library(rvest)
library(tidyverse)
library(polite)9 Веб-скрапинг
Файлы html, как и XML, хранят данные в структурированном виде. Извлечь их позволяет пакет rvest. С его помощью мы добудем архив телеграм-канала Antibarbari HSE. Канал публичный, и Telegram дает возможность скачать архив в формате html при помощи кнопки export (эта функция может быть недоступна на MacOS, в этом случае стоит попробовать Telegram Lite). Данные (в формате zip) для этого урока можно забрать по ссылке.
Эта глава опирается в основом на второе издание книги R for Data Science Хадли Викхема.
9.1 Структура html
Документы html (HyperText Markup Language) имеют иерархическую структуру, состоящую из элементов. В каждом элементе есть открывающий тег (<tag>), опциональные атрибуты (id='first') и закрывающий тег (</tag>). Все, что находится между открывающим и закрывающим тегом, называется содержанием элемента.
Важнейшие теги, о которых стоит знать:
<html>(есть всегда), с двумя детьми (дочерними элементами):<head>и<body>;- элементы, отвечающие за структуру:
<h1>(заголовок),<section>,<p>(параграф),<ol>(упорядоченный список); - элементы, отвечающие за оформление:
<b>(bold),<i>(italics),<a>(ссылка).
Чтобы увидеть структуру веб-страницы, надо нажать правую кнопку мыши и выбрать View Source (это работает и для тех html, которые хранятся у вас на компьютере).
9.2 Каскадные таблицы стилей
У тегов могут быть именованные атрибуты; важнейшие из них – это id и class, которые в сочетании с CSS контролируют внешний вид страницы.
Пример css-правила (такие инфобоксы использованы в предыдущей версии курса):
.infobox {
padding: 1em 1em 1em 4em;
background: aliceblue 5px center/3em no-repeat;
color: black;
}Проще говоря, это инструкция, что делать с тем или иным элементом. Каждое правило CSS имеет две основные части — селектор и блок объявлений. Селектор, расположенный в левой части правила до знака {, определяет, на какие части документа (возможно, специально обозначенные) распространяется правило. Блок объявлений располагается в правой части правила. Он помещается в фигурные скобки, и, в свою очередь, состоит из одного или более объявлений, разделённых знаком «;».
Селекторы CSS полезны для скрапинга, потому что они помогают вычленить необходимые элементы. Это работает так:
pвыберет все элементы <p>.titleвыберет элементы с классом “title”#titleвыберет все элементы с атрибутом id=‘title’
Важно: если изменится структура страницы, откуда вы скрапили информацию, то и код придется переписывать.
9.3 Чтение html
Чтобы прочесть файл html, используем одноименную функцию (и пакет purrr, чтобы прочитать сразу три файла из архива).
antibarbari_files <- list.files("../files/antibarbari_2024-08-18", pattern = "html", full.names = TRUE)
antibarbari_archive <- map(antibarbari_files, read_html)9.4 Парсинг html: отдельные элементы
На следующем этапе важно понять, какие именно элементы нужны. Рассмотрим на примере одного сообщения. Для примера я сохраню этот элемент как небольшой отдельный html; rvest позволяет это сделать (но внутри двойных кавычек должны быть только одинарные):
example_html <- minimal_html("
<div class='message default clearfix' id='message83'>
<div class='pull_left userpic_wrap'>
<div class='userpic userpic2' style='width: 42px; height: 42px'>
<div class='initials' style='line-height: 42px'>
A
</div>
</div>
</div>
<div class='body'>
<div class='pull_right date details' title='19.05.2022 11:18:07 UTC+03:00'>
11:18
</div>
<div class='from_name'>
Antibarbari HSE
</div>
<div class='text'>
Этот пост открывает серию переложений из «Дайджеста платоновских идиом» Джеймса Ридделла (1823–1866), английского филолога-классика, чей научный путь был связан с Оксфордским университетом. По приглашению Бенджамина Джоветта он должен был подготовить к изданию «Апологию», «Критон», «Федон» и «Пир». Однако из этих четырех текстов вышла лишь «Апология» с предисловием и приложением в виде «Дайджеста» (ссылка) — уже после смерти автора. <br><br>«Дайджест» содержит 326 параграфов, посвященных грамматическим, синтаксическим и риторическим особенностям языка Платона. Знакомство с этим теоретическим материалом позволяет лучше почувствовать уникальный стиль философа и добиться большей точности при переводе. Ссылки на «Дайджест» могут быть уместны и в учебных комментариях к диалогам Платона. Предлагаемая здесь первая часть «Дайджеста» содержит «идиомы имен» и «идиомы артикля» (§§ 1–39).<br><a href='http://antibarbari.ru/2022/05/19/digest_1/'>http://antibarbari.ru/2022/05/19/digest_1/</a>
</div>
<div class='signature details'>
Olga Alieva
</div>
</div>
</div>
")Из всего этого мне может быть интересно id сообщения (\<div class='message default clearfix' id='message83'\>), текст сообщения (\<div class='text'\>), дата публикации (\<div class='pull_right date details' title='19.05.2022 11:18:07 UTC+03:00'\>), а также, если указан, автор сообщения (\<div class='signature details'\>). Извлекаем текст (для этого рекомендуется использовать функцию html_text2()):
example_html |>
html_element(".text") |>
html_text2()[1] "Этот пост открывает серию переложений из «Дайджеста платоновских идиом» Джеймса Ридделла (1823–1866), английского филолога-классика, чей научный путь был связан с Оксфордским университетом. По приглашению Бенджамина Джоветта он должен был подготовить к изданию «Апологию», «Критон», «Федон» и «Пир». Однако из этих четырех текстов вышла лишь «Апология» с предисловием и приложением в виде «Дайджеста» (ссылка) — уже после смерти автора.\n\n«Дайджест» содержит 326 параграфов, посвященных грамматическим, синтаксическим и риторическим особенностям языка Платона. Знакомство с этим теоретическим материалом позволяет лучше почувствовать уникальный стиль философа и добиться большей точности при переводе. Ссылки на «Дайджест» могут быть уместны и в учебных комментариях к диалогам Платона. Предлагаемая здесь первая часть «Дайджеста» содержит «идиомы имен» и «идиомы артикля» (§§ 1–39).\nhttp://antibarbari.ru/2022/05/19/digest_1/"В классе signature details есть пробел, достаточно на его месте поставить точку:
example_html |>
html_element(".signature.details") |>
html_text2()[1] "Olga Alieva"Осталось добыть дату и message id:
example_html |>
html_element(".pull_right.date.details") |>
html_attr("title")[1] "19.05.2022 11:18:07 UTC+03:00"example_html |>
html_element(".message.default.clearfix") |>
html_attr("id")[1] "message83"Теперь мы можем сохранить все нужные нам данные в таблицу.
tibble(id = example_html |>
html_element(".message.default.clearfix") |>
html_attr("id"),
date = example_html |>
html_element(".pull_right.date.details") |>
html_attr("title"),
signature = example_html |>
html_element(".signature.details") |>
html_text2(),
text = example_html |>
html_element(".text") |>
html_text2()
)9.5 Парсинг html: вложенные элементы
До сих пор наша задача упрощалась тем, что мы имели дело с игрушечным html для единственного сообщения. В настоящем html тег div повторяется на разных уровнях, и нам надо извлечь только такие div, которым соответствует определенный класс. Также не будем забывать, что архив выгрузился в виде трех html-файлов, так что понадобится наше знание итераций в purrr. Пока пробуем на одном из них:
archive_1 <- antibarbari_archive[[1]]
archive_1 |>
html_elements("div.message.default") |>
head(){xml_nodeset (6)}
[1] <div class="message default clearfix" id="message3">\n\n <div class= ...
[2] <div class="message default clearfix" id="message5">\n\n <div class= ...
[3] <div class="message default clearfix" id="message6">\n\n <div class= ...
[4] <div class="message default clearfix" id="message7">\n\n <div class= ...
[5] <div class="message default clearfix" id="message8">\n\n <div class= ...
[6] <div class="message default clearfix" id="message9">\n\n <div class= ...Уже из этого набора узлов можем доставать все остальное.
archive_1_tbl <- tibble(
id = archive_1 |>
html_elements("div.message.default") |>
html_attr("id"),
date = archive_1 |>
html_elements("div.message.default") |>
html_element(".pull_right.date.details") |>
html_attr("title"),
signature = archive_1 |>
html_elements("div.message.default") |>
html_element(".signature.details") |>
html_text2(),
text = archive_1 |>
html_elements("div.message.default") |>
html_element(".text") |>
html_text2()
)
archive_1_tblОбратите внимание, что мы сначала извлекаем нужные элементы при помощи html_elements(), а потом применяем к каждому из них html_element(). Это гарантирует, что в каждом столбце нашей таблицы равное число наблюдений.
Как вы уже поняли, теперь нам надо проделать то же самое для двух других файлов из архива антиварваров, а значит пришло время превратить наш код в функцию.
scrape_antibarbari <- function(html_file){
messages_tbl <- tibble(
id = html_file |>
html_elements("div.message.default") |>
html_attr("id"),
date = html_file |>
html_elements("div.message.default") |>
html_element(".pull_right.date.details") |>
html_attr("title"),
signature = html_file |>
html_elements("div.message.default") |>
html_element(".signature.details") |>
html_text2(),
text = html_file |>
html_elements("div.message.default") |>
html_element(".text") |>
html_text2()
)
messages_tbl
}
messages_tbl <- map_df(antibarbari_archive, scrape_antibarbari)Вот что у нас получилось.
messages_tbl9.6 Разведывательный анализ
Создатели канала не сразу разрешили подписывать посты, поэтому для первых нескольких десятков подписи не будет. Кроме того, в некоторых постах только фото, для них в столбце text – NA, их можно сразу отсеять.
messages_tbl <- messages_tbl |>
filter(!is.na(text))
messages_tblТакже преобразуем столбец, в котором хранится дата и время. Разделим его на два и выясним, в какое время и день недели чаще всего публикуются сообщения.
messages_tbl2 <- messages_tbl |>
separate(date, into = c("date", "time", NA), sep = " ") |>
mutate(date = dmy(date),
time = hms(time)) |>
mutate(year = year(date),
month = month(date, label = TRUE),
wday = wday(date, label = TRUE),
hour = hour(time),
length = str_count(text, " ") + 1) |>
mutate(wday = factor(wday, levels = c("Sun", "Sat", "Fri", "Thu", "Wed", "Tue", "Mon")))
messages_tbl2summary1 <- messages_tbl2 |>
group_by(year, month) |>
summarise(n = n())
summary1summary2 <- messages_tbl2 |>
group_by(year, hour) |>
summarise(n = n()) |>
mutate(hour = case_when(hour == 0 ~ 24,
.default = hour))
summary2summary3 <- messages_tbl2 |>
group_by(wday) |>
summarise(n = n())
summary3library(gridExtra)
library(grid)
library(paletteer)
cols <- paletteer_d("khroma::okabeitoblack")
p1 <- summary1 |>
ggplot(aes(month, n, color = as.factor(year), group = year)) +
geom_line(show.legend = FALSE, linewidth = 1.2, alpha = 0.8) +
labs(title = "Число постов в месяц") +
theme(legend.title = element_blank(),
legend.position = c(0.8, 0.3),
title = element_text(face="italic")) +
labs(x = NULL, y = NULL) +
scale_color_manual(values = cols[1:3])
p2 <- summary2 |>
ggplot(aes(hour, n, color = as.factor(year), group = year)) +
geom_line(linewidth = 1.2, alpha = 0.8) +
scale_x_continuous(breaks = seq(1,24,1)) +
labs(x = NULL, y = NULL, title = "Время публикации поста") +
theme(legend.title = element_blank(),
legend.position = "left",
axis.text.y = element_blank(),
axis.ticks.y = element_blank(),
title = element_text(face="italic")
) +
coord_polar(start = 0) +
scale_color_manual(values = cols[1:3])
p3 <- summary3 |>
ggplot(aes(wday, n, fill = wday)) +
geom_bar(stat = "identity",
show.legend = FALSE) +
coord_flip() +
labs(x = NULL, y = NULL, title = "Публикации по дням недели") +
scale_fill_manual(values = cols) +
theme(title = element_text(face="italic"))
p4 <- messages_tbl2 |>
ggplot(aes(as.factor(year), length, fill = as.factor(year))) +
geom_boxplot(show.legend = FALSE) +
labs(title = "Длина поста по годам") +
labs(x = NULL, y = NULL) +
scale_fill_manual(values = cols[1:3]) +
theme(title = element_text(face="italic"))
grid.arrange(p1, p2, p3, p4, nrow = 2,
top = textGrob("Телеграм-канал Antibarbari HSE",
gp=gpar(fontsize=16)),
bottom = textGrob("@Rantiquity",
gp = gpar(fontface = 3, fontsize = 9), hjust = 1, x = 1)) 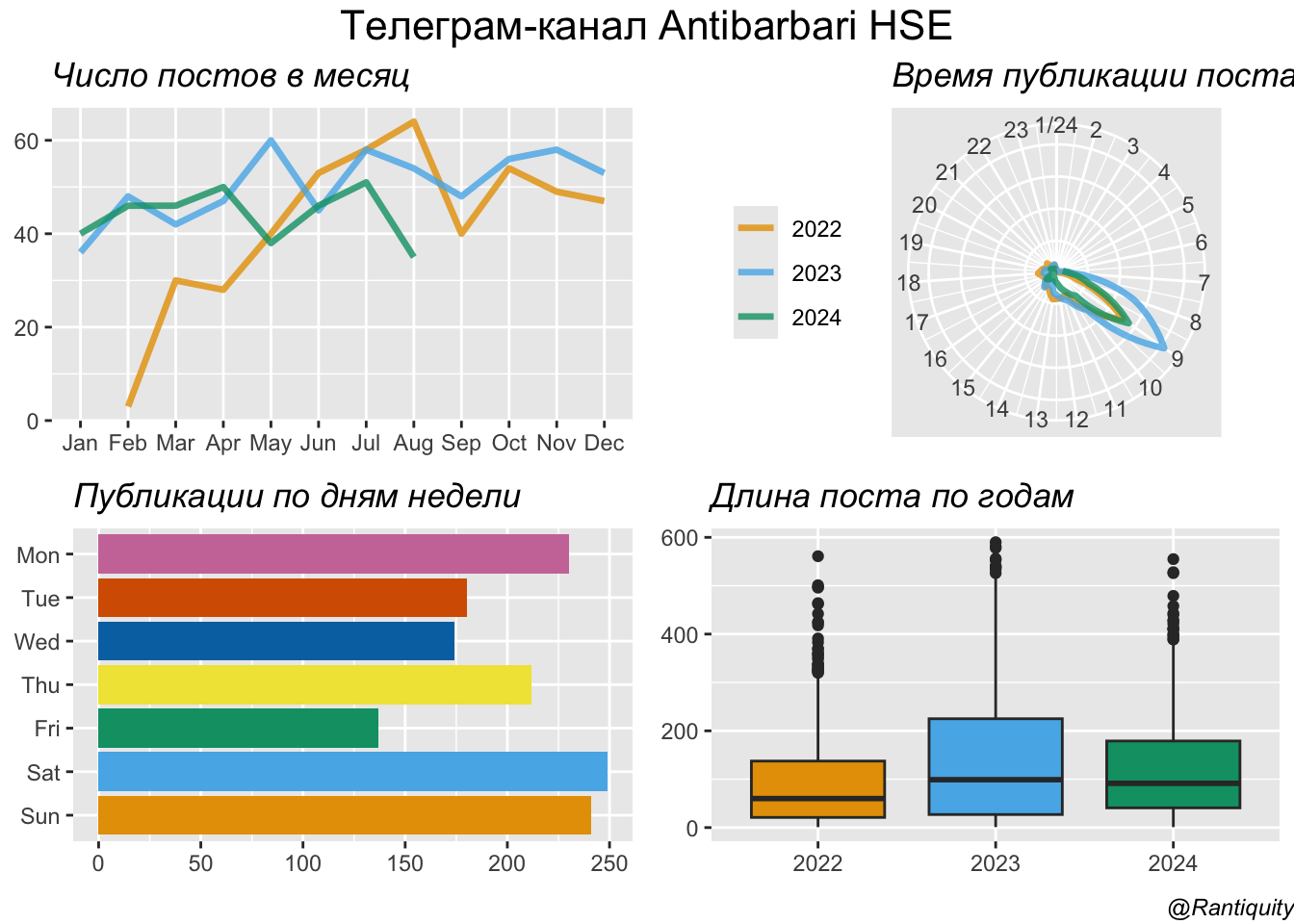
9.7 Html таблицы
Если вам повезет, то ваши данные уже будут храниться в HTML-таблице, и их можно будет просто считать из этой таблицы. Распознать таблицу в браузере обычно несложно: она имеет прямоугольную структуру из строк и столбцов, и ее можно скопировать и вставить в такой инструмент, как Excel.
Таблицы HTML строятся из четырех основных элементов: <table>, <tr> (строка таблицы), <th> (заголовок таблицы) и <td> (данные таблицы). Мы достанем программу курса “Количественные методы в гуманитарных науках: критическое введение” (2023/2024).
html <- read_html("http://criticaldh.ru/program/")
my_table <- html |>
html_table() |>
pluck(1)
my_table9.8 Selector Gadget
Многие тексты доступны на сайте <wikisource.org>. Попробуем извлечь латинский текст “Записок о Галльской войне” Цезаря: он пригодится нам в следующем уроке.
url <- "https://la.wikisource.org/wiki/Commentarii_de_bello_Gallico"
html = read_html(url)Для того, чтобы справиться с такой страницей, пригодится Selector Gadget (расширение для Chrome). Вот тут можно посмотреть короткое видео, как его установить. При помощи селектора выбираем нужные уровни.
toc <- html |>
html_elements("#mw-content-text li")
toc{xml_nodeset (8)}
[1] <li><a href="/wiki/Commentarii_de_bello_Gallico/Liber_I" title="Commentar ...
[2] <li><a href="/wiki/Commentarii_de_bello_Gallico/Liber_II" title="Commenta ...
[3] <li><a href="/wiki/Commentarii_de_bello_Gallico/Liber_III" title="Comment ...
[4] <li><a href="/wiki/Commentarii_de_bello_Gallico/Liber_IV" title="Commenta ...
[5] <li><a href="/wiki/Commentarii_de_bello_Gallico/Liber_V" title="Commentar ...
[6] <li><a href="/wiki/Commentarii_de_bello_Gallico/Liber_VI" title="Commenta ...
[7] <li><a href="/wiki/Commentarii_de_bello_Gallico/Liber_VII" title="Comment ...
[8] <li><a href="/wiki/Commentarii_de_bello_Gallico/Liber_VIII" title="Commen ...Извлекаем путь и имя файла для web-страниц.
libri <- tibble(
title = toc |>
html_text2(),
href = toc |>
html_element("a") |>
html_attr("href")
)
libriТеперь добавляем протокол доступа и доменное имя для каждой страницы.
libri <- libri |>
mutate(link = str_c("https://la.wikisource.org", href)) |>
select(-href)
libriДальше необходимо достать текст для каждой книги. Потренируемся на одной. Снова привлекаем Selector Gadget для составления правила.
urls <- libri |>
pull(link)
text <- read_html(urls[1]) |>
html_elements(".mw-heading3+ p") |>
html_text2()
text[1][1] "Gallia est omnis dīvīsa in partēs trēs, quārum ūnam incolunt Belgae, aliam Aquītānī, tertiam quī ipsōrum linguā Celtae, nostrā Gallī appellantur. Hī omnēs linguā, īnstitūtīs, lēgibus inter sē differunt. Gallōs ab Aquītānīs Garumna flūmen, ā Belgīs Mātrona et Sēquana dīvidit. Hōrum omnium fortissimī sunt Belgae, proptereā quod ā cultū atque hūmānitāte prōvinciae longissimē absunt, minimēque ad eōs mercātōrēs saepe commeant atque ea quae ad effēminandōs animōs pertinent important, proximīque sunt Germānīs, quī trāns Rhēnum incolunt, quibuscum continenter bellum gerunt. Quā dē causā Helvētiī quoque reliquōs Gallōs virtūte praecēdunt, quod fere cotīdiānīs proeliīs cum Germānīs contendunt, cum aut suīs fīnibus eōs prohibent aut ipsī in eōrum fīnibus bellum gerunt. Eōrum ūna, pars, quam Gallōs obtinēre dictum est, initium capit ā flūmine Rhodano, continētur Garumna flūmine, Ōceanō, fīnibus Belgārum, attingit etiam ab Sēquanīs et Helvētiīs flūmen Rhēnum, vergit ad septentriōnēs. Belgae ab extrēmīs Galliae fīnibus oriuntur, pertinent ad īnferiōrem partem flūminis Rhēnī, spectant in septentriōnem et orientem sōlem. Aquītānia ā Garumnā flūmine ad Pȳrēnaeōs montēs et eam partem Ōceanī quae est ad Hispāniam pertinet; spectat inter occāsum sōlis et septentriōnēs."Убедившись, что параграфы извлечены верно, обобщаем: пишем функцию для извлечения текстов и применяем ее ко всем книгам.
get_text <- function(url) {
Sys.sleep(3)
res = tibble(
liber = str_extract(url, "Liber_.+$"),
text = read_html(url) |>
html_elements(".mw-heading3+ p") |>
html_text2())
return(res)
}Это займет некоторое время.
libri_text <- map_df(urls, get_text)Соединим две таблицы.
caesar <- libri_text |>
group_by(liber) |>
mutate(cap = row_number(), .after = liber)
caesarСохраним подготовленный датасет для дальнейшего анализа.
save(caesar, file = "../data/caesar.Rdata")9.9 Сетевая вежливость
Когда вы работаете с веб-сайтами и автоматизированно загружаете множество страниц, важно:
- не перегружать сервер (быстрые, частые запросы могут быть расценены как атака или приведут к бану).
- соблюдать правила robots.txt — например, некоторые страницы могут быть закрыты для парсинга ботами.
- уважать сайт: добавлять задержки между запросами.
polite помогает автоматизировать соблюдение этих правил:
bow()проверяет robots.txt и заводит “виртуальный браузер”, который автоматически подставляет правильные технические детали при каждом запросе,nod()— готовит переход к дополнительной ссылке с сохранением контекста.scrape()— скачивает html-страницу, после проверки доступа.
# раскланиваемся
url <- "https://la.wikisource.org/wiki/Commentarii_de_bello_Gallico"
session <- bow(url)
# загружаем HTML главной страницы раздела с помощью polite
html <- scrape(session)После этого с помощью Selector Gadget выбираем нужные элементы оглавления, как раньше.
toc <- html |>
html_elements("#mw-content-text li")
toc{xml_nodeset (8)}
[1] <li><a href="/wiki/Commentarii_de_bello_Gallico/Liber_I" title="Commentar ...
[2] <li><a href="/wiki/Commentarii_de_bello_Gallico/Liber_II" title="Commenta ...
[3] <li><a href="/wiki/Commentarii_de_bello_Gallico/Liber_III" title="Comment ...
[4] <li><a href="/wiki/Commentarii_de_bello_Gallico/Liber_IV" title="Commenta ...
[5] <li><a href="/wiki/Commentarii_de_bello_Gallico/Liber_V" title="Commentar ...
[6] <li><a href="/wiki/Commentarii_de_bello_Gallico/Liber_VI" title="Commenta ...
[7] <li><a href="/wiki/Commentarii_de_bello_Gallico/Liber_VII" title="Comment ...
[8] <li><a href="/wiki/Commentarii_de_bello_Gallico/Liber_VIII" title="Commen ...Получив список ссылок, используем функцию для аккуратного скачивания и парсинга текста с задержками.
# раскланиваемся перед каждой страницей
get_text_polite <- function(url) {
bow_obj <- bow(url)
html_page <- scrape(bow_obj)
res = tibble(
liber = str_extract(url, "Liber_.+$"),
text = html_page |>
html_elements(".mw-heading3+ p") |>
html_text2())
return(res)
}Получаем тексты ко всем главам с помощью map().
# polite автоматически добавляет рекомендованную паузу между запросами
libri_text <- map_df(urls, get_text_polite)Итого:
bow(url)— создаёт аккуратную сессию с соблюдением robots.txt.scrape()— загружает страницу, только если это позволено.- В функции
get_text_politeкаждому URL соответствует свояbow()-сессия. Такой подход снижает риск блокировки.
9.10 Видео
9.11 Домашнее задание
🔗 Задание в Classroom: https://classroom.github.com/a/svdMrfyd
⌛ Дедлайн: 23/11, время 23:59
✅ Оценка 0/1
По ссылке вы найдете пустой репозиторий. Вам надо самостоятельно запарсить любой сайт и положить туда файл с кодом. Если вы парсите локальную html-страницу (например, архив какого-то канала), ее следует загрузить в репозиторий вместе с кодом.
Задание считается выполненным, если:
Не обязательно собирать сотни ссылок, их может быть 10-15, но я должна видеть, что вы освоили материал, то есть не применяете копипасту.
Какие это могут быть страницы:
- коллекции текстов: Викитека, lib.ru, др. Кроме русского, можете взять любой знакомый вам европейский язык, который использует латиницу (английский, французский, немецкий, испанский, итальянский);
- онлайн-издания, особенно образовательные или просветительские;
- интернет-энциклопедии, в т.ч. Википедия, Новая философская энциклопедия и др. С НЭФ мы немного поработали, но статьи оттуда не извлекали, так что ее тоже можно;
- сайты организаций: университетов, библиотек, музеев и т.д.;
- научные журналы, и т.д.