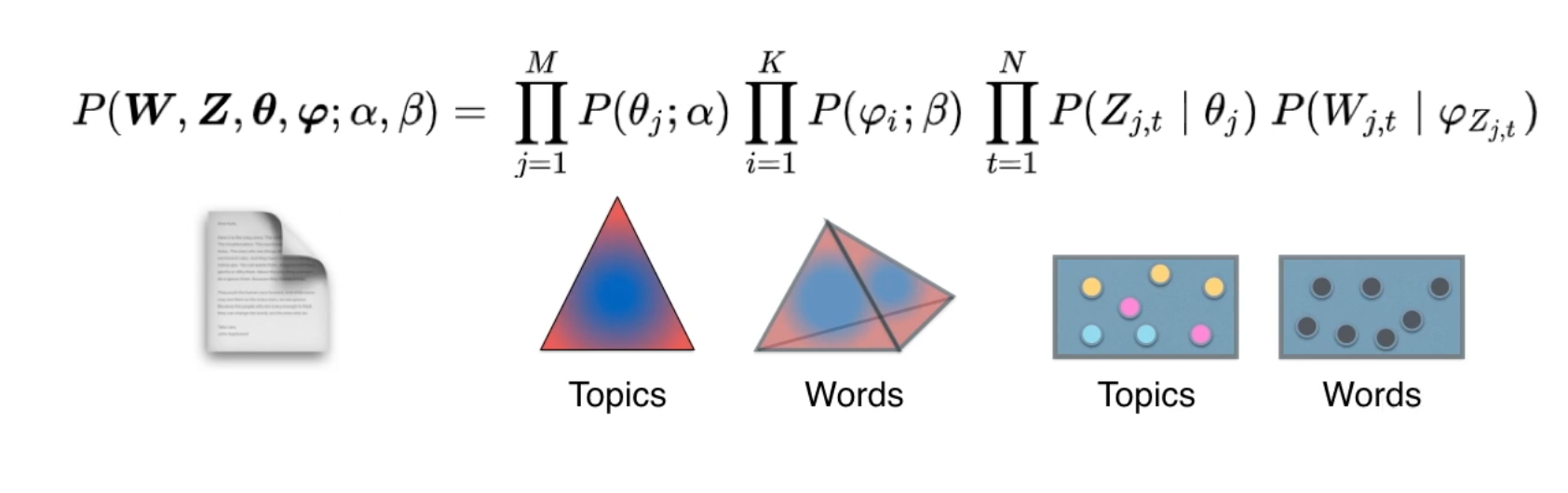Тематическое моделирование — семейство методов обработки больших коллекций текстовых документов. Эти методы позволяют определить, к каким темам относится каждый документ и какие слова образуют каждую тему.
Одним из таких методов является Латентное размещение Дирихле (Latent Dirichlet Allocation, LDA). Это вероятностная модель, которая позволяет выявить заданное количество тем в корпусе. В основе метода лежит предположение о том, что каждый документ представляет собой комбинацию ограниченного числа топиков (тем), а каждый топик — это распределение вероятностей для слов. При этом, как и в естественном языке, документы могут перекрывать друг друга по темам, а темы — по словам. Например, слово «мяч» может быть связано не только со спортивным топиком, но и, например, с политическим («клятва в зале для игры в мяч»).
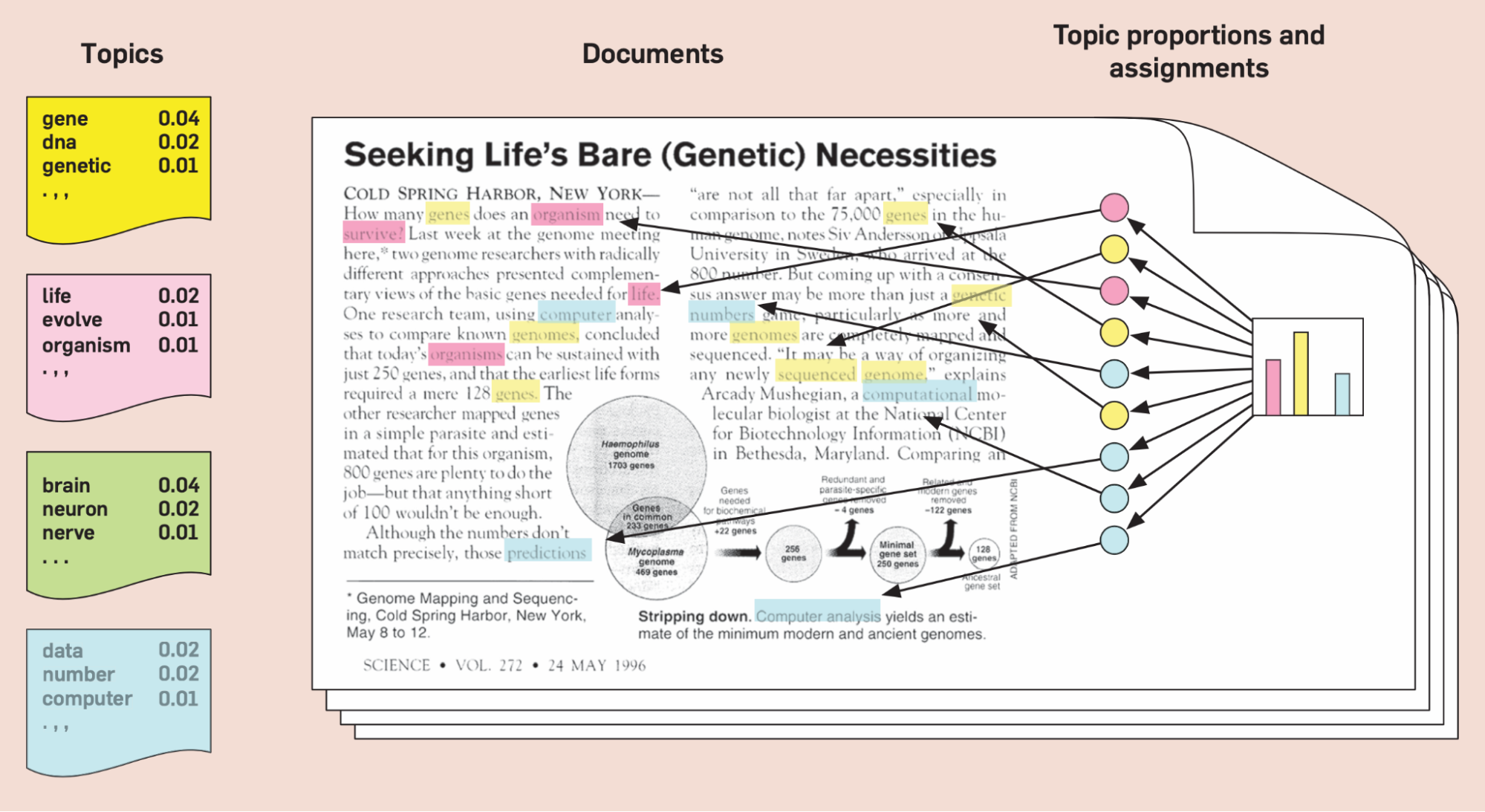
Создатели метода поясняют это на примере публикации из журнала Science.
Источник: Blei, D. M. (2012), Probabilistic topic models
На картинке голубым выделена тема «анализ данных»; розовым — «эволюционная биология», а желтым — «генетика». Если разметить все слова в тексте (за исключением «шумовых», таких как союзы, артикли и т.п.), то можно увидеть, что документ представляет собой сочетание нескольких тем. Цветные «окошки» слева — это распределение вероятностей для слов в теме. Гистограмма справа — это распределение вероятностей для тем в документе. Все документы в коллекции представляют собой сочетание одних и тех же тем — но в разной пропорции. Например, в этом примере почти нет зеленого «текстовыделителя», что хорошо видно на гистограмме.
Ассоциацию тем с документами, с одной стороны, и слов с темами, с другой, и рассчитывает алгоритм. При этом LDA относится к числу методов обучения без учителя (unsupervised), то есть не требует предварительной разметки корпуса: машина сама «находит» скрытые в корпусе темы и аннотирует каждый документ. Это делает метод востребованным в тех случаях, когда мы сами точно не знаем, что ищем — например, в исследованиях электронных архивов.
Сложность при построении модели обычно заключается в том, чтобы установить оптимальное число тем: для этого предлагались различные количественные метрики, но важнейшим условием является также интерпретируемость результата. Единственно правильного решения здесь нет: например, моделируя архив газетных публикаций, мы можем подобрать темы так, чтобы они примерно соответствовали рубрикам («спорт», «политика», «культура» и т.п.), но в некоторых случаях бывает полезно сделать zoom in, чтобы разглядеть отдельные сюжеты (например, «фигурное катание» и «баскетбол» в спортивной рубрике…)
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.6
✔ forcats 1.0.0 ✔ stringr 1.6.0
✔ ggplot2 4.0.1 ✔ tibble 3.3.0
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.2.0
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Математические и статистические основания LDA достаточно хитроумны; общие принципы на русском языке хорошо изложены в статье “Как понять, о чем текст, не читая его” на сайте “Системный блок”, а лучшее объяснение на английском языке можно найти здесь и здесь.
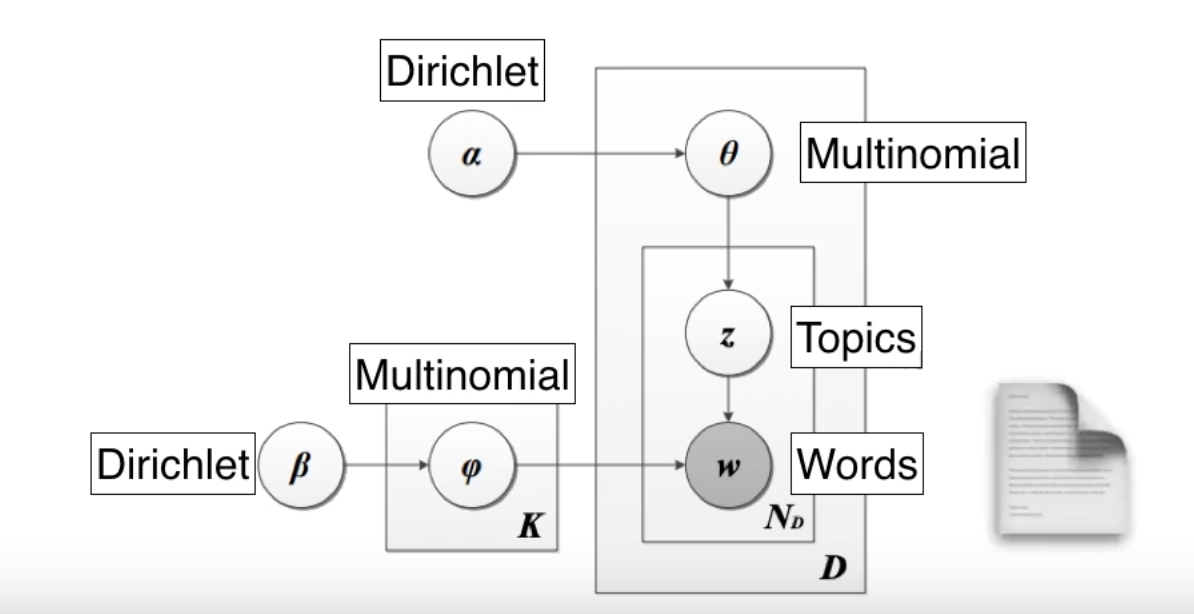
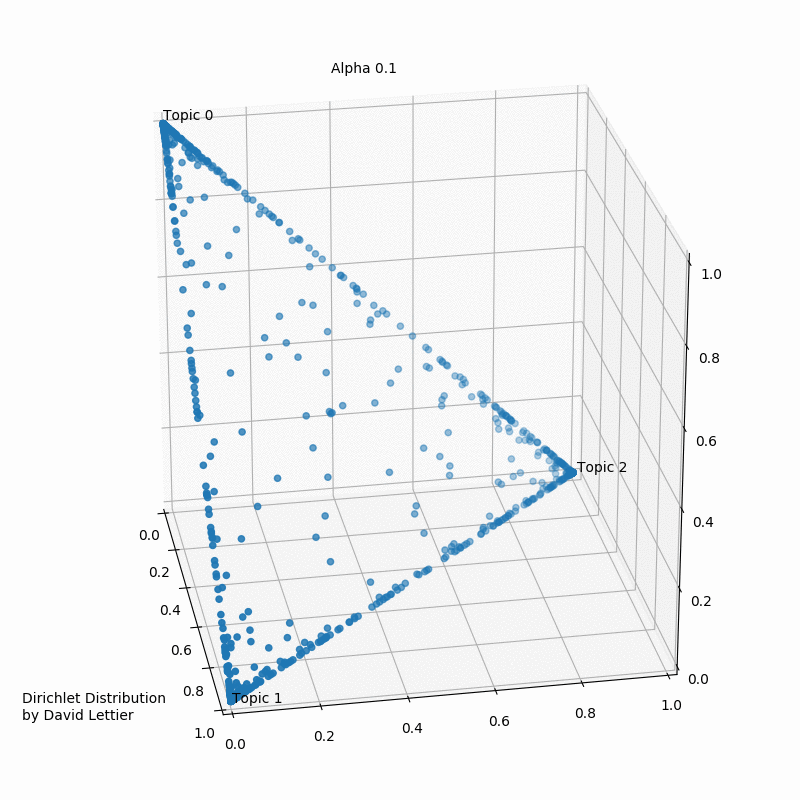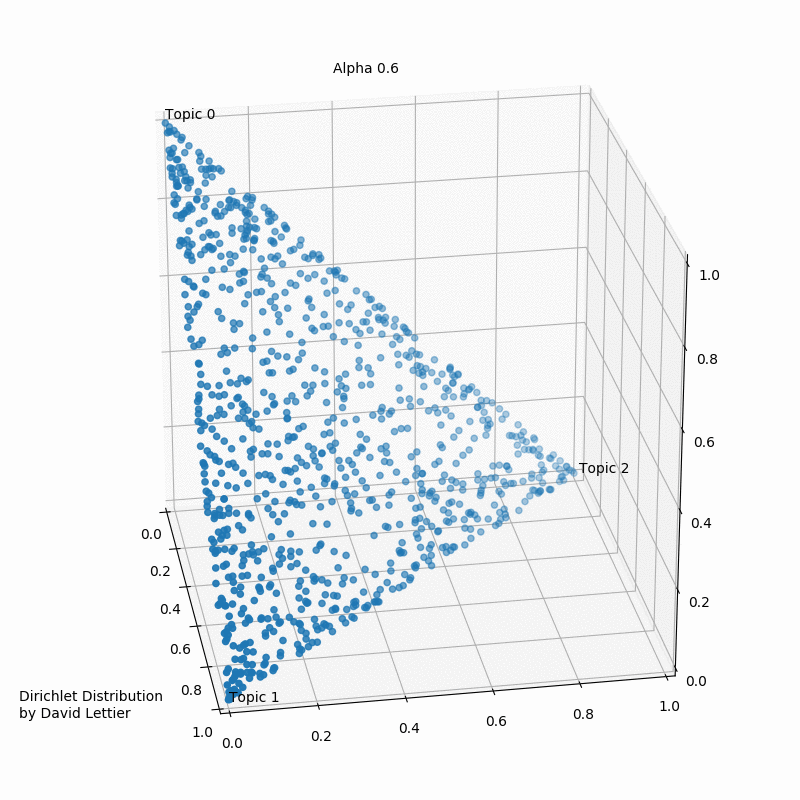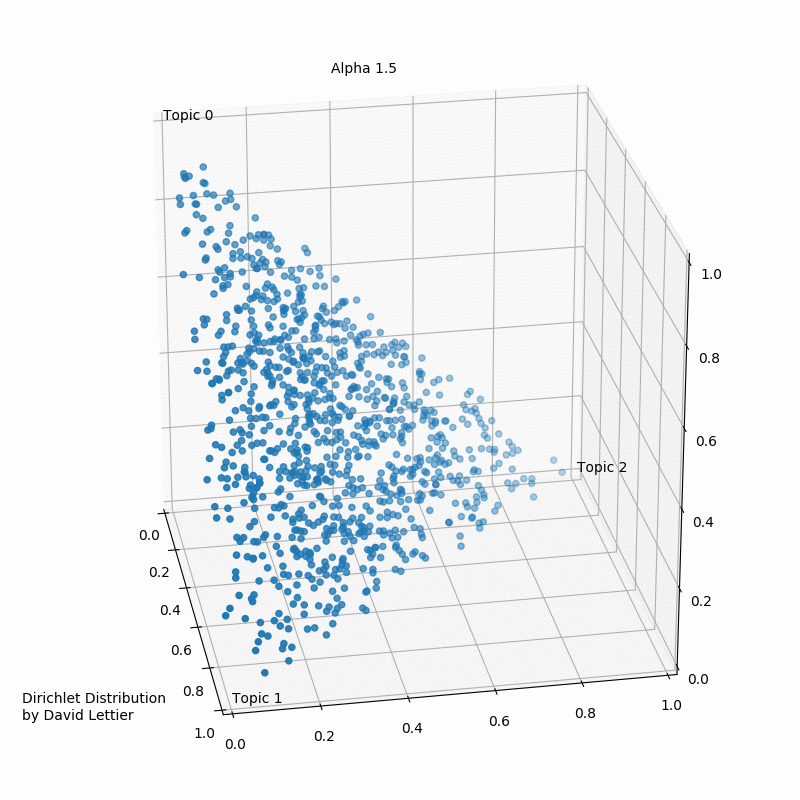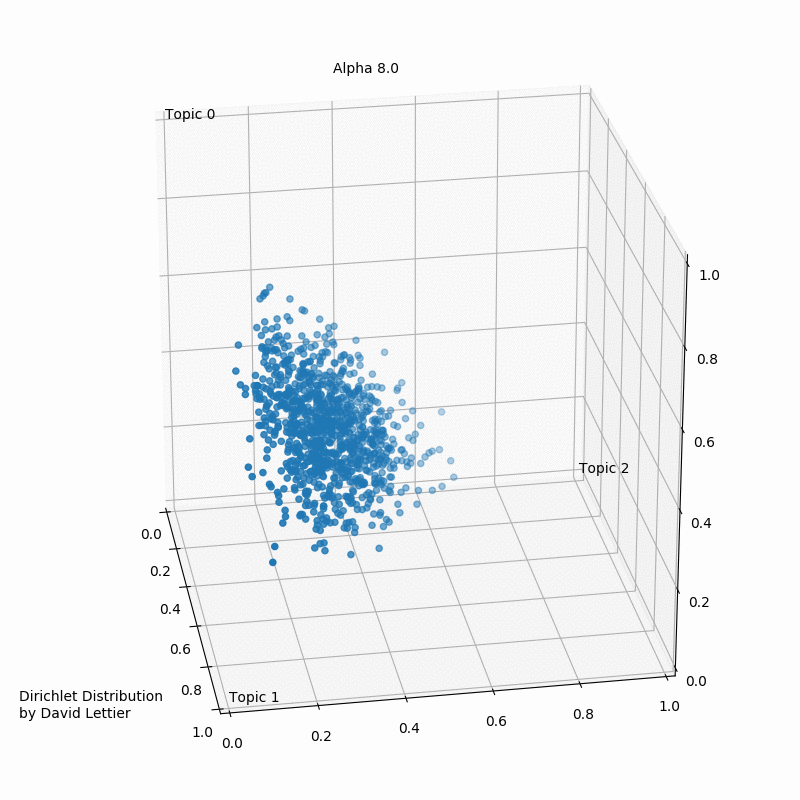
Альфа и бета на этой схеме - гиперпараметры распределения Дирихле. Гиперпараметры регулируют распределения документов по темам и тем по словам. Наглядно это можно представить так (при числе тем > 3 треугольник превращается в n-мерный тетраэдр):
При α = 1 получается равномерное распределение: темы распределены равномерно (поэтому α называют “параметром концентрации”). При значениях α > 1 выборки начинают концентрироваться в центре треугольника, представляя собой равномерную смесь всех тем. При низких значениях альфа α < 1 большинство наблюдений находится в углах – скорее всего, в в этом случае в документах будет меньше смешения тем.
Распределение документов по топикам θ зависит от значения α; из θ выбирается конкретная тема Z. Аналогичным образом гиперпараметр β определяет связь тем со словами. Чем выше бета, тем с большим числом слов связаны темы. При меньших значениях беты темы меньше похожи друг на друга. Конкретное слово W “выбирается” из распределения слов φ в теме Z.
13.3 Подготовка данных
Чтобы понять возможности алгоритма, мы попробуем передать ему тот же новостной архив (ссылка для скачивания). На новостях сразу видно адекватность модели; но это не значит, что применение LDA ограничено подобными сюжетами. Этот метод с успехом применяется, например, в историко-научных или литературоведческих исследованиях. Он хорошо подходит, если необходимо на основе журнального архива описать развитие некоторой области знания. Но сейчас нам подойдет пример попроще 👶
Поскольку LDA – вероятностная модель, то на входе она принимает целые числа. В самом деле, не имеет смысла говорить о том, что некое распределение породило 0.5 слов или того меньше. Поэтому мы считаем абсолютную, а не относительную встречаемость – и не tf_idf.
Warning in instance$preRenderHook(instance): It seems your data is too big for
client-side DataTables. You may consider server-side processing:
https://rstudio.github.io/DT/server.html
13.4 Матрица встречаемости
Для работы с LDA в R устанавливаем пакет topicmodels. На входе нужная нам функция этого пакета принимает такую структуру данных, как document-term matrix (dtm), которая используется для хранения сильно разреженных данных и происходит из популярного пакета для текст-майнинга tm.
Поэтому “тайдифицированный” текст придется для моделирования преобразовать в этот формат, а полученный результат вернуть в опрятный формат для визуализаций.
Для преобразования подготовленного корпуса в формат dtm воспользуемся возможностями пакета tidytext:
news_dtm <- news_counts |>cast_dtm(id, term = token, value = n)news_dtm
<<DocumentTermMatrix (documents: 3407, terms: 6299)>>
Non-/sparse entries: 196774/21263919
Sparsity : 99%
Maximal term length: 20
Weighting : term frequency (tf)
Убеждаемся, что почти все ячейки в нашей матрице – нули (99-процентная разреженность).
13.5 Оценка perplexity
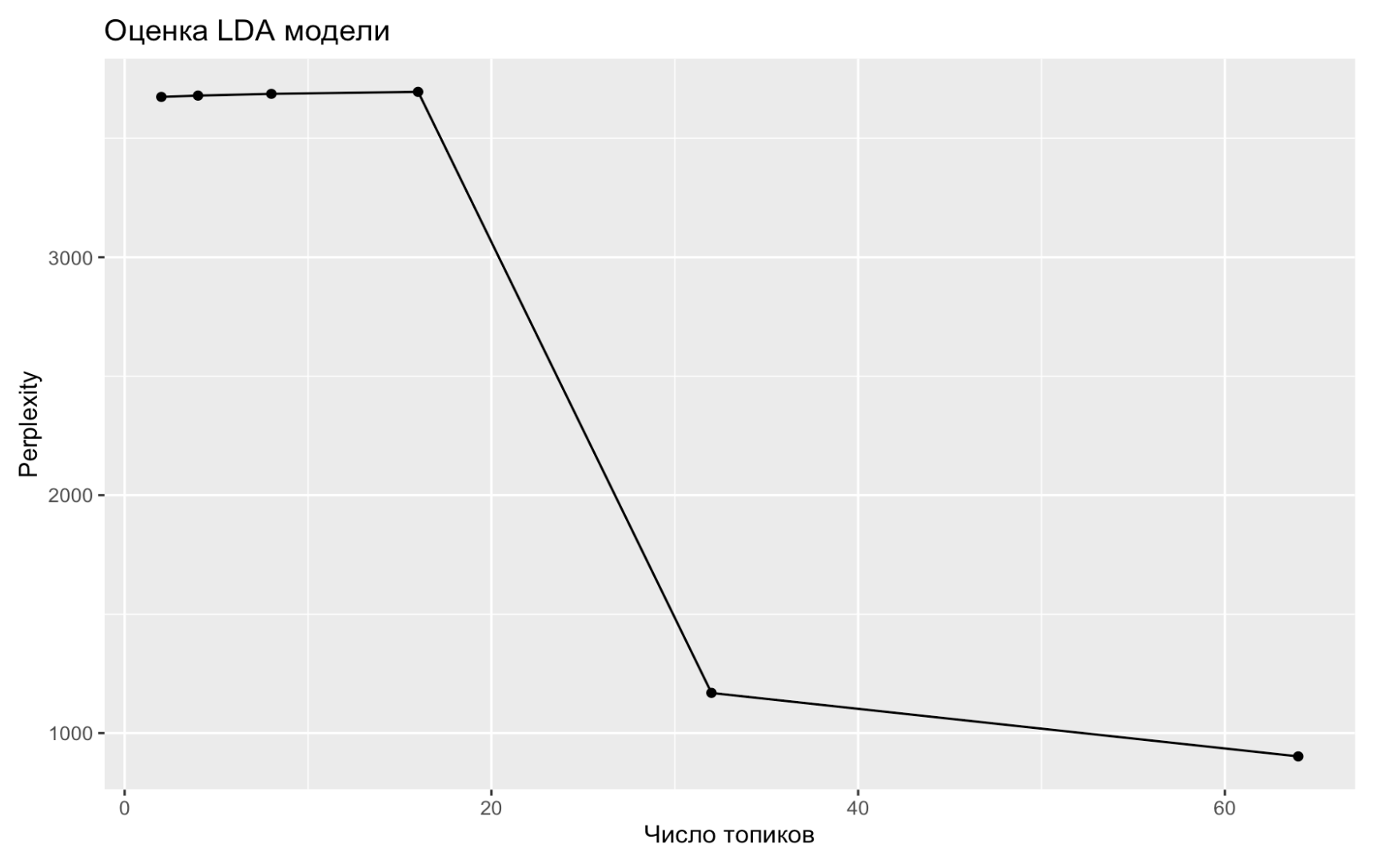
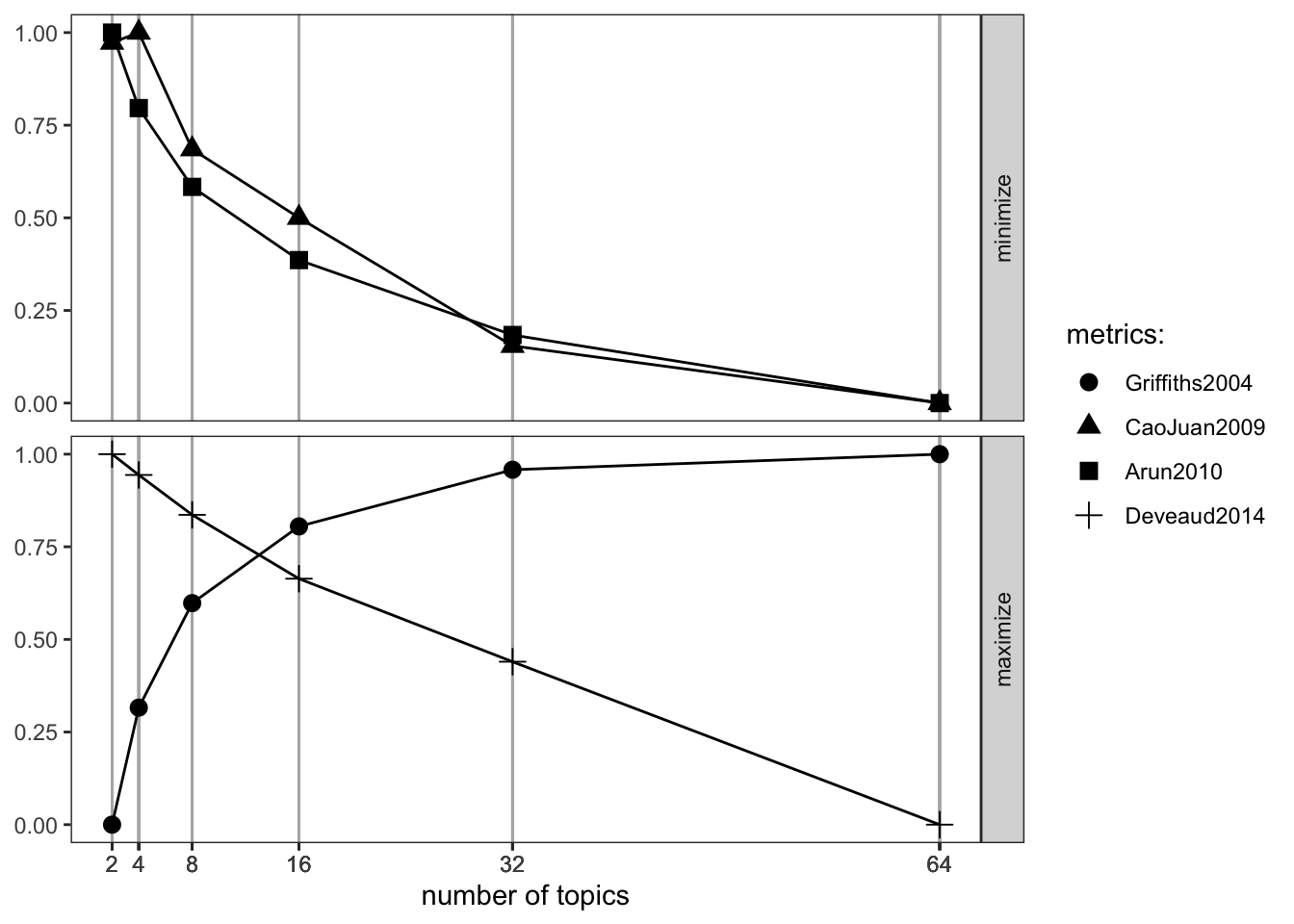
Количество тем для модели LDA задается вручную. Здесь на помощь приходит функция perplexity() из topicmodels. Она показывает, насколько подогнанная модель не соответствует данным – поэтому чем значение меньше, тем лучше.
Подгоним сразу несколько моделей с разным количеством тем и посмотрим, какая из них покажет себя лучше. Чтобы ускорить дело, попробуем запараллелить вычисления.
plan(multisession, workers =6)n_topics <-c(2, 4, 8, 16, 32, 64)news_lda_models <- n_topics |>future_map(topicmodels::LDA, x = news_dtm, control =list(seed =0211), .progress =TRUE)
Этот график тоже говорит о том, что модель требует не меньше 32 тем.
13.7 Модель LDA
news_lda <- topicmodels::LDA(news_dtm, k =32, control =list(seed =05092024))
Теперь наша тематическая модель готова. Ее можно скачать в формате .Rdata отсюда; это примерно 2.5 Mb.
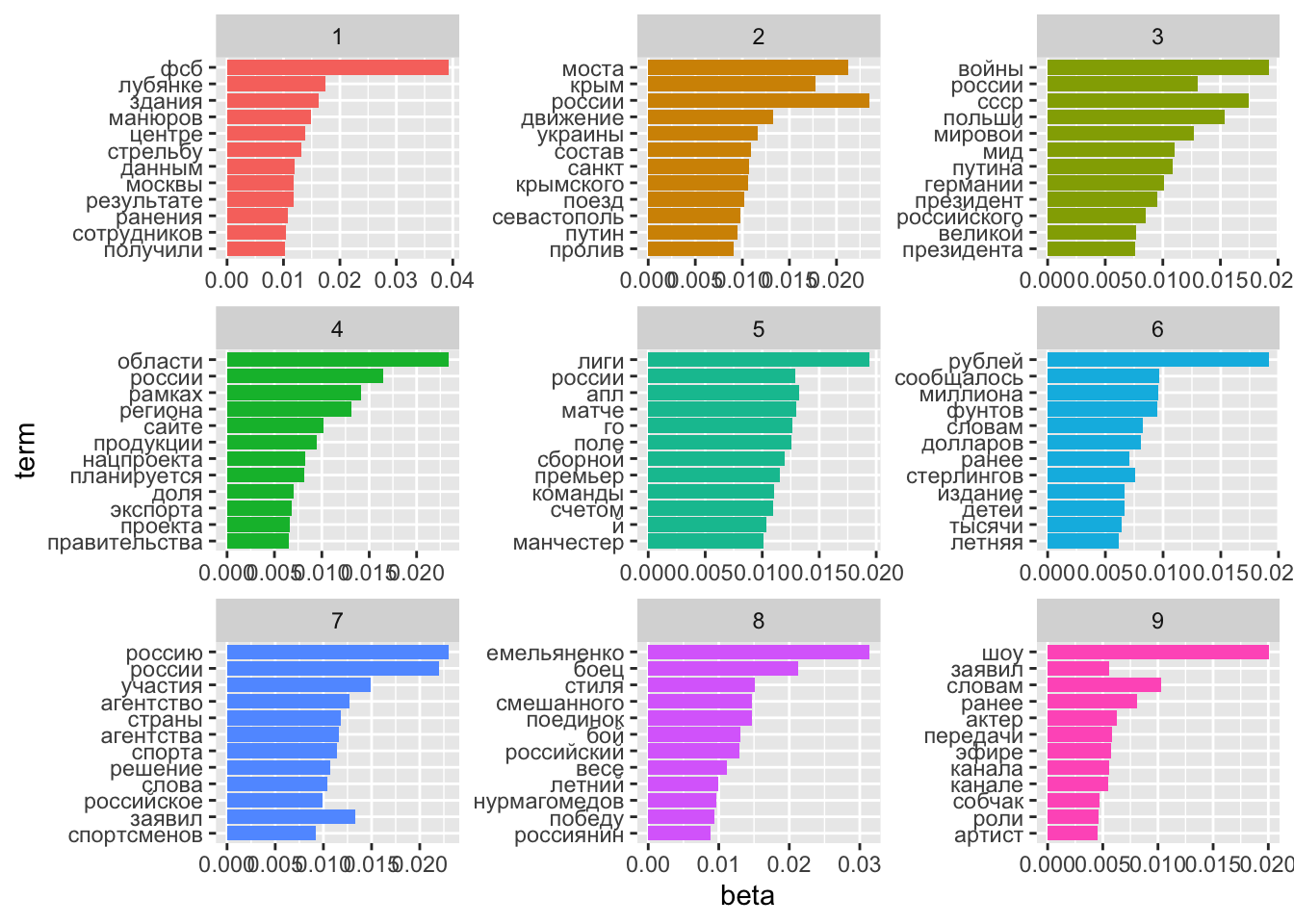
13.8 Слова и темы
Пакет tidytext дает возможность “тайдифицировать” объект lda с использованием разных методов. Метод β (“бета”) показывает связь топиков с отдельными словами.
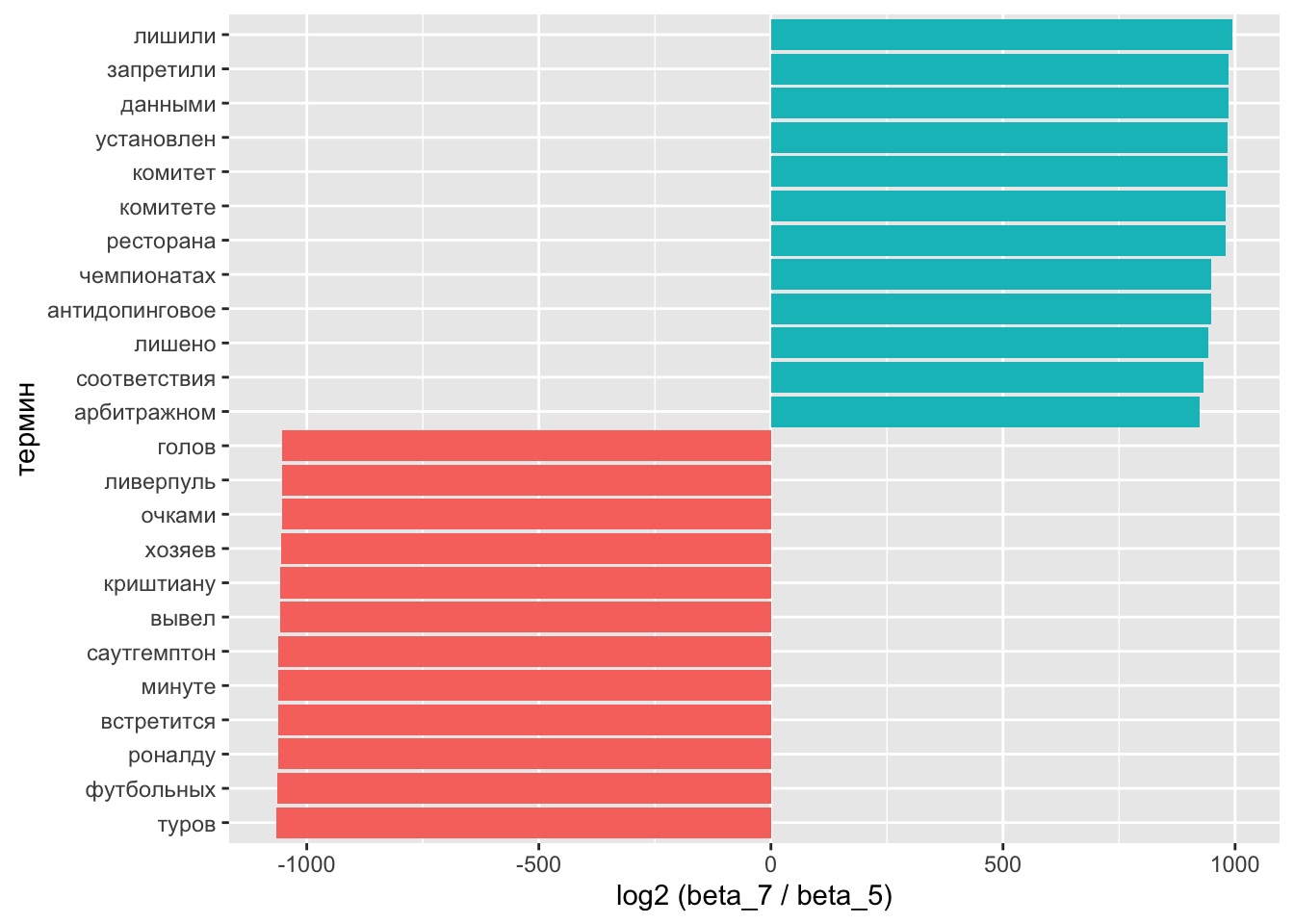
Сравним два топика по формуле: \(log_2\left(\frac{β_2}{β_1}\right)\). Если \(β_2\) в 2 раза больше \(β_1\), то логарифм будет равен 1; если наоборот, то -1. На всякий случай напомним: \(\frac{1}{2} = 2^{-1}\).
Для подсчетов снова придется трансформировать данные.
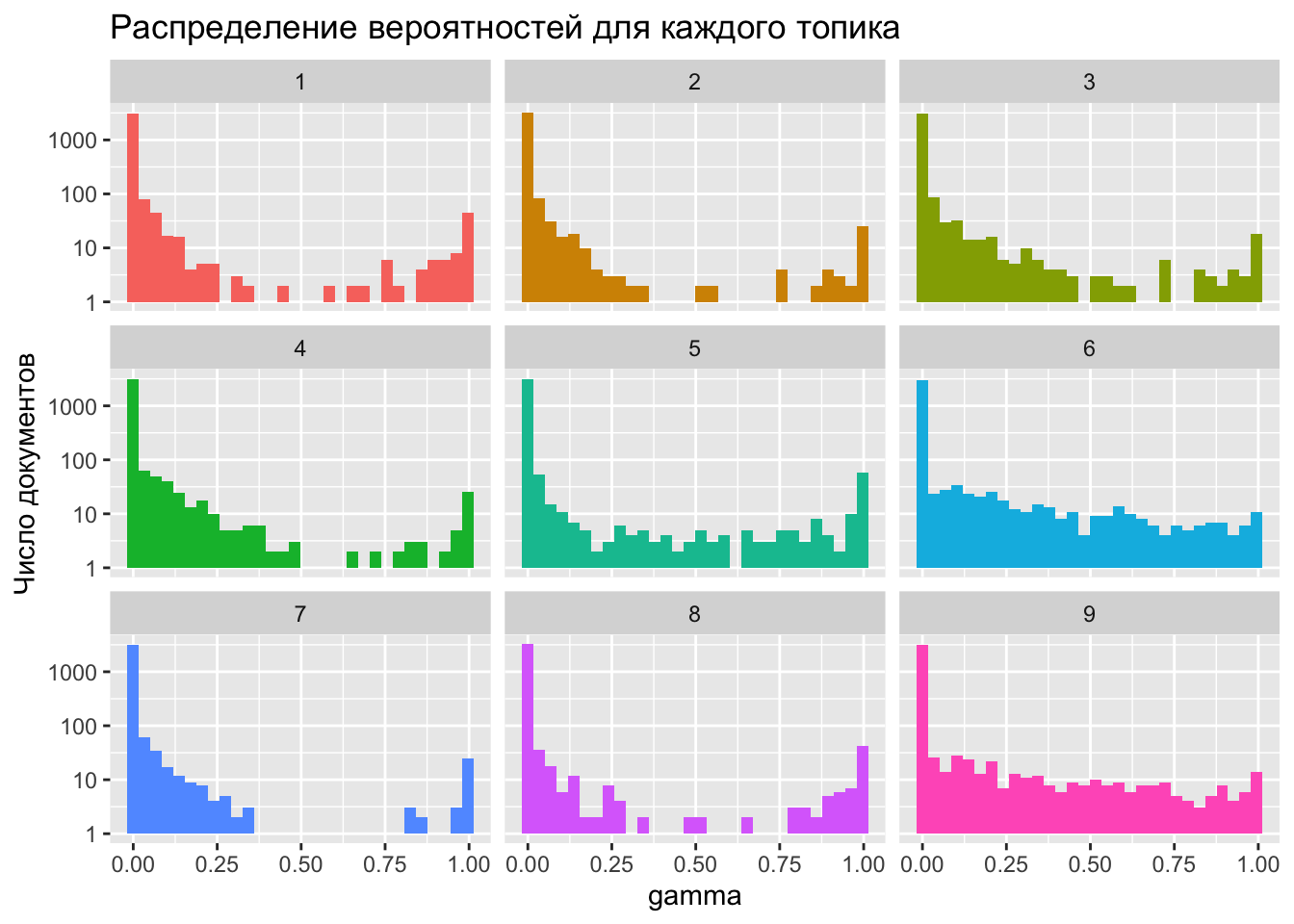
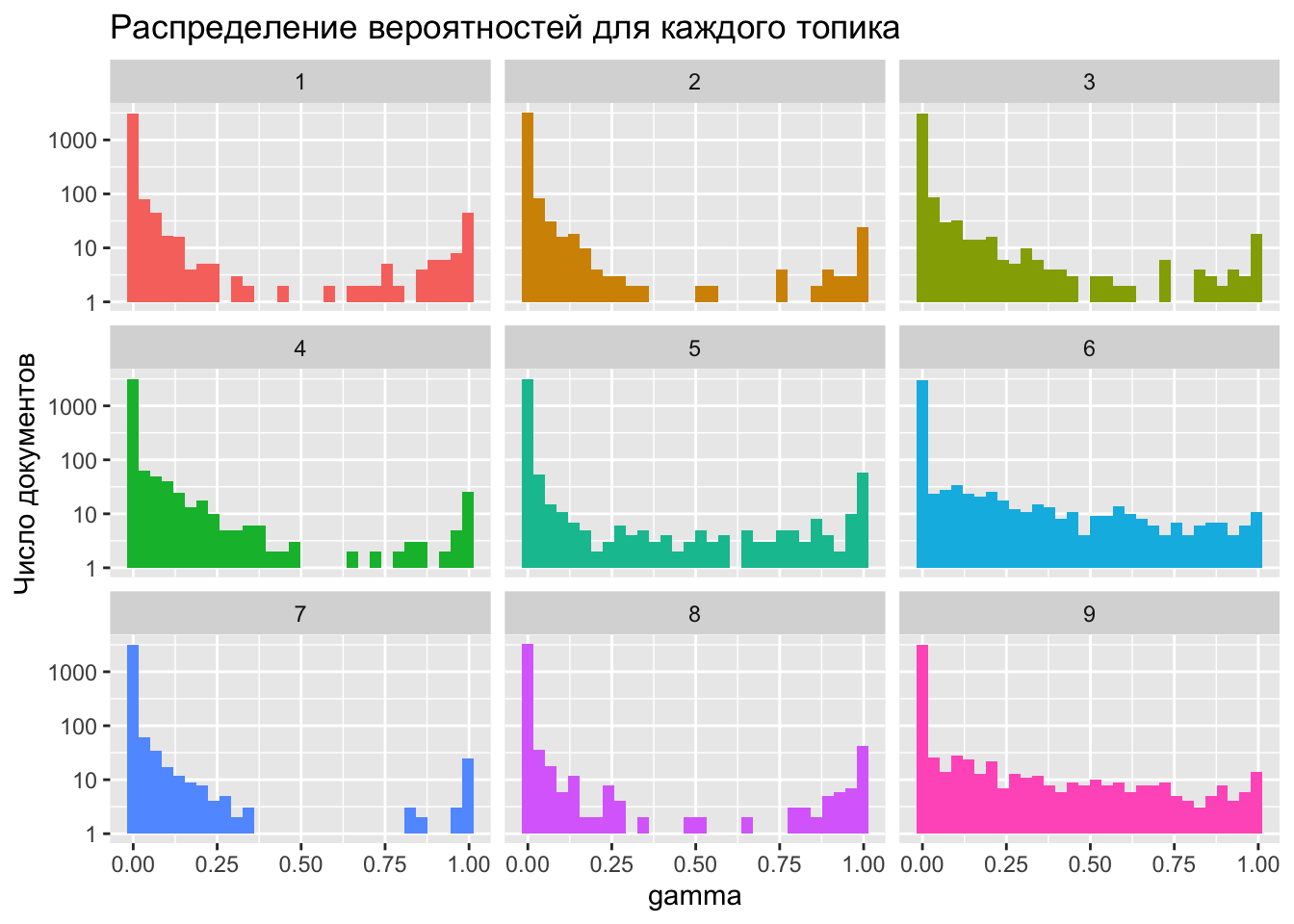
Значение gamma можно понимать как долю слов в документе, происходящую из данного топика, при этом каждый документ в рамках LDA рассматривается как собрание всех тем. Значит, сумма всех гамм для текста должна быть равна единице. Проверим.
Значения лямбды, очень близкие к нулю, показывают термины, наиболее специфичные для выбранной темы. Это означает, что вы увидите термины, которые “важны” для данной конкретной темы, но не обязательно “важны” для всего корпуса.
Значения лямбды, близкие к единице, показывают те термины, которые имеют наибольшее соотношение между частотой терминов по данной теме и общей частотой терминов из корпуса.
Сами разработчики советуют выставлять значение лямбды в районе 0.6.