Граф – это математический объект, и в этом уроке речь пойдет о том, как можно его описывать и анализировать. Данные для этого урока происходят из корпуса Dracor.
library(ggraph)
Loading required package: ggplot2
library(paletteer)library(igraph)
Attaching package: 'igraph'
The following objects are masked from 'package:stats':
decompose, spectrum
The following object is masked from 'package:base':
union
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ lubridate::%--%() masks igraph::%--%()
✖ dplyr::as_data_frame() masks tibble::as_data_frame(), igraph::as_data_frame()
✖ purrr::compose() masks igraph::compose()
✖ tidyr::crossing() masks igraph::crossing()
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
✖ purrr::simplify() masks igraph::simplify()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
20.1 О корпусе Dracor
DraCor — сокращение от drama corpora — это собрание размеченных по стандарту TEI драматических текстов. Здесь есть пьесы на французском, немецком, испанском, русском, итальянском, шведском, португальском (только Кальдерон) и английском (только Шекспир), а также совсем небольшие коллекции эльзасских, татарских и башкирских пьес.
Два крупных корпуса пьес в составе собрания — немецкий и русский — были собраны и поддерживаются создателями проекта DraCor. Остальные корпуса были взяты из сторонних проектов, а затем адаптированы для совместимости с функционалом DraCor. Подробнее об этом можно прочитать здесь.
На сайте проекта “Системный Блокъ” можно прочитать серию материалов о том, как возможности Dracor используются в литературоведении:
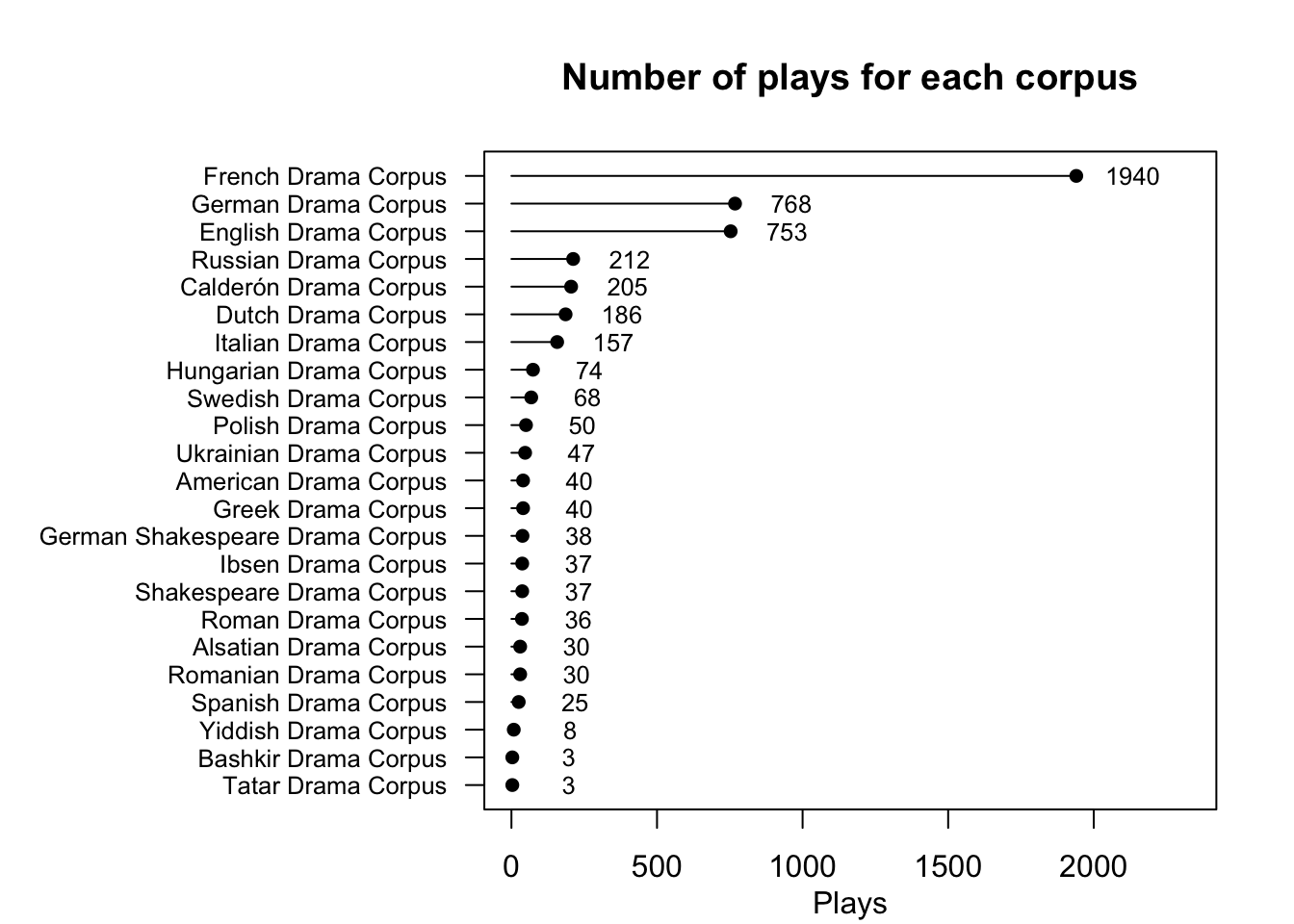
DraCor hosts 24 corpora comprising 4833 plays.
The last updated corpus was Argentinian Drama Corpus (2026-03-18 11:03:29.762).
Извлекаем метаданные.
meta <-get_dracor_meta() |>select(name, title, plays)meta
meta |>plot()
rus <-get_dracor("rus")summary(rus)
212 plays in Russian Drama Corpus
Corpus id: rus, repository: https://github.com/dracor-org/rusdracor
Description: Edited by Frank Fischer and Daniil Skorinkin. Features more than 200 Russian plays from the 1740s to the 1940s. For a corpus description and full credits please see the [README on GitHub](https://github.com/dracor-org/rusdracor).
Written years (range): 1747–1940
Premiere years (range): 1750–1992
Years of the first printing (range): 1747–1986
Тут хранится очень много всего: размер сети, плотность сети и т.д. Вот так, например, выглядят самые длинные пьесы в корпусе:
longest <- rus |>arrange(-wordCountText) |>select(firstAuthorName, title, wordCountText)
А так – самые густонаселенные.
biggest <- rus |>arrange(-size) |>select(firstAuthorName, title, size)
Подробнее см. презентацию Ивана Позднякова, разработчика DraCor Shiny App (https://shiny.dracor.org/).
В этой таблице хранятся сведения об имени и гендере персонажей, информация о том, является ли персонаж групповым (например, “народ”), в каком часле явлений он участвует и сколько у него реплик и слов. При желании это можно пересчитать на основе датафрейма с текстом пьесы:
godunov_df <-get_text_df(play ="pushkin-boris-godunov", corpus ="rus")godunov_df |>filter(who =="marina") |>count(scene_id)
Столбец wikidataId заполнен лишь для исторических лиц, например, для самого Годунова. По этому id можно искать другие пьесы с тем же историческим лицом.
boris_plays <-get_character_plays("Q170172")
Кроме того, мы видим такие метрики, как степень, взвешенная степень, различные показатели центральности. При желании их можно сразу забрать из таблицы, однако в этом уроке мы научимся их считать самостоятельно и привязывать в качестве атрибутов к узлам сети. Пока мы заберем из этой таблицы сведения о гендере и русскоязычное написание имени.
IGRAPH 4898d64 UNW- 79 327 --
+ attr: name (v/c), sex (v/c), weight (e/n)
+ edges from 4898d64 (vertex names):
[1] Воротынский--Шуйский
[2] Воротынский--Борис
[3] Воротынский--Бояре
[4] Шуйский --Борис
[5] Шуйский --Бояре
[6] Шуйский --Мальчик
[7] Шуйский --Афанасий Михайлович Пушкин
[8] Шуйский --Ксения
+ ... omitted several edges
20.4 Анализ узлов и ребер
20.4.1 Вес ребра
Веса ребер, как следует из технической документации к пакету, хранят информацию о том, сколько раз персонажи вместе появляются на сцене.
idx <-edge_attr(godunov)$weight >1E(godunov)[idx]
+ 9/327 edges from 4898d64 (vertex names):
[1] Воротынский--Шуйский Шуйский --Борис
[3] Борис --Бояре Борис --Феодор
[5] Борис --Басманов Григорий --Гаврила Пушкин
[7] Григорий --Курбский Григорий --Ляхи
[9] Ксения --Феодор
20.4.2 Взвешенная центральность
Важность (prominence) участника (актора, вершины, узла) определяется его положением внутри сети. Применительно к ненаправленным сетям говорят о центральности (центральный актор вовлечен в наибольшее количество связей, прямых или косвенных), а применительно к направленным – о престиже. Престижный актор характеризуется большим количеством входящих связей.
Мы уже умеем считать центральность по степени (degree centrality), которая определяется количеством связей: чем больше прямых связей, тем более важным является узел.
Борис Народ Григорий Феодор Бояре Басманов
29 26 25 23 21 15
# проверьте по таблице
С понятием веса ребра тесно связана взвешенная центральность по степени. В отличие от простой центральности, она учитывает вес связанных с узлом ребер.
Борис Григорий Народ Феодор Бояре Шуйский
35 28 26 25 23 16
Вот так, например, считается взвешенная центральность для Бориса Годунова:
# ребра, связанные с Годуновымidx <-incident(godunov, "Борис")# суммарный вес реберsum(E(godunov)[idx]$weight)
[1] 35
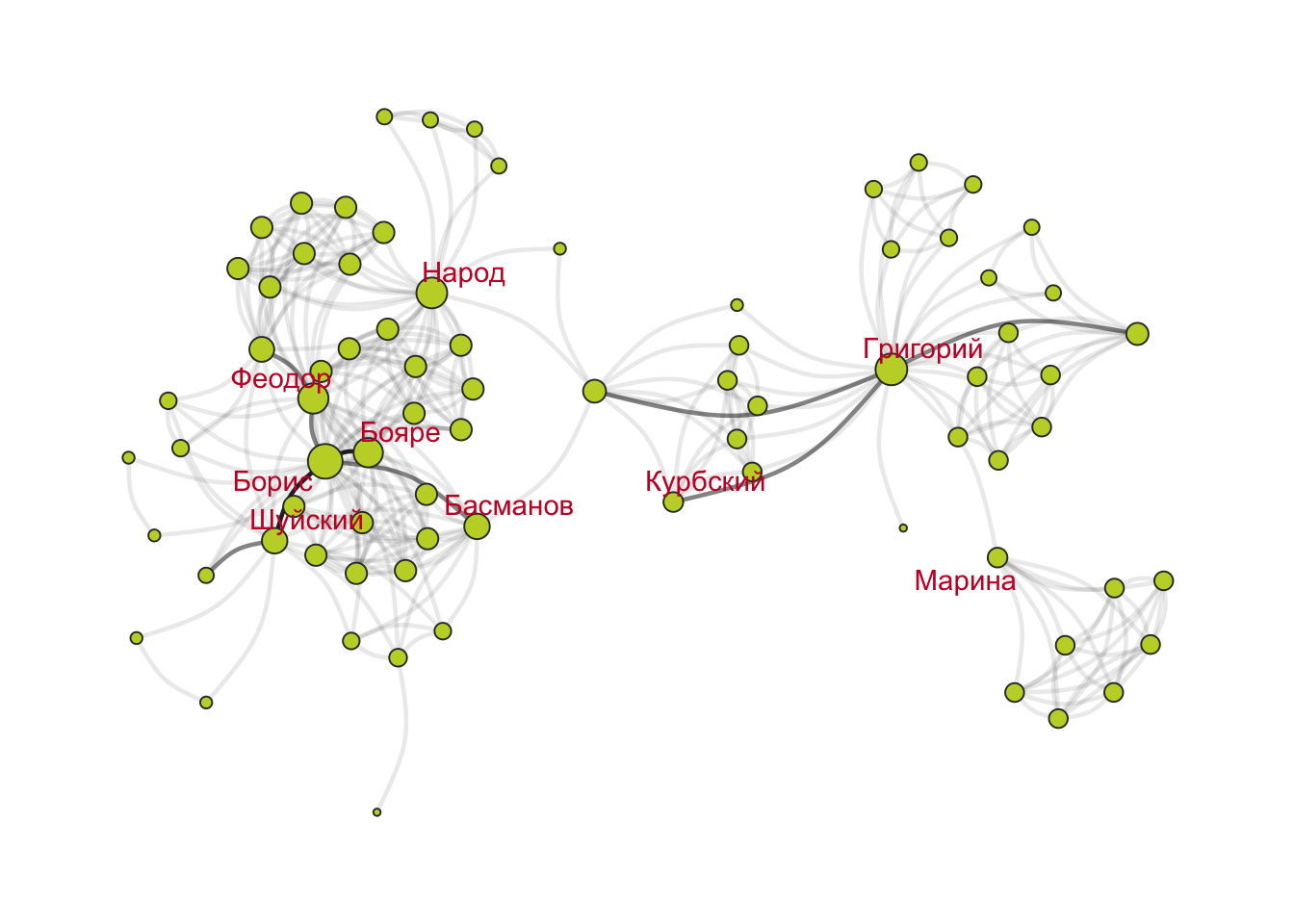
На графе веса ребер можно отразить за счет толщины и (или) прозрачности линии, а взвешенную центральность - за счет размера узла
cols <-paletteer_d("nbapalettes::hawks_statement")V(godunov)$wDegree <- wDegreeset.seed(22092024)ggraph(godunov, layout ="stress") +# здесь кодируем вес реберgeom_edge_arc(aes(alpha = weight),color = cols[3],width =0.8,show.legend =FALSE,strength =0.2) +# здесь взвешенная центральностьgeom_node_point(aes(size = wDegree),fill = cols[2],color ="grey20",show.legend =FALSE,shape =21) +# обратите внимание на фильтр!geom_node_text(aes(filter = (wDegree >15| name %in%c("Курбский", "Марина")),label = name),color = cols[1],repel =TRUE) +theme_graph()
20.4.3 Центральность по близости
Центральность по близости (closeness centrality) говорит о том, насколько близко узел расположен к другим узлам сети. Центральность по близости – это величина, обратная сумме расстояний от узла i до всех остальных узлов сети.
\[\frac{1}{\sum_{i\neq v}d_{vi}}\]
На заметку
Обратите внимание: в Dracor все метрики рассчитывались с использованием Python-пакета networkX. Имплементации расчетов сетевых метрик могут не совпадать.
Хрущов Карела Поэт Басманов Народ
0.3750000 0.3750000 0.3750000 0.3804878 0.4105263
Гаврила Пушкин
0.4193548
# проверьте по таблице
В пьесах эта метрика может означать, напрямую ли взаимодействуют с этим персонажем или нет. Например, в пьесе А. Н. Островского «Лес» персонаж Аксюша имеет невысокую взвешенную степень, но наибольшую степень близости. По сюжету, она находится в зависимом положении, в первую очередь от Гурмыжской (которая имеет наибольшую взвешенную степень), и это может означать что остальные персонажи взаимодействуют с ней напрямую, так как могут себе это позволить. – Источник.
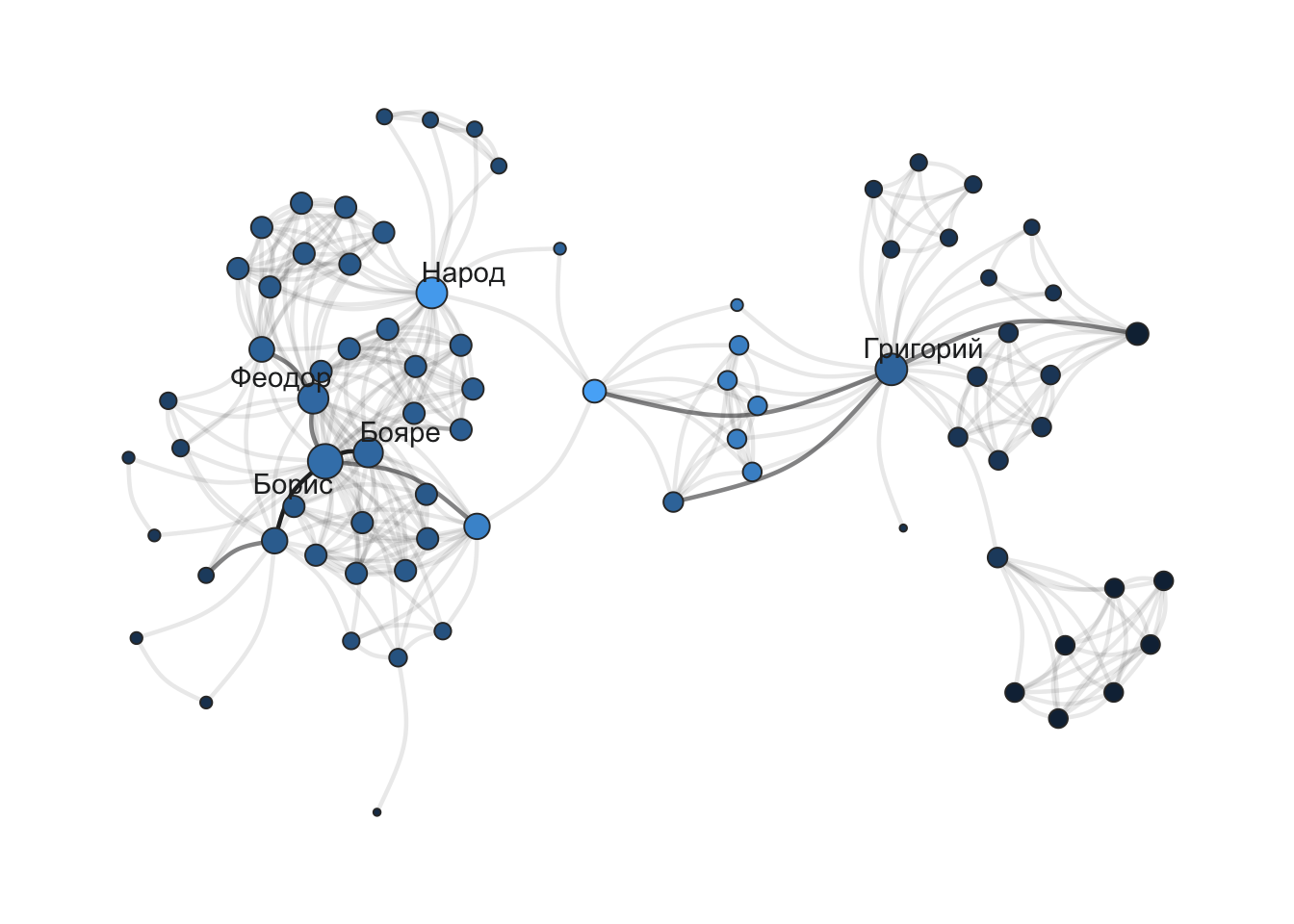
На графе закодируем этот атрибут цветом; температурную шкалу установим вручную.
Центральность по посредничеству (betweenness centrality) характеризует, насколько важную роль данный узел играет на пути “между” парами других узлов сети.
Борис Марина Басманов Народ Гаврила Пушкин
0.1211844 0.1655012 0.1892441 0.3944476 0.4937285
Григорий
0.4996670
V(godunov)$betweenness <- betweenness_centrality
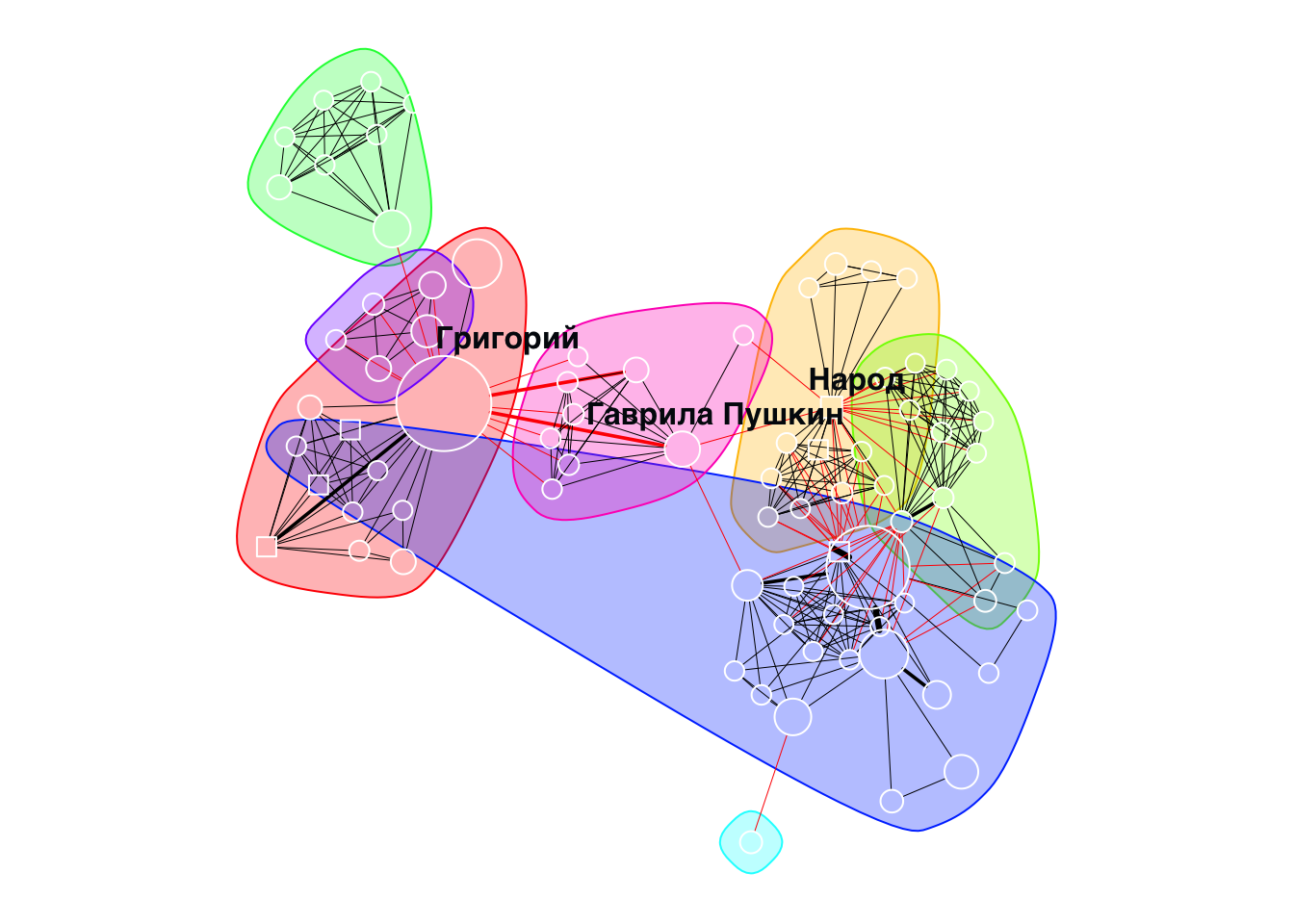
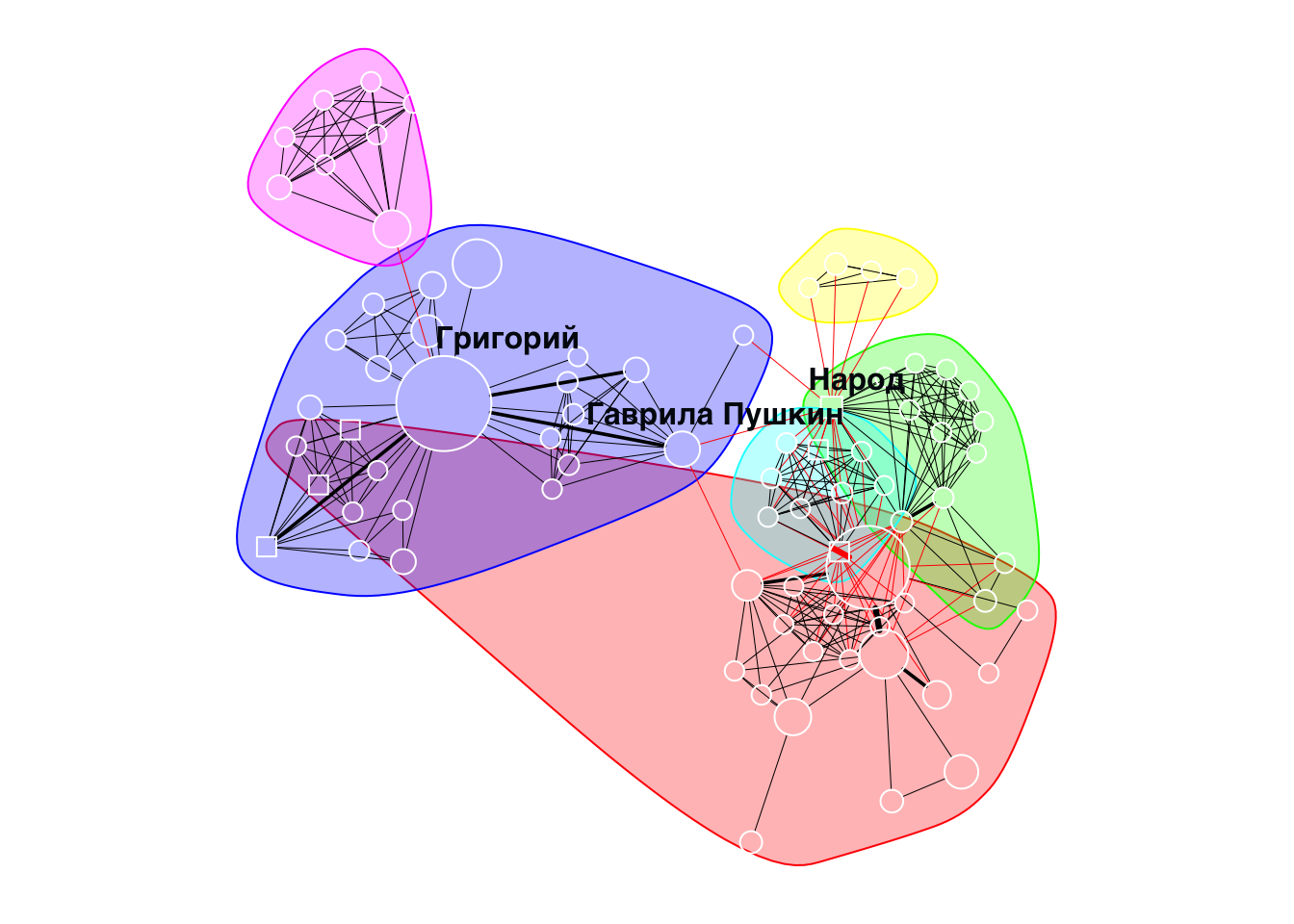
Хороший пример персонажа с высокой степенью посредничества в корпусе русской драмы — второстепенный персонаж Гаврила Пушкин из пьесы «Борис Годунов» А.С. Пушкина. …По сюжету, он является связующим персонажем между приближёнными Бориса и Григорием. При прочтении легко не заметить важность этого персонажа, однако на визуализации сети пьесы хорошо видно, что Гаврила связывает два кластера — персонажей в Москве и в Польше. – Источник.
20.4.5 Центральность по собственному вектору
Степень влиятельности (eigenvector centrality) показывает важность персонажа, учитывая влиятельность персонажей, с которыми взаимодействует данный персонаж. В пьесах эта метрика позволяет разделить действующих лиц на «центральных» и «периферийных».
Персонажи более значимы, если они взаимодействуют с персонажами важнее себя, и теряют свою значимость при контакте с менее важными действующими лицами. – Источник.
Чтобы посчитать eigenvector centrality, необходимо преобразовать граф в матрицу смежности (социоматрицу), в которой единицами отмечено наличие рёбер между персонажами, а нулями – их отсутствие. Вместо единиц в матрице могут быть указаны веса рёбер; в таком случае матрица будет взвешенной.
У таких матриц есть собственные векторы, то есть такие векторы, произведение которых на матрицу эквивалентно произведению числа на этот вектор.
\[\lambda \cdot C_e = A \cdot C_e,\] где
\(А\) — это матрица смежности;
\(λ\) — действительное число;
\(С_e\) — собственный вектор матрицы \(А\).
Элементы вектора \(C_e\) являются степенями влиятельности для каждой вершины. Это можно переписать для отдельных вершин так:
\[C_e(v_i)=\frac{1}{\lambda}\sum_{j=1}^{n}a_{ij} C_e(v_j),\] где
\(С_E(v_i)\) — это степень влиятельности вершины \(v_i\);
\(a_ij\) — элемент матрицы \(A\), расположенный в i-й строке и j-м столбце.
В такой записи видно, что на степень влиятельности вершины \(v_i\) влияют значения всех остальных вершин. Алгоритм расчета eigenvector centrality в последних версиях {igraph} немного отличается.
eigen <-eigen_centrality(godunov)$vectoreigen |>sort() |>tail()
Шуйский Басманов Народ Феодор Бояре Борис
0.4904924 0.5209880 0.5717644 0.7366067 0.7799440 1.0000000
Теперь мы можем перейти к характеристике графа в целом.
20.5 Централизация
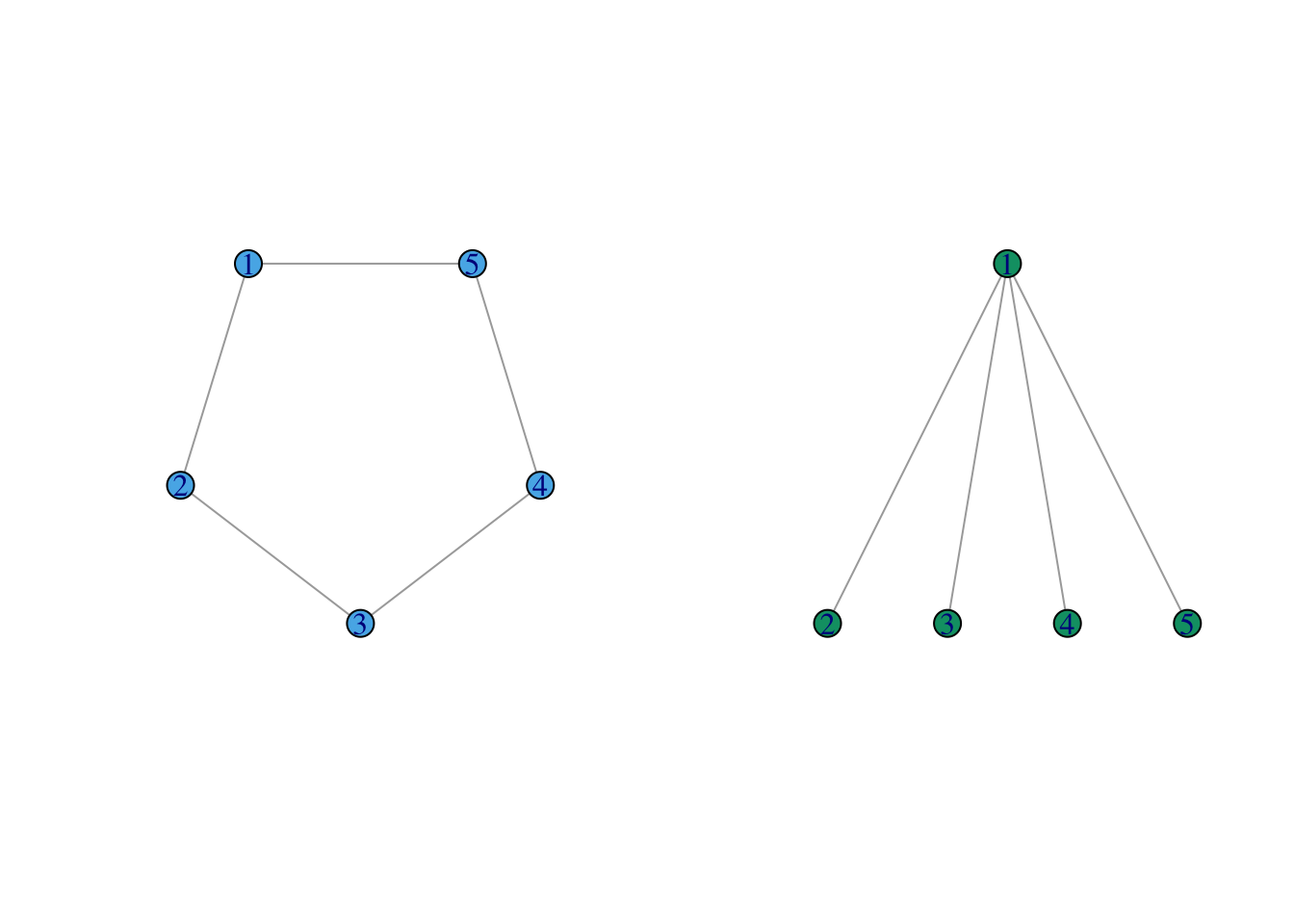
Рассмотрим два крайних случая: круговой граф и звездчатый граф.
Точка сочленения – это узел, при удалении которого увеличивается число компонент связности. Таким образом, они соединяют разные части сети. При их удалении акторы (узлы, вершины) не могут взаимодействовать друг с другом.
articulation_points(godunov)
+ 7/79 vertices, named, from 4898d64:
[1] Народ Патриарх Григорий Марина Гаврила Пушкин
[6] Борис Шуйский
Точки сочленения тесто связаны с центральностью по посредничеству.
V(godunov)[betweenness >0.025]
+ 16/79 vertices, named, from 4898d64:
[1] Шуйский Народ Борис Бояре
[5] Григорий Патриарх Феодор Pater Черниковский
[9] Гаврила Пушкин Поляк Хрущов Карела
[13] Марина Басманов Поэт Лях (Лес)
20.7 Клики
Многие сети состоят из относительно плотных подгрупп, которые соединены между собой менее крепкими связями. Один из способов взглянуть на подгруппы сети заключается в исследовании социальной сплочености (cohesion). Сплоченные подгруппы - это множество акторов, которые объединены между собой посредством многочисленных, сильных и прямых связей.
Клика – один из самых простых типов сплоченных подгрупп; это максимально полный подграф, т.е. подмножество узлов со всеми возможными связями между ними. Вопреки своему названию, функция clique_num() возвращает размер наибольшей клики:
clique_num(godunov)
[1] 11
На самом деле таких клик даже три. Узнаем, кто туда входит.
cliques(godunov, min=11)
[[1]]
+ 11/79 vertices, named, from 4898d64:
[1] Народ Ксения Феодор
[4] Нищий Стража Один из народа (Кремль)
[7] Другой (Кремль) Один из народа (Кремль) Другой (Кремль)
[10] Третий (Кремль) Мосальский
[[2]]
+ 11/79 vertices, named, from 4898d64:
[1] Борис Бояре Феодор Басманов Боярин Один Другой
[8] Третий Четвертый Пятый Шестой
[[3]]
+ 11/79 vertices, named, from 4898d64:
[1] Народ
[2] Борис
[3] Бояре
[4] Один из народа (Площадь перед собором в Москве)
[5] Другой (Площадь перед собором в Москве)
[6] Третий (Площадь перед собором в Москве)
[7] Четвертый (Площадь перед собором в Москве)
[8] Мальчишки
[9] Старуха
[10] Юродивый
+ ... omitted several vertices
Или, что то же самое:
largest_cliques(godunov)
Но клика – это очень строгое определение сплоченной группы. Например, чтобы подграф, состоящий из 11 вершин, считался кликой, нужно, чтобы между ними было проведено \((11 \times 10) / 2 = 21\) связей. Если хотя бы одно ребро отсутствует, то условие не выполняется. Такие клики просто очень редко встречаются.
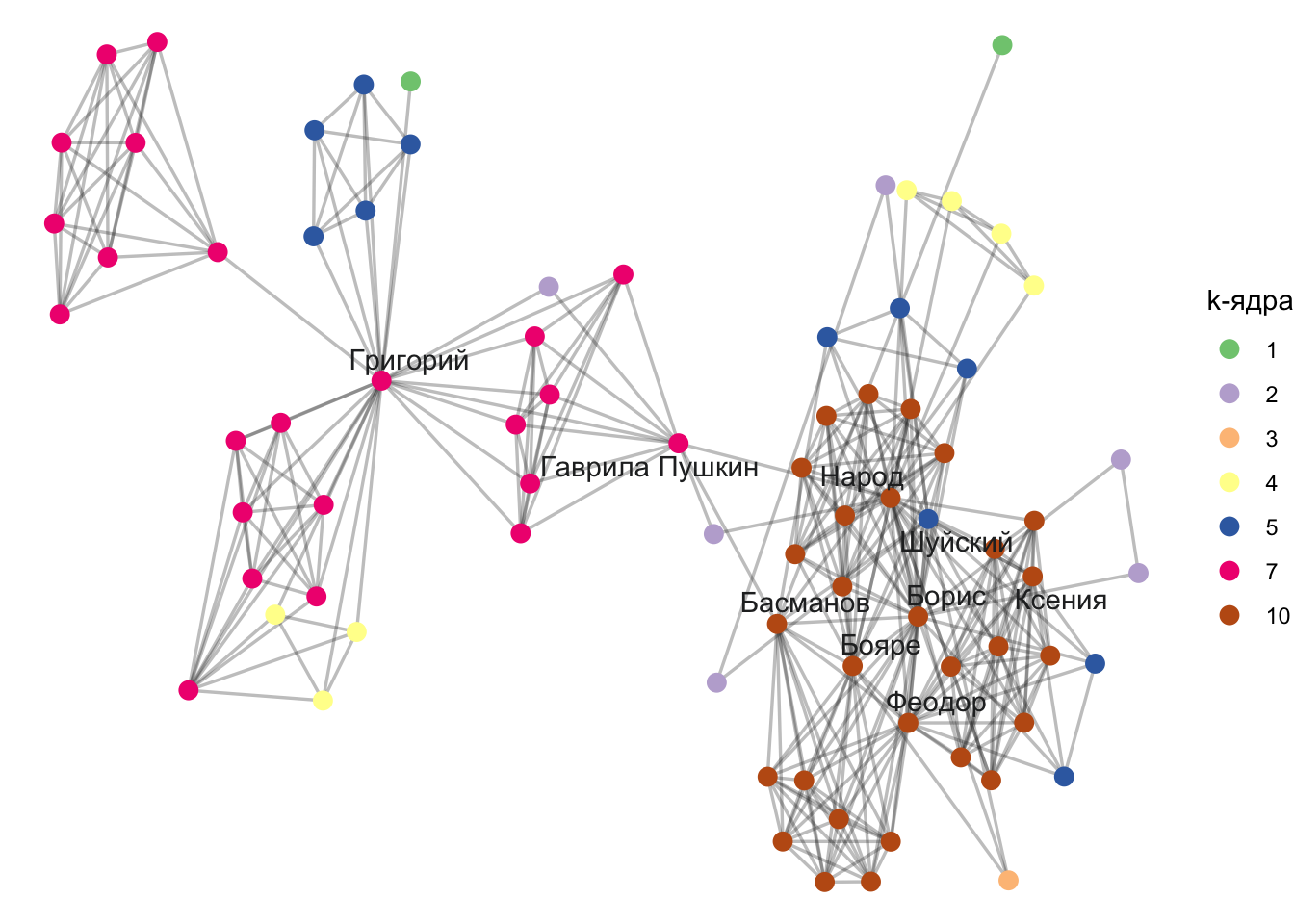
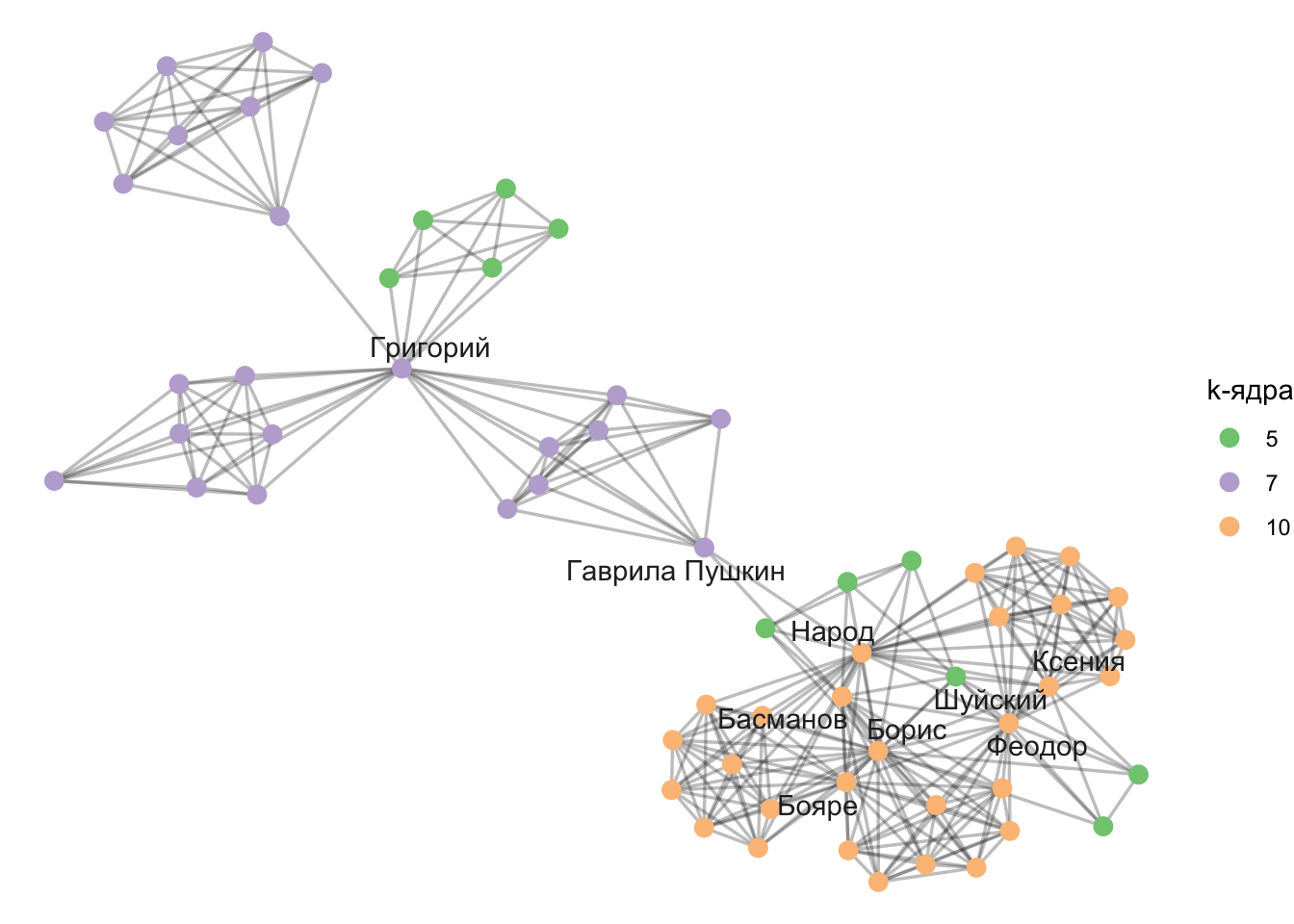
20.8 K-ядра
Популярным определением социальной сплоченности является k-ядро (k-core). Это максимальный подграф, в котором каждая вершина связана минимум с k другими вершинами этого же подграфа. K-ядра имеют множество преимуществ:
они вложены друг в друга (каждый участник 4-ядра является также участником 3-ядра и т.д.);
они не перекрываются;
их легко определить.
На заметку
Выражение 6-ядро читают как “ядро степени 6”.
Ядро степени k+1 является подграфом ядра степени k. Любой узел в ядре степени k имеет степень либо k, либо выше. При этом coreness узла определяется по ядру с наибольшей степенью, к которому они принадлежат.
Для определения k-ядерной структуры используется функция graph.coreness():
Воротынский Шуйский Один (Красная площадь)
3 5 4
Другой (Красная площадь) Третий (Красная площадь) Народ
4 4 10
Посчитаем количество вершин в ядрах.
table(cores_godunov)
cores_godunov
1 2 3 4 5 7 10
2 6 1 7 11 23 29
Для лучшей интерпретации k-ядерной структуры мы можем графически изобразить сеть, используя информацию о множестве k-ядер. Для начала добавим информацию о цвете к атрибутам узлов.
V(godunov)$core <- cores_godunov# убедимся, что добавился новый атрибутnames(vertex_attr(godunov))
При интерпретации важно помнить, что ядра являются вложенными. Чем выше степень ядра, тем больше узлы связаны между собой.
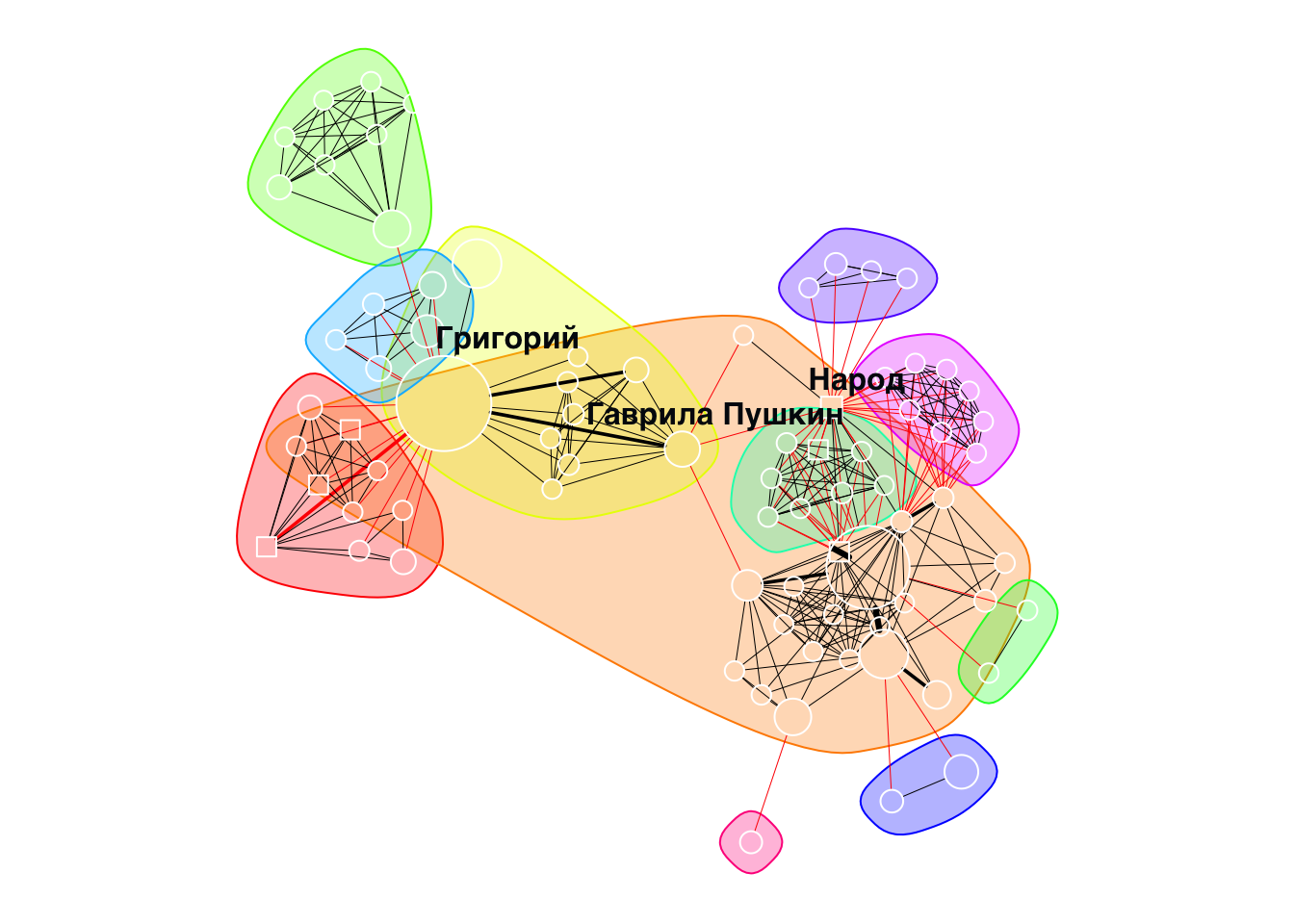
20.9 Модулярность
Модулярность — одна из мер структуры сетей или графов. Мера была разработана для измерения силы разбиения сети на модули (называемые группами, кластерами или сообществами). Сети с высокой модулярностью имеют плотные связи между узлами внутри модулей, но слабые связи между узлами в различных модулях.
Модулярность равна доле рёбер от общего числа рёбер, которые попадают в данные группы, минус ожидаемая доля рёбер, которые попали бы в те же группы, если бы они были распределены случайно.
Если все узлы принадлежат к одному классу, то модулярность равна нулю. Если разбиение на классы хорошее, то модулярность должна быть высокая. Мы можем проверить, хорошо ли группируются персонажи по гендеру. Для этого перекодируем гендер, так как функция modularity() принимает числовую переменную в качестве аргумента. Значение гендера 3 (unknown) в пьесе имеют групповые персонажи.
sex <-as.numeric(V(godunov)$sex)modularity(godunov, sex)
На заметку
При выделении сообществ в большинстве случаев наша задача – максимизировать модулярность.
Очевидно, что гендер не лучшим образом описывает деление персонажей “Годунова” на группы. Поищем другие сообщества.
20.10 Алгоритмы обнаружения сообществ
В пакете {igraph} реализовано множество алгоритмов обнаружения сообществ. Обычной практикой является применение нескольких алгоритмов и сравнение результатов.
У нас ненаправленная взвешенная сеть. Применим алгоритм “случайного блуждания”.
В этом задании вам надо провести анализ сетевых данных.
Данные для задания:
ВАРИАНТ 1: «Камер-фурьерский журнал» Ходасевича. Обратите внимание, что данные за каждый месяц разных лет там хранятся отдельно. Ваша задача — обобщить данные хотя бы за один год (но копировать код 12 раз не надо!). Для импорта используйте библиотеку {rgexf}. Для понимания материала можно посмотреть исследование Б.В. Орехова et al. по ссылке.
ВАРИАНТ 2: Персонажи «Войны и мира» Л. Н. Толстого. Здесь у вас на входе — размеченный xml, из которого вам надо самостоятельно собрать данные для сети. Подумайте, как можно операционализировать взаимодействие персонажей и посчитать веса для ребер. Минимум для анализа — один том (лучше больше, некоторыми связями можете на свое усмотрение пренебречь).
ВАРИАНТ 3: Любые другие данные, которые вы собрали и осмыслили самостоятельно в рамках индивидуальной исследовательской работы. Готовые датасеты с «Людьми в черном» на этом этапе нам не подойдут. В этом случае весь сбор данных должен быть подробно описан.
Критерии:
Импорт / сбор данных: корректный импорт, парсинг или сбор данных; используются циклы, фильтрация или агрегирование. Код или описание достаточны для воспроизведения.
Создан объект графа (iGraph или др.) и кратко описан (тип, размер, число компонент, плотность или др.)
Осмысленные атрибуты рёбер (например, вес, тип связи).
Атрибуты узлов включают хотя бы один показатель важности (степень, центральность и др.)
Подграф – выбран и обоснован метод (ego-граф, k-core, фильтрация и др.), пояснён процесс создания.
Граф и подграф визуализированы, визуализация информативна и хорошо читается.
Анализ сообществ: Использован хотя бы один алгоритм (Louvain, Walktrap и др.), результат визуализирован и описан.
Модулярность – вычислена и интерпретирована.
Анализ ключевых узлов / структур: найдены точки сочленения и клики (описано кратко).
Общее оформление: читаемость кода, описания, грамотность.
⏳Дедлайн: 21 марта 2025, 23:59.
Оценка 0-10.
📎Ссылку на опубликованный результат оставляйте в файле.