорпорации антецедента в придаточное предложение (“quae pars …, ea” вместо “ea pars, quae…” ). В общем, условие можно дальше дорабатывать, но мы пока не будем этого делать.
10.3 Видео
10.4 Домашнее задание
По ссылке вы найдете датасет со сказками Салтыкова-Щедрина (в формате .Rdata). Вам необходимо аннотировать сказки, используя модель SynTagRus через пакет {udpipe} (версия модели 2.5).
После этого ответьте на вопросы по ссылке. Задание считается выполненным, если верные ответы даны на 3 из 5 вопросов.
Ошибки лемматизации и морфологического анализа игнорируйте.
Дедлайн: 28 ноября, 21-00.
Hvitfeldt, Emil, и Julia Silge. 2022. Supervised Machine Learning for Text Analysis in R. Taylor; Francis.
Jockers, Matthew L. 2014. Text Analysis with R for Students of Literature. Springer.
Savoy, Jacques. 2020. Machine Learning Methods for Stylometry. Springer.
Silge, Julia, и David Robinson. 2017. Text Mining with R. O’Reilly. http://www.tidytextmining.com.