library(tidyverse)3 Визуализации
3.1 Графические системы
В R есть несколько графических систем: базовый R, lattice и ggplot2. В этом курсе мы будем работать лишь с ggplot2 как с наиболее современной. Если вам интересны первые две, то вы можете обратиться к версии курса 2023/2024 г. и к интерактивным урокам swirl. Хорошее введение в тему: С. Мастицкий и В. Шитиков (2015).
Настоящая графическая сила R – это пакет ggplot2. В его основе лежит идея “грамматики графических элементов” Лиланда Уилкинсона (Мастицкий 2017) (отсюда “gg” в названии). С одной стороны, вы можете постепенно достраивать график, добавляя элемент за элементом (как в базовом R); с другой – множество параметров подбираются автоматически, как в Lattice.
О различных видах графиков можно почитать по ссылке. В этом уроке мы научимся строить диаграмму рассеяния (scatter plot) и столбиковую диаграмму (bar chart). Вот к чему мы стремимся.
3.2 Датасет: метаданные романов XIX-XX вв.
Знакомиться с ggplot2 мы будем на примере датасета из коллекции “NovelTM Datasets for English-Language Fiction, 1700-2009”, подготовленного Тедом Андервудом, Патриком Кимутисом и Джессикой Уайт. Они собрали метаданные о 210,266 томах художественной прозы в HathiTrust Digital Library и составили из них несколько датасетов.
Мы возьмем небольшой датасет, который содержит провернные вручную метаданные, а также сведения о категории художественной прозы для 2,730 произведений, созданных в период 1799-2009 г. (равные выборки для каждого года). Об особенностях сбора и подготовки данных можно прочитать по ссылке.
Мы попробуем проверить наблюдение, сделанное Франко Моретти в статье “Корпорация стиля: размышления о 7 тысячах заглавий (британские романы 1740-1850)” (2009 г., рус. перевод в книге “Дальнее чтение”, 2016 г.). Моретти заметил, что на протяжении XVIII-XIX вв. названия становятся короче, причем уменьшается не только среднее, но и стандартное отклонение (т.е. разброс значений). В публикации он предлагает несколько возможных объяснений для этого тренда. В датасете NovelTM есть не только романы (и не только британские), но тем более интересно будет сравнить результат.
Для этого урока данные были немного трансформированы: в частности, мы добавили столбец n_words, в котором хранятся сведения о числе слов в названии. Файл в формате .Rdata надо забрать из репозитория курса и прочитать в окружение.
load("../data/noveltm.Rdata")
noveltm3.3 Диаграмма рассеяния с geom_point()
Функция ggplot() имеет два основных аргумента: data и mapping. Аргумент mapping задает эстетические атрибуты геометрических объектов. Обычно используется в виде mapping = aes(x, y), где aes() означает aesthetics.
Под “эстетикой” подразумеваются графические атрибуты, такие как размер, форма или цвет. Вы не увидите их на графике, пока не добавите какие-нибудь “геомы” – геометрические объекты (точки, линии, столбики и т.п.). Эти объекты могут слоями накладываться друг на друга (Wickham и Grolemund 2016).
Диаграмма рассеяния, которая подходит для отражения связи между двумя переменными, делается при помощи geom_point(). Попробуем настройки по умолчанию.
noveltm |>
ggplot(aes(inferreddate, n_words)) +
geom_point()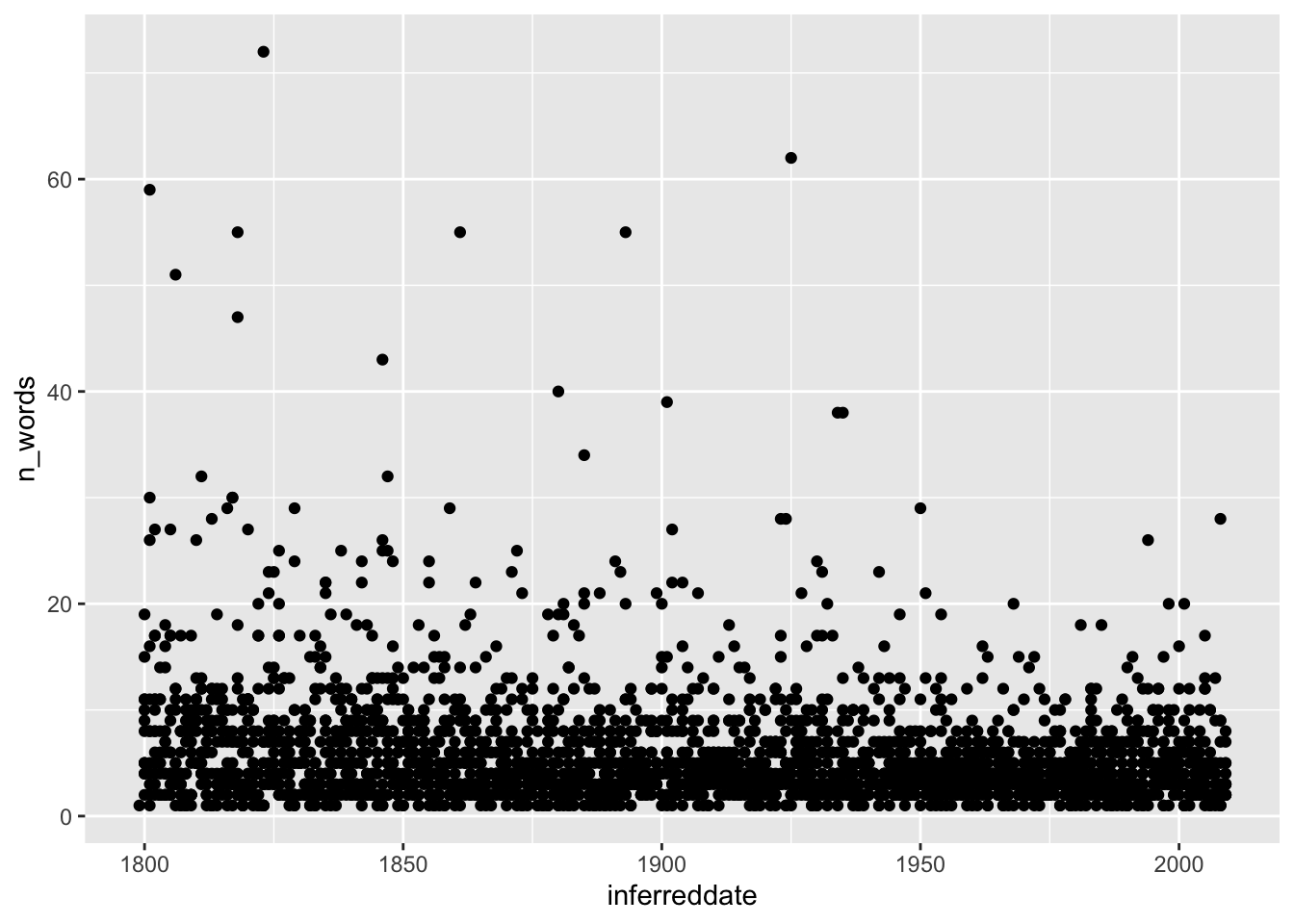
Упс. Точек очень много, и они накладываются друг на друга, так как число слов – дискретная величина. Поступим так же, как Моретти, который отразил на графике среднее для каждого года.
3.4 Среднее со stat_summary()
Для этого у нас есть два пути. Первый: обобщить данные при помощи group_by() и summarise(), как мы делали в прошлом уроке. Второй: воспользоваться возможностями stat_summary() в самом ggplot2.
noveltm |>
filter(!is.na(n_words)) |>
ggplot(aes(inferreddate, n_words)) +
geom_point(color = "grey80") +
stat_summary(fun.y = "mean", geom = "point", color = "steelblue")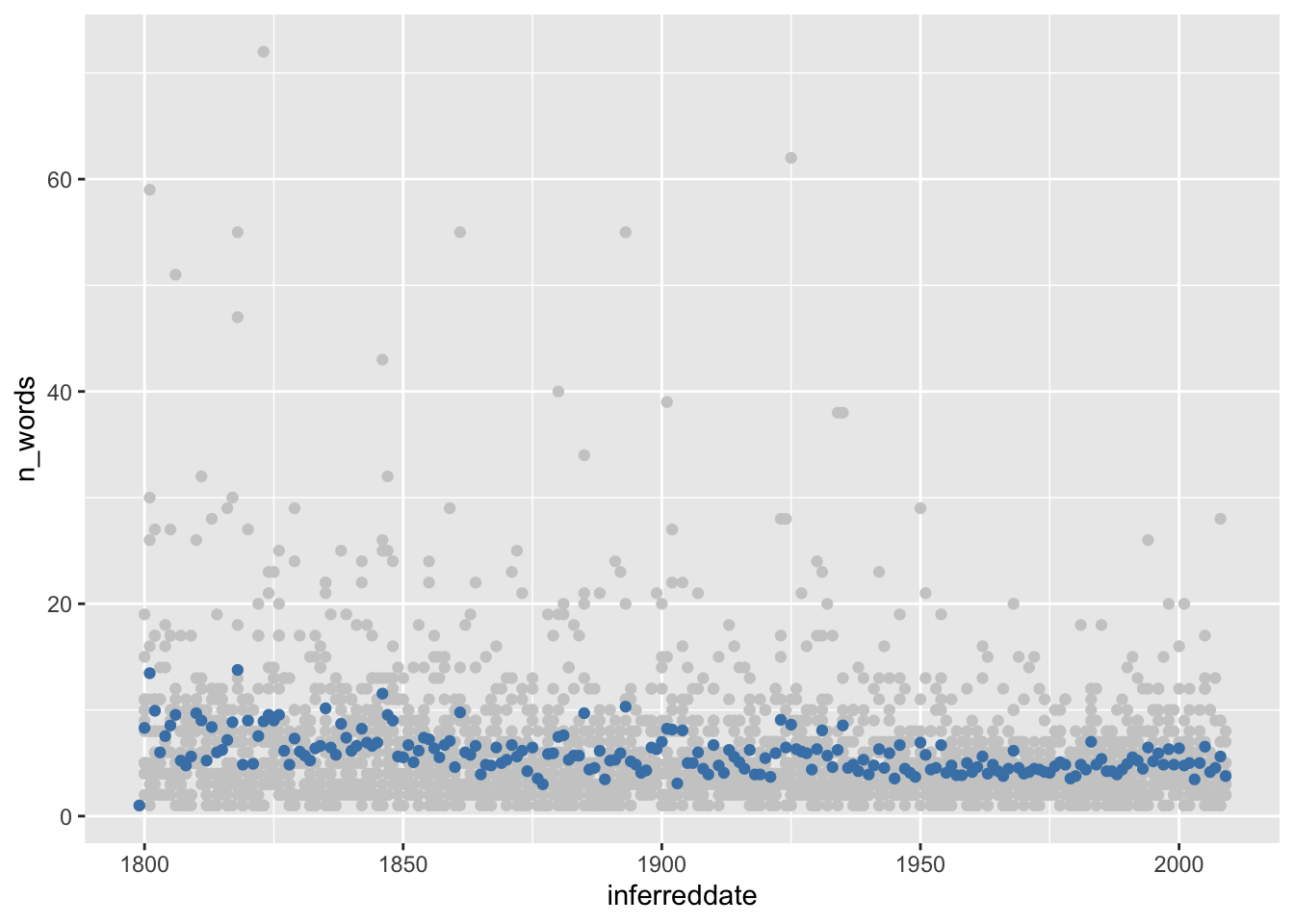
Оставим только среднее и добавим линию тренда, а также уберем подпись оси X.
noveltm |>
filter(!is.na(n_words)) |>
ggplot(aes(inferreddate, n_words)) +
stat_summary(fun.y = "mean", geom = "point", color = "steelblue") +
geom_smooth(color = "tomato") +
labs(x = NULL)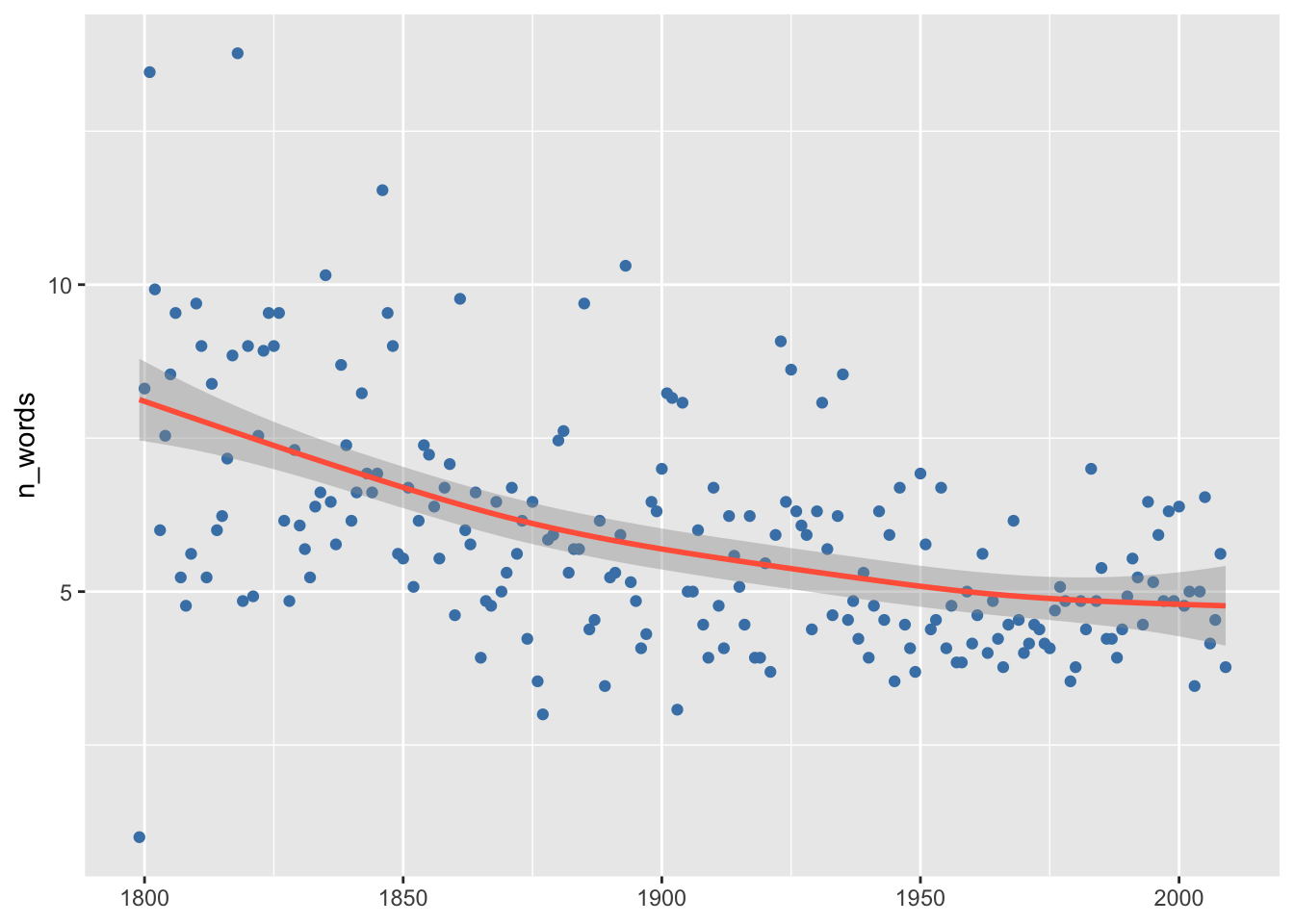
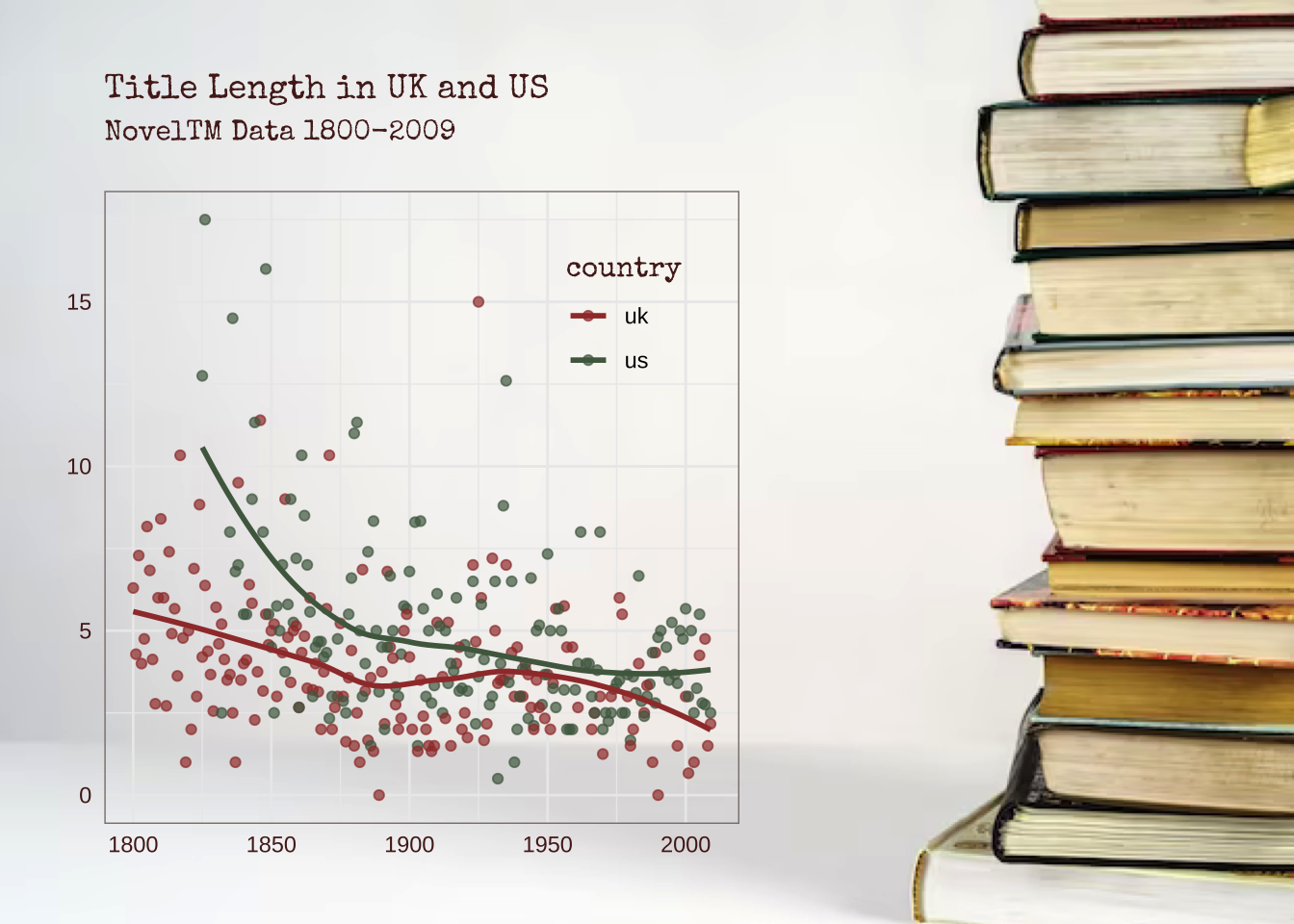
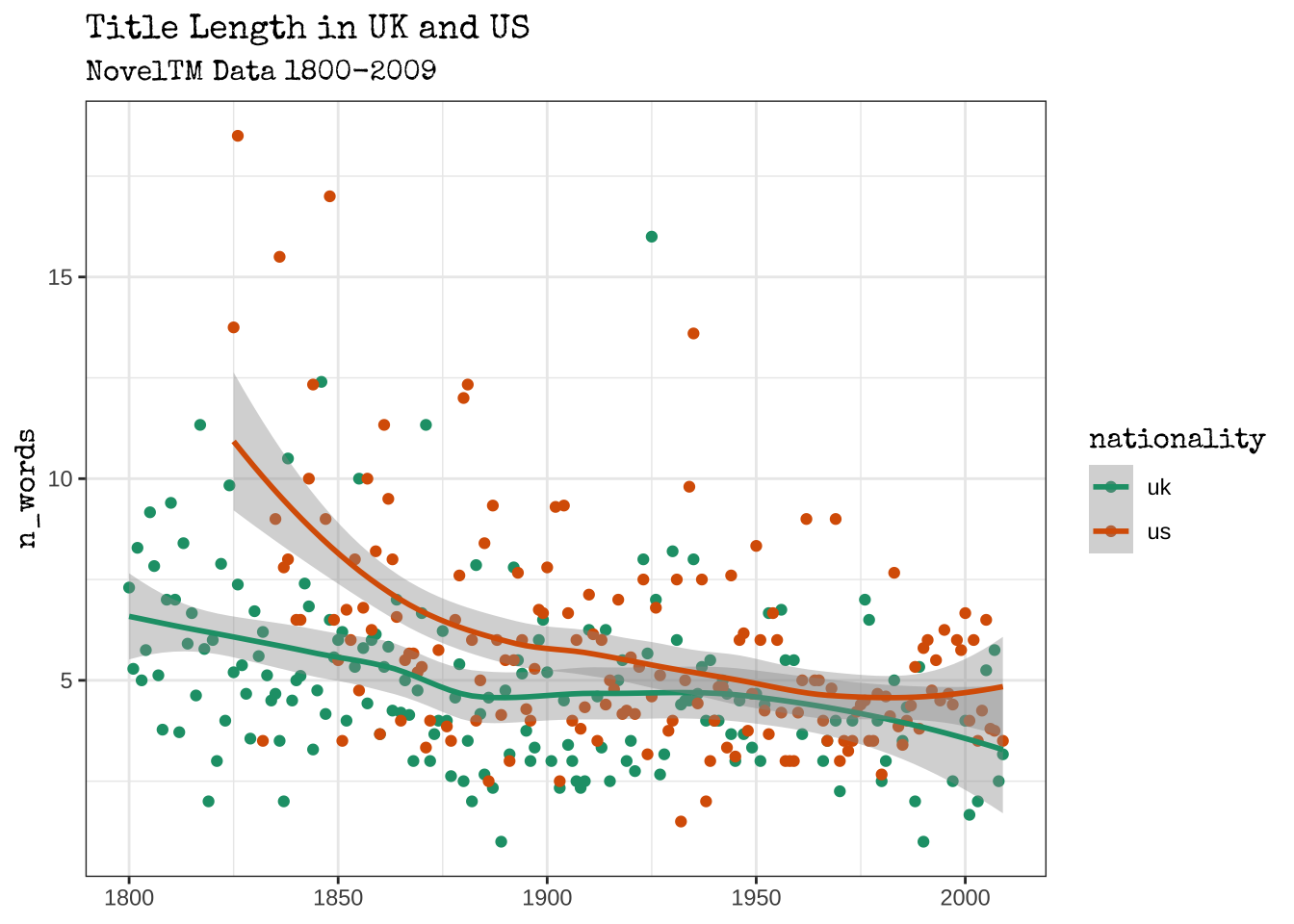
Нисходящая тенденция, о которой писал Моретти, хорошо прослеживается. Но, возможно, она характерна не для всех стран?
3.5 Сравнение двух групп
В столбце nationality хранятся данные о происхождении писателя.
noveltm |>
count(nationality, sort = TRUE) |>
print()# A tibble: 68 × 2
nationality n
<chr> <int>
1 uk 861
2 us 801
3 <NA> 630
4 ir 74
5 fr 68
6 au 45
7 de 32
8 ca 30
9 in 22
10 ru 19
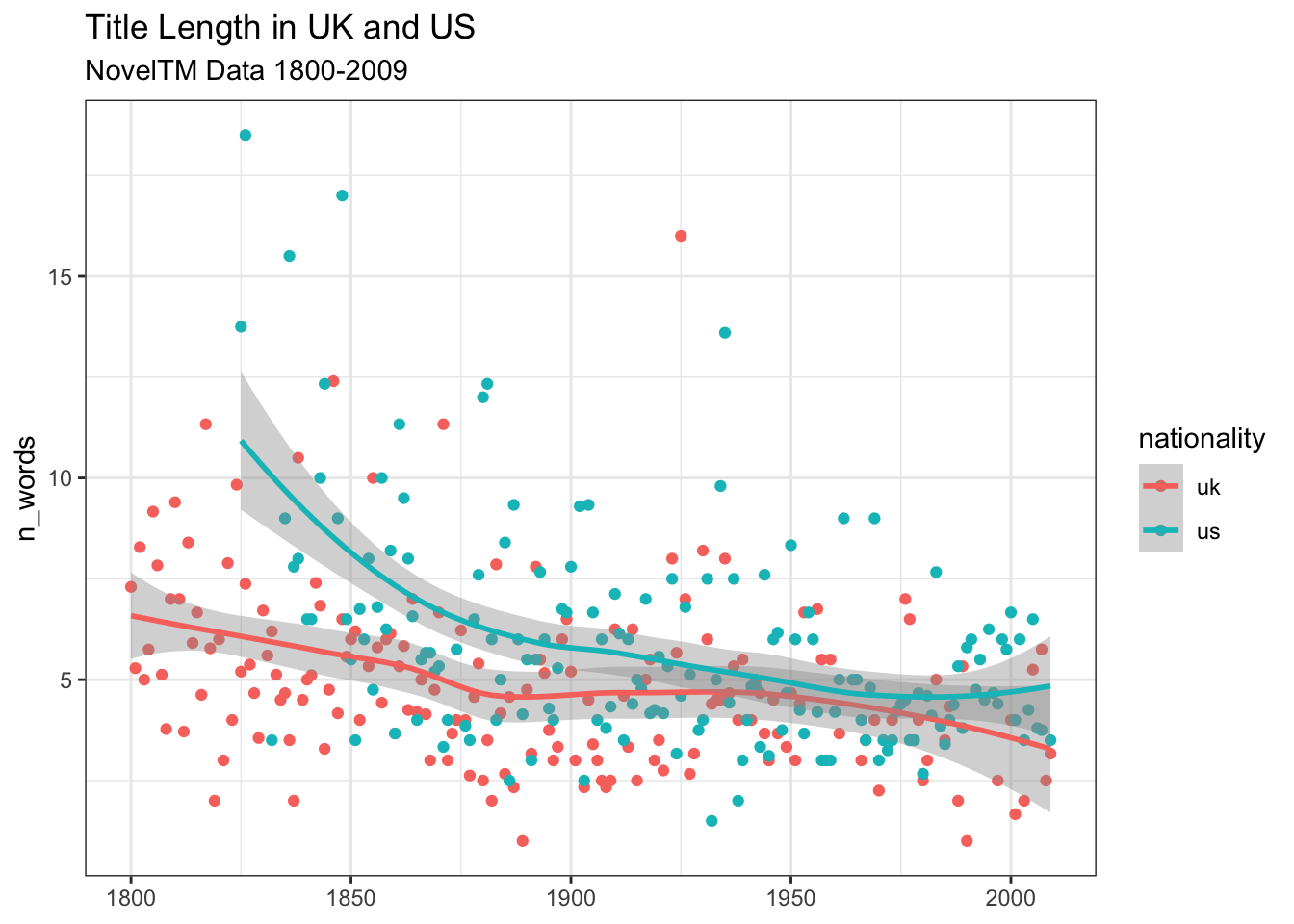
# ℹ 58 more rowsОтберем только английских и американских авторов и сравним тенденции в этих двух группах. Категориальную переменную (национальность) в нашем случае проще всего закодировать цветом. Также добавим заголовок и подзаголовок и поменяем тему.
noveltm |>
filter(nationality %in% c("uk", "us")) |>
add_count(inferreddate) |>
# убираем года, для которых только одно наблюдение
filter(n > 1) |>
# код как выше, но убираем цвет для геомов
ggplot(aes(inferreddate, n_words, color = nationality)) +
stat_summary(fun.y = "mean", geom = "point") +
geom_smooth(se = FALSE) +
# новая тема
theme_bw() +
# заголовки
labs(
title = "Title Length in UK and US",
subtitle = "NovelTM Data 1800-2009",
x = NULL
)
Для разведывательного анализа данных вполне достаточно настроек по умолчанию, но для публикации вы, вероятно, захотите вручную поправить шрифтовое и цветовое оформление.
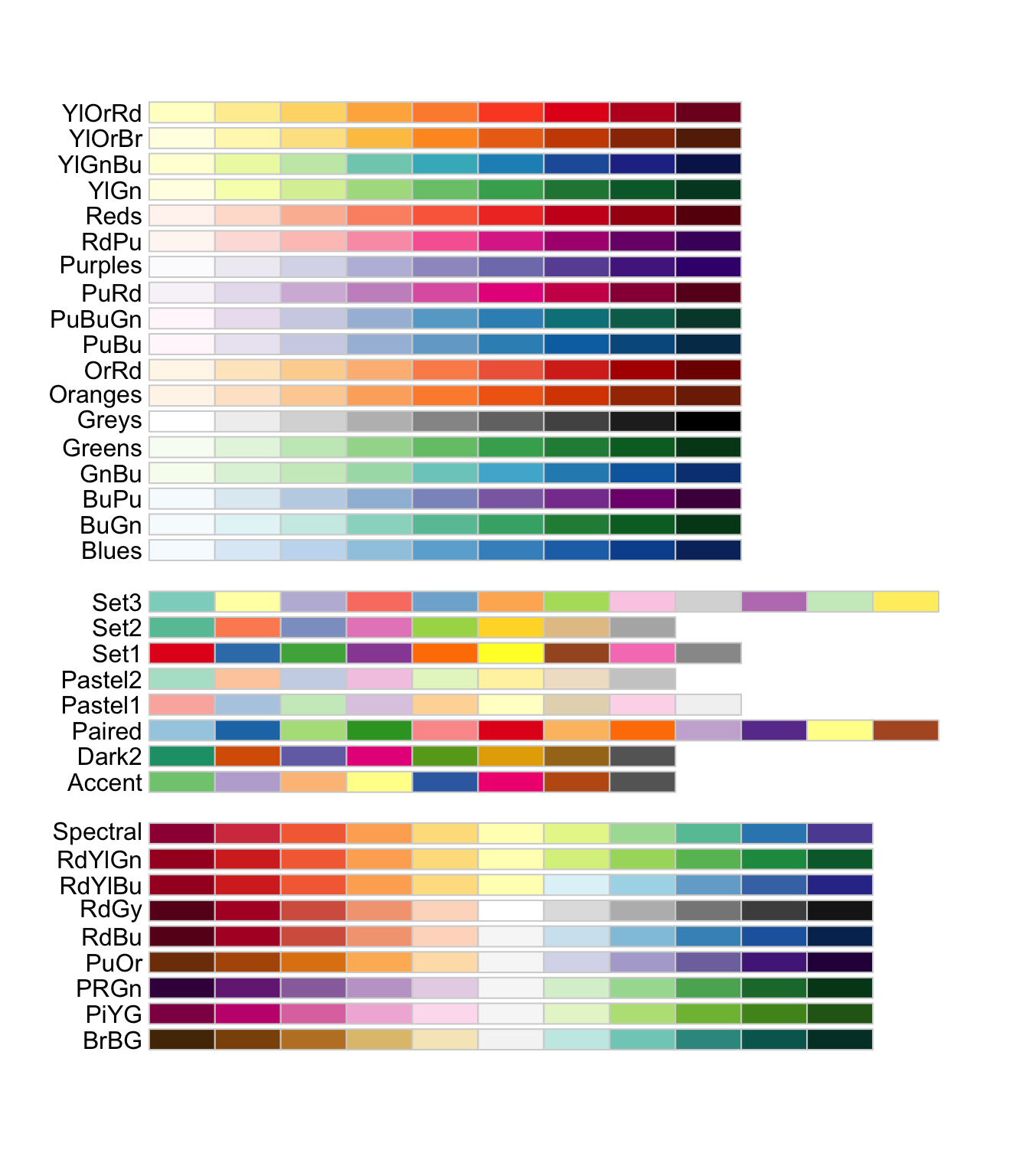
3.6 Цветовые шкалы
Ggplot2 дает возможность легко поменять цветовую палитру и шрифтовое оформление, а также добавить фон.
Функции scale_color_brewer() и scale_fill_brewer() позволяют использовать специально подобранные палитры хорошо сочетаемых цветов.
Общее правило для выбора таково.
Если дана качественная переменная с упорядоченными уровнями (например, “холодный”, “теплый”, “горячий”) или количественная переменная, и необходимо подчеркнуть разницу между высокими и низкими значениями, то для визуализации подойдет последовательная шкала.
Если дана количественная переменная с осмысленным средним значением, например нулем, 50%, медианой, целевым показателем и т.п., то выбираем расходящуюся шкалу.
Если дана качественная переменная, уровни которой невозможно упорядочить (названия городов, имена авторов и т.п.), ищем качественную шкалу.

Вот основные (но не единственные!) цветовые шкалы в R. Также цвета можно задавать и вручную – по названию или коду.
# тут все по-старому
noveltm |>
filter(nationality %in% c("uk", "us")) |>
add_count(nationality, inferreddate) |>
filter(n > 1) |>
ggplot(aes(inferreddate, n_words, color = nationality)) +
stat_summary(fun.y = "mean", geom = "point") +
geom_smooth(se = FALSE) +
theme_bw() +
labs(
title = "Title Length in UK and US",
subtitle = "NovelTM Data 1800-2009",
x = NULL
) +
# тут новое
scale_color_brewer(palette = "Dark2")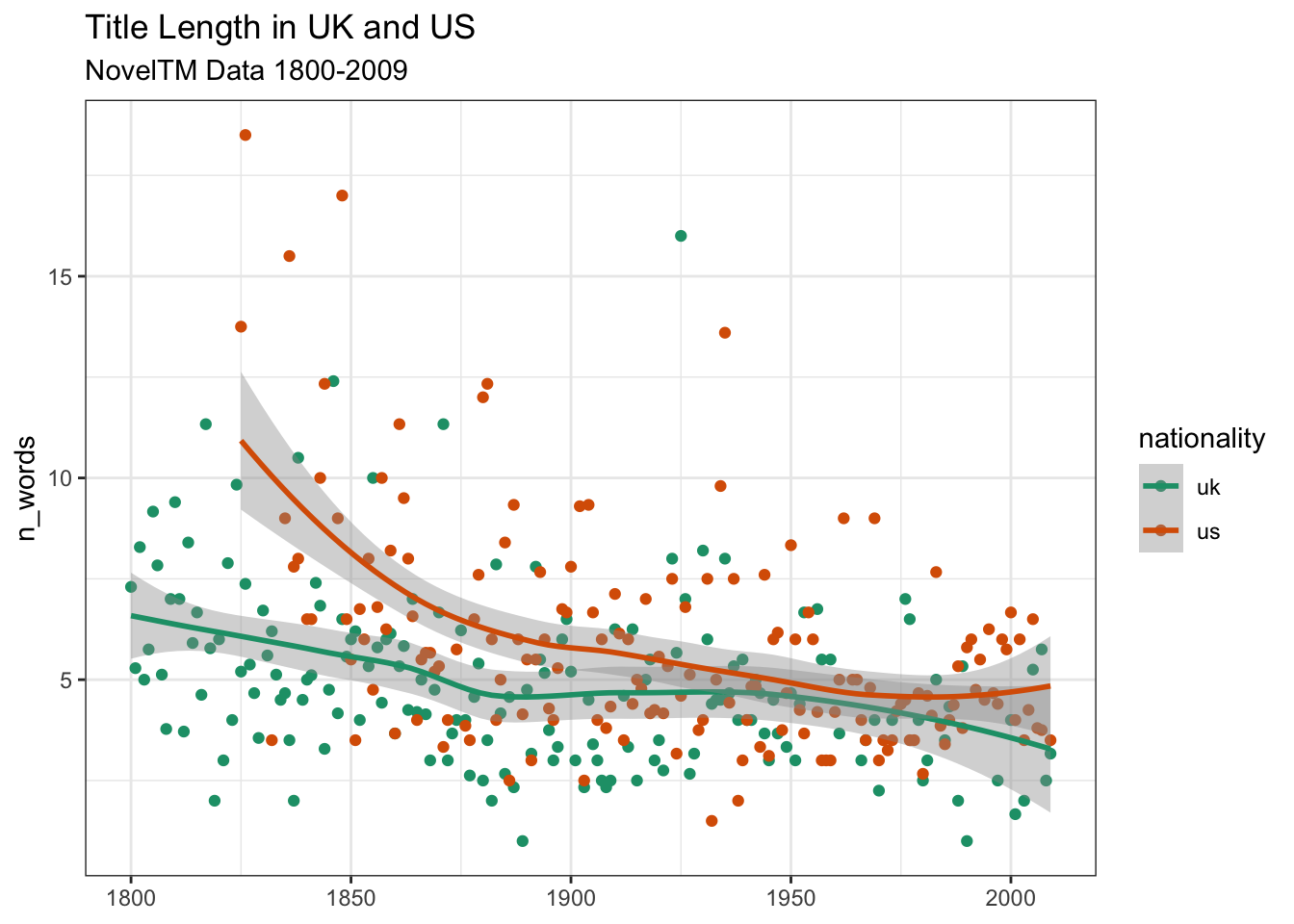
3.7 Шрифты
Пакет ggplot2 и расширения для него дают возможность использовать пользовательские шрифты.
# тут новое
library(showtext)
font_add_google("Special Elite", family = "special")
showtext_auto()
# тут почти все по-старому...
noveltm |>
filter(nationality %in% c("uk", "us")) |>
add_count(nationality, inferreddate) |>
filter(n > 1) |>
ggplot(aes(inferreddate, n_words, color = nationality)) +
stat_summary(fun.y = "mean", geom = "point") +
geom_smooth() +
theme_bw() +
labs(
title = "Title Length in UK and US",
subtitle = "NovelTM Data 1800-2009",
x = NULL
) +
scale_color_brewer(palette = "Dark2") +
# кроме этих строк, тут новое
theme(
axis.title = element_text(family = "special"),
title = element_text(family = "special"),
axis.text = element_text(family = "special")
)
3.8 Изображения
Изображения можно добавлять и в качестве фона, и вместо отдельных геомов, например точек. Поправим цвета, чтобы они лучше сочетались с цветом изображения.
library(ggimage)
url <- "./images/book.jpg"
# почти все по-старому...
font_add_google("Special Elite", family = "special")
showtext_auto()
# ...но график сохраняем в окружение под именем g
g <- noveltm |>
filter(nationality %in% c("uk", "us")) |>
add_count(nationality, inferreddate) |>
filter(n > 1) |>
ggplot(aes(inferreddate, n_words, color = nationality)) +
stat_summary(fun.y = "mean", geom = "point") +
geom_smooth() +
theme_bw() +
labs(
title = "Title Length in UK and US",
subtitle = "NovelTM Data 1800-2009",
x = NULL
) +
# подбираем новые цвета, в т.ч. для текста
scale_color_manual("country", values = c("#A03B37", "#50684E")) +
theme(
axis.title = element_text(family = "special", color = "#8B807C"),
title = element_text(family = "special", color = "#52211E"),
axis.text = element_text(color = "#52211E"),
axis.ticks = element_blank(),
# расширяем правое поле, чтобы все влезло
plot.margin = unit(c(0.4, 3, 0.4, 0.4), "inches"), # t, r, b, l
# рамочка
panel.border = element_rect(color = "#8B807C"),
# перемещаем легенду
legend.position = c(0.8, 0.8)
)
# let the magic start!
ggbackground(g, url)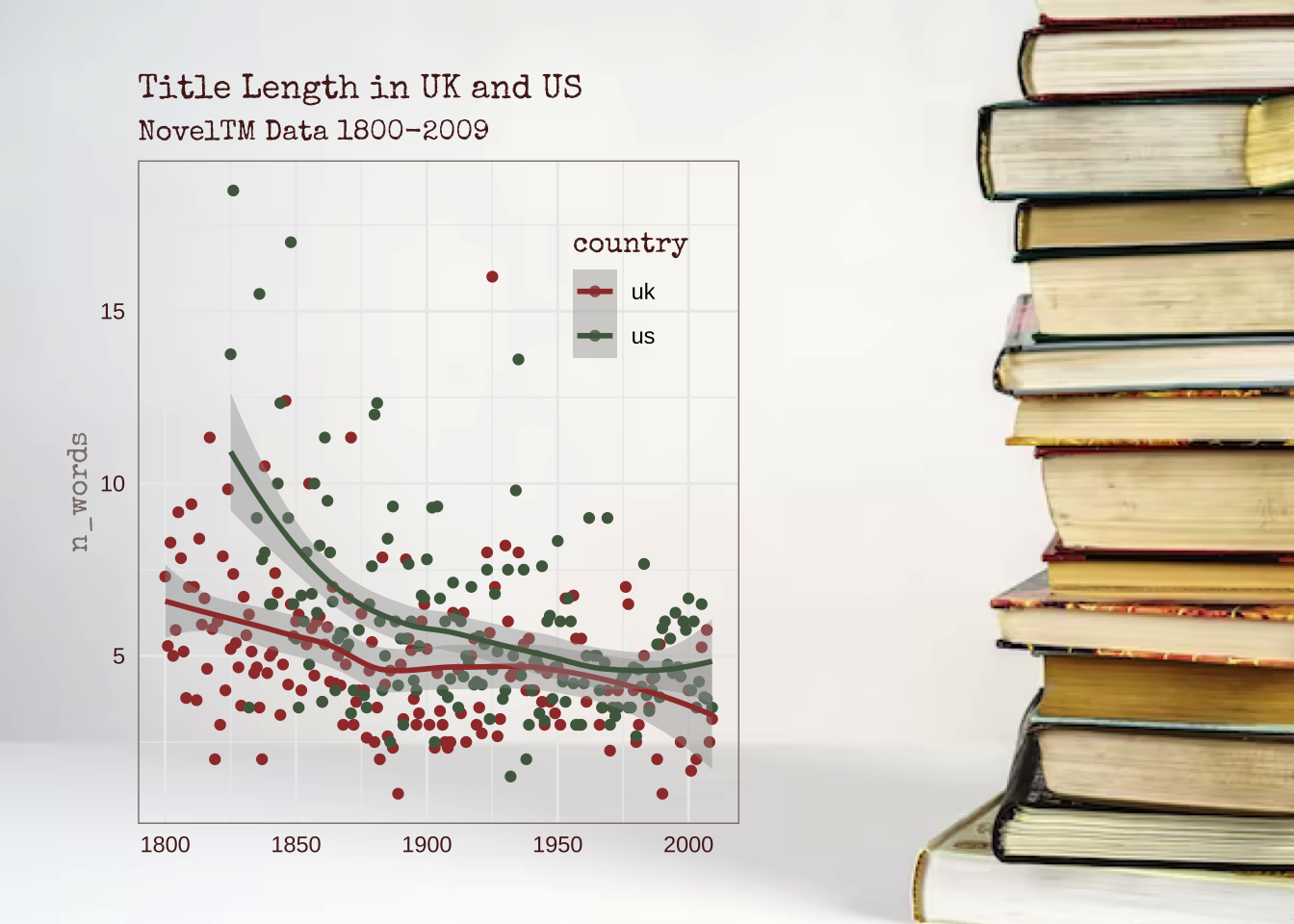
3.9 Столбиковая диаграмма
Для визуализации распределений качественных переменных подходит стобиковая диаграмма, которая наглядно показывает число наблюдений в каждой группе. В датасете NovelTM представлены следующие категории литературы.
noveltm |>
ggplot(aes(category, fill = category)) +
geom_bar()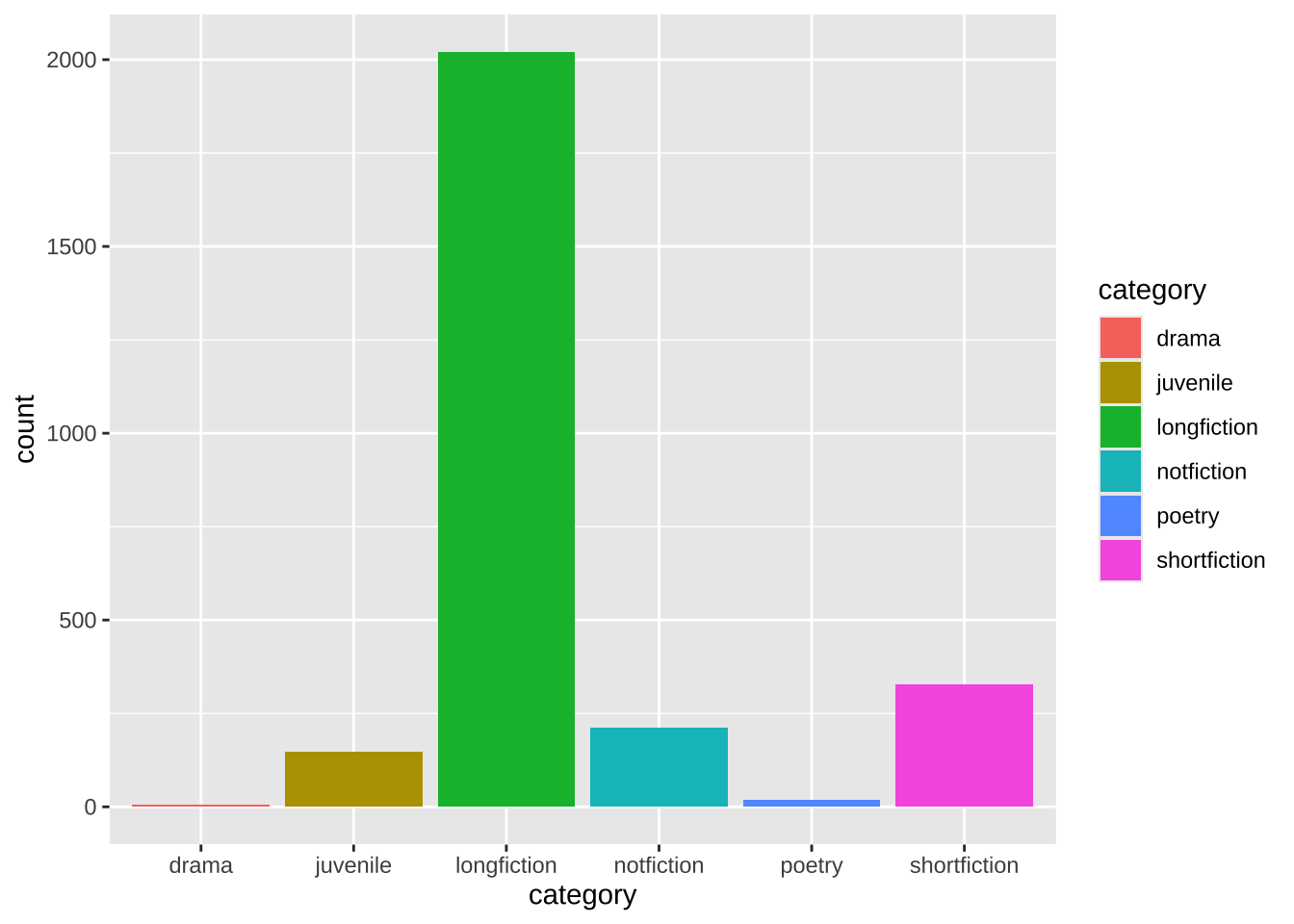
Нас будет интересовать категория longfiction, т.к. именно сюда попадает популярный в XIX в. жанр романа. Известно, что примерно до 1840 г. почти половина романистов были женщинами, но к началу XX в. их доля снизилась (Underwood 2019, 133). Отчасти это объясняется тем, что после середины XIX в. профессия писателя становится более престижной, а его социальный статус повышается, что приводит к “джентрификации” романа. Посмотрим, что на этот счет могут сказать данные NovelTM. Переменная gender хранит данные о гендере автора.
noveltm |>
ggplot(aes(gender, fill = gender)) +
geom_bar()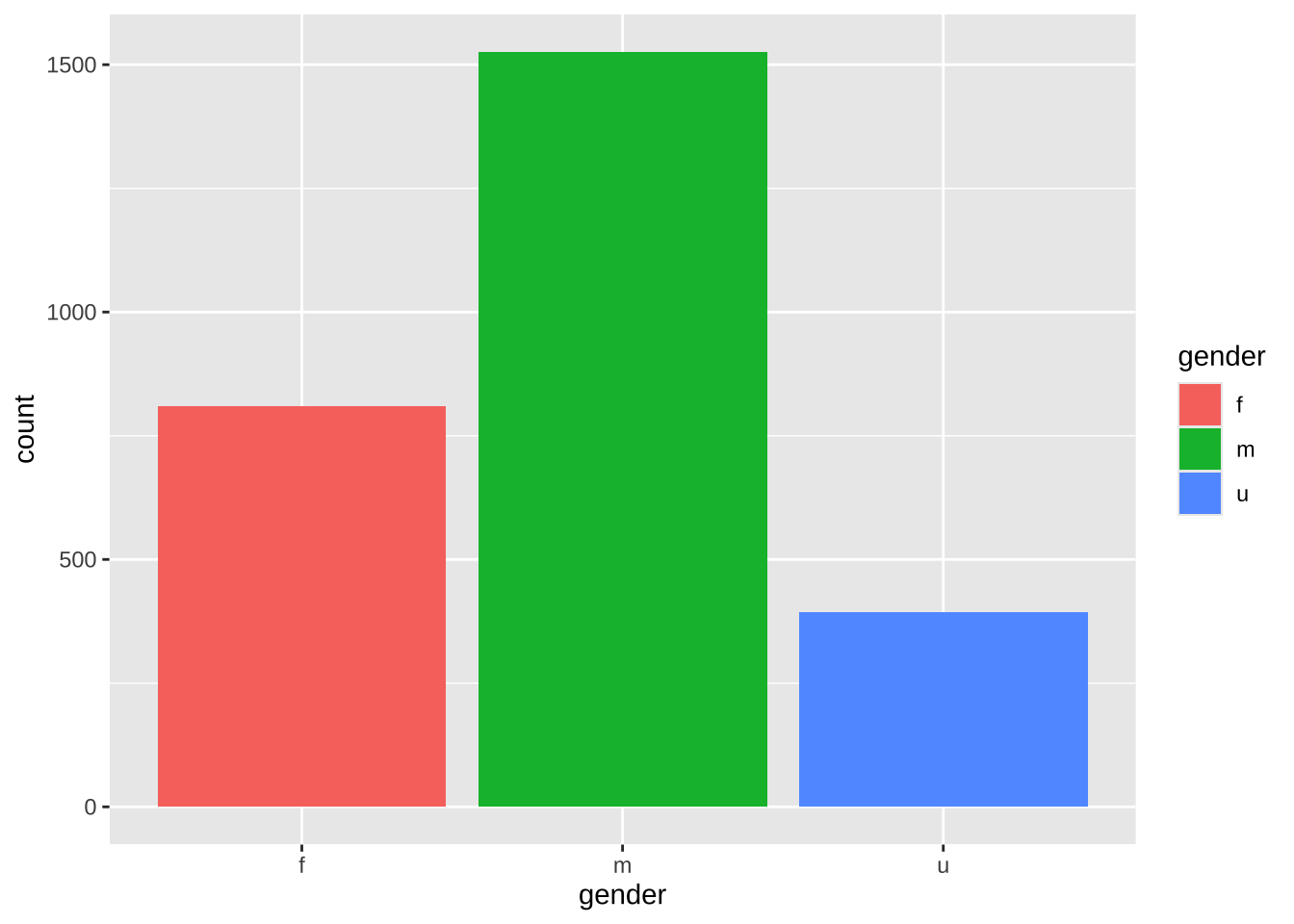
Отберем лишь одну категорию и два гендера.
noveltm_new <- noveltm |>
select(inferreddate, gender, category) |>
filter(gender != "u", category == "longfiction") |>
select(-category)
noveltm_new |>
print()# A tibble: 1,875 × 2
inferreddate gender
<dbl> <chr>
1 1896 m
2 1954 m
3 1976 f
4 1807 m
5 1807 m
6 1820 f
7 1820 f
8 1817 m
9 1817 m
10 1815 m
# ℹ 1,865 more rowsМожно предположить, что соотношение мужчин и женщин в разные десятилетия менялось. Чтобы это выяснить, нам надо преобразовать данные, указав для каждого года соответствующую декаду, и посчитать число мужчин и женщин в каждой декаде.
noveltm_new <- noveltm_new |>
mutate(decade = (inferreddate %/% 10) * 10)
noveltm_new |>
print()# A tibble: 1,875 × 3
inferreddate gender decade
<dbl> <chr> <dbl>
1 1896 m 1890
2 1954 m 1950
3 1976 f 1970
4 1807 m 1800
5 1807 m 1800
6 1820 f 1820
7 1820 f 1820
8 1817 m 1810
9 1817 m 1810
10 1815 m 1810
# ℹ 1,865 more rowsЭтого уже достаточно для визуализации, но она будет не очень наглядная.
noveltm_new |>
ggplot(aes(decade, fill = gender)) +
geom_bar(position = "dodge")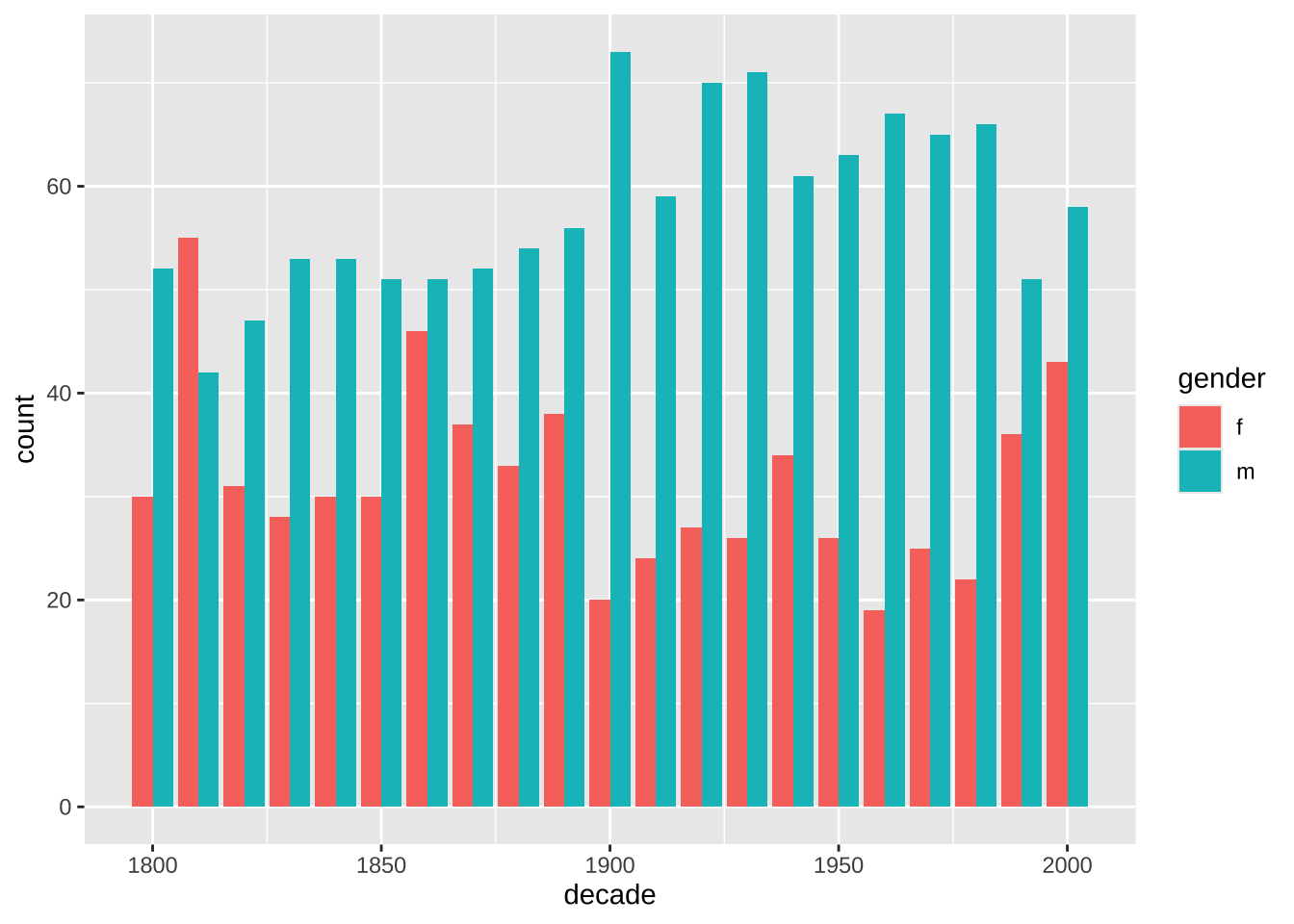
Сравните:
noveltm_new |>
ggplot(aes(decade, fill = gender)) +
geom_bar(position = "stack")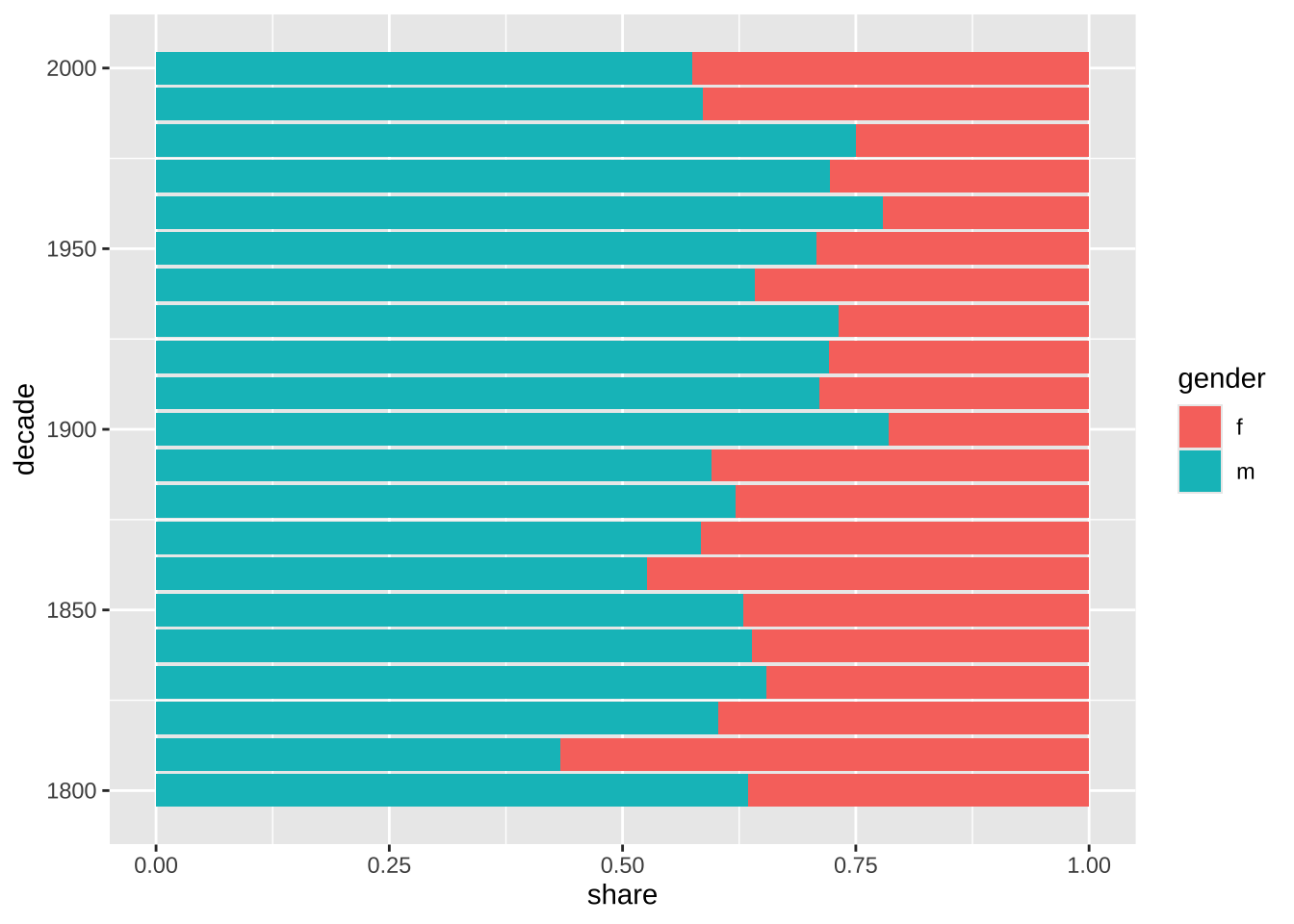
noveltm_new |>
ggplot(aes(decade, fill = gender)) +
geom_bar(position = "fill")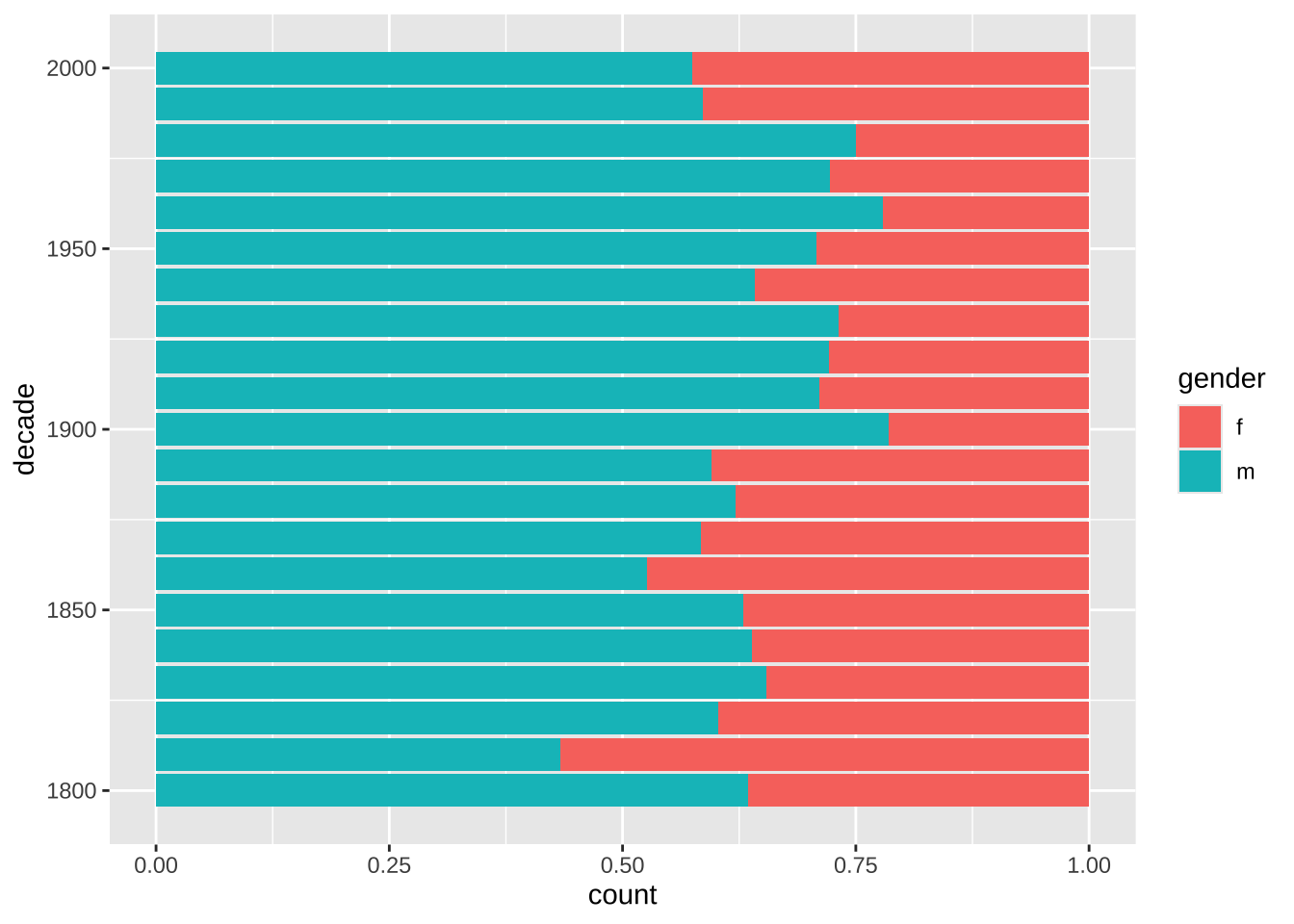
Долю женщин можно посчитать и отдельно.
noveltm_new_prop <- noveltm_new |>
add_count(decade, name = "total") |>
select(-inferreddate) |>
add_count(gender, decade, name = "counts") |>
distinct(gender, decade, counts, total) |>
mutate(share = counts / total)
noveltm_new_prop |>
print()# A tibble: 42 × 5
gender decade counts total share
<chr> <dbl> <int> <int> <dbl>
1 m 1890 56 94 0.596
2 m 1950 63 89 0.708
3 f 1970 25 90 0.278
4 m 1800 52 82 0.634
5 f 1820 31 78 0.397
6 m 1810 42 97 0.433
7 m 1870 52 89 0.584
8 m 1840 53 83 0.639
9 f 1810 55 97 0.567
10 f 1800 30 82 0.366
# ℹ 32 more rowsnoveltm_new_prop |>
# тот же график, но...
ggplot(aes(decade, share, fill = gender)) +
# тут просим ничего не считать, а брать что дают
geom_bar(stat = "identity") +
coord_flip() 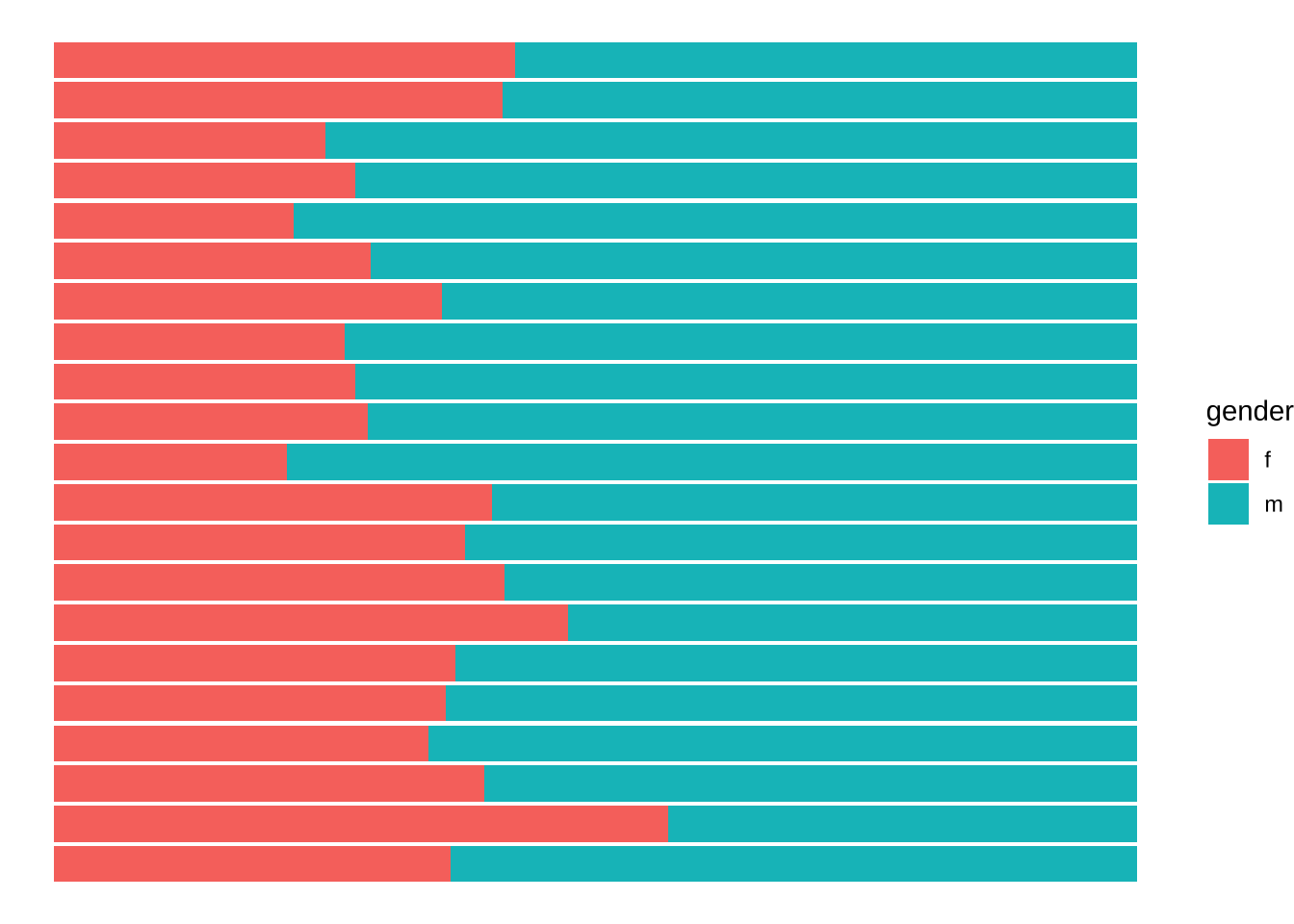
3.10 Информативный дизайн
Поскольку нас интересует доля женщин, логично поменять группы местами.
noveltm_new |>
ggplot(aes(decade, fill = gender)) +
# меняем местами группы
geom_bar(position = position_fill(reverse = TRUE)) +
coord_flip() +
# разные мелочи
ylab(NULL) +
xlab(NULL) +
theme_minimal()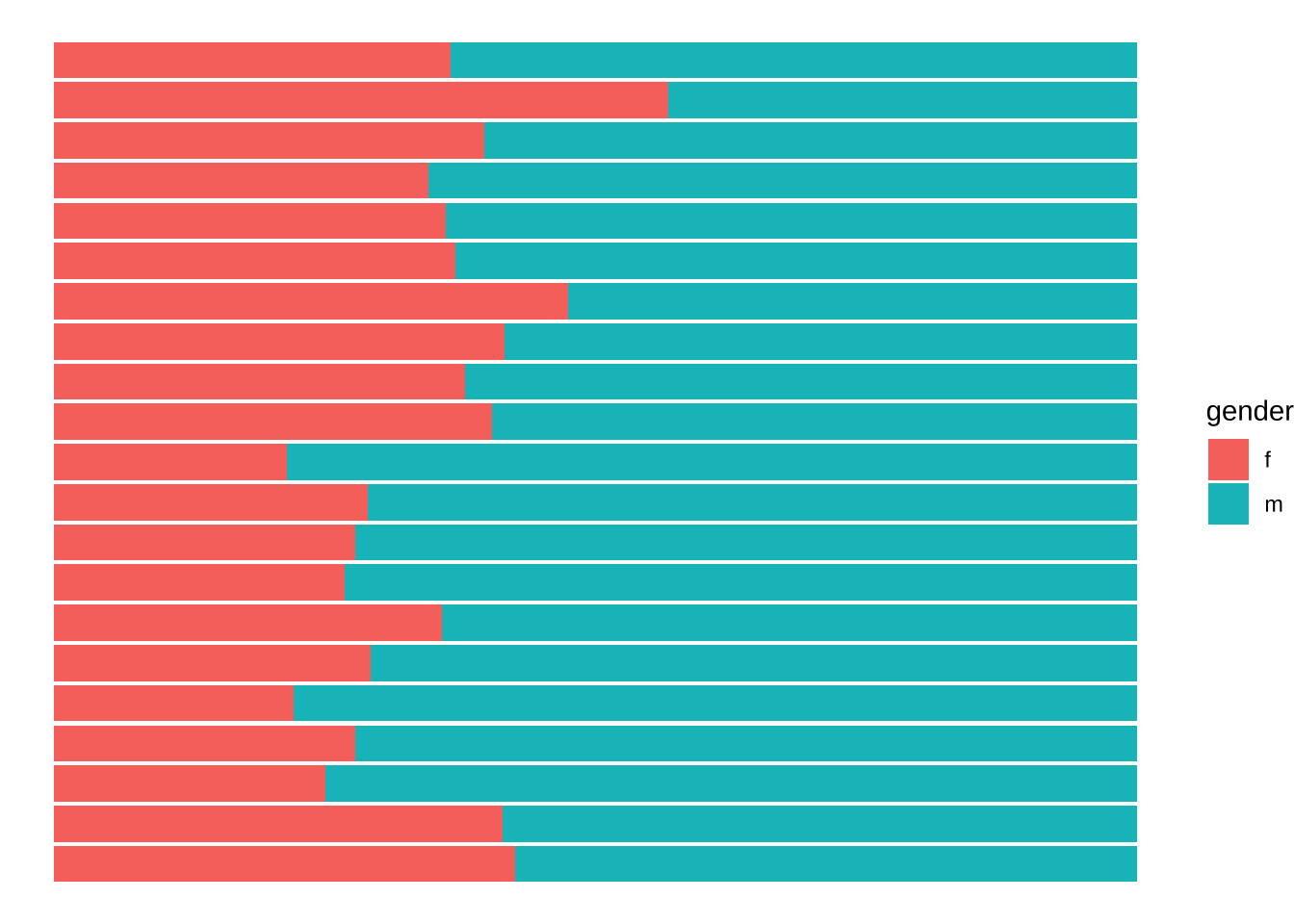
Также поменяем порядок, в котором идут декады (от меньшей к большей).
noveltm_new |>
ggplot(aes(decade, fill = gender)) +
geom_bar(position = position_fill(reverse = TRUE)) +
# меняем порядок лет
scale_x_reverse() +
coord_flip() +
ylab(NULL) +
xlab(NULL) +
theme_minimal()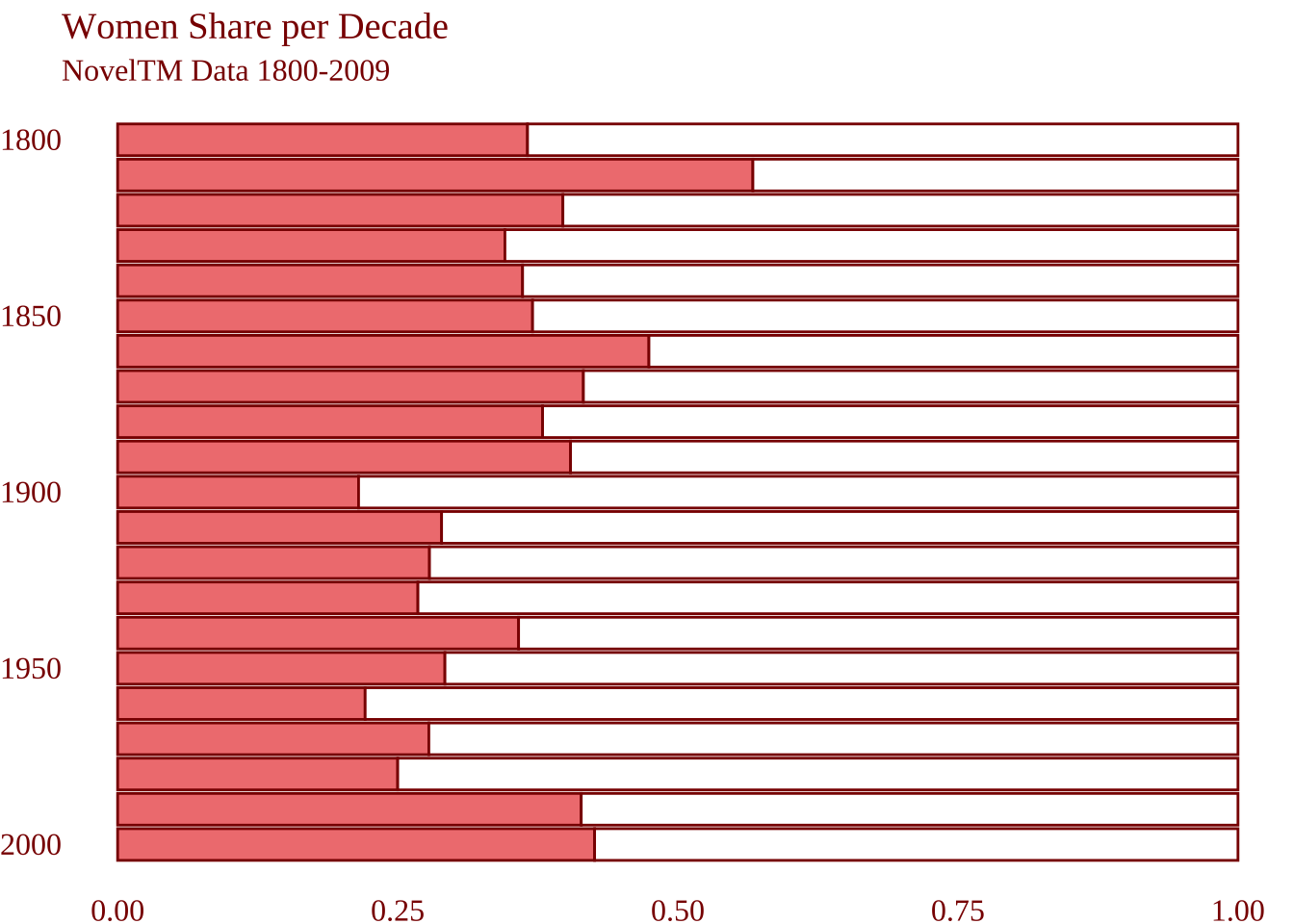
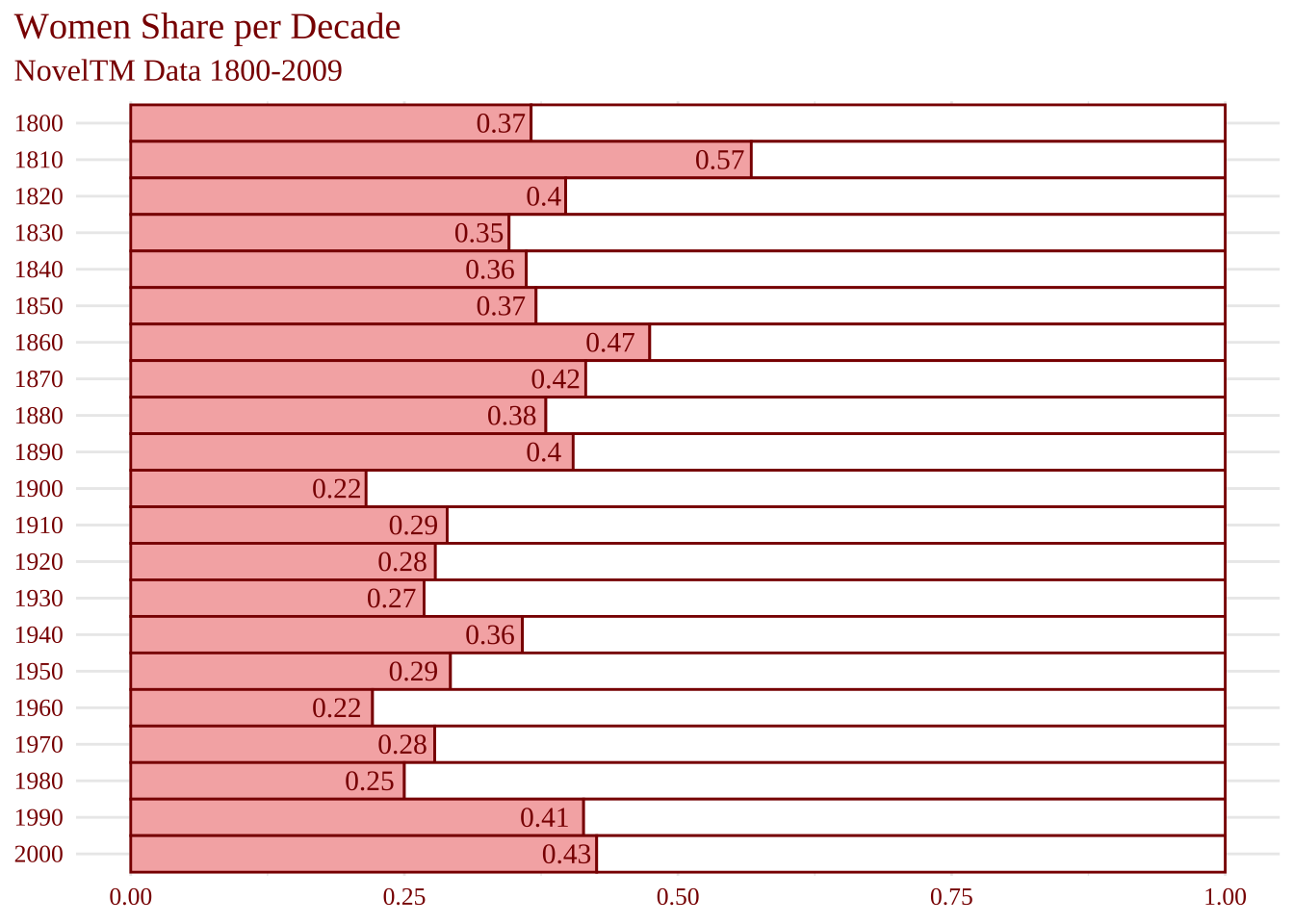
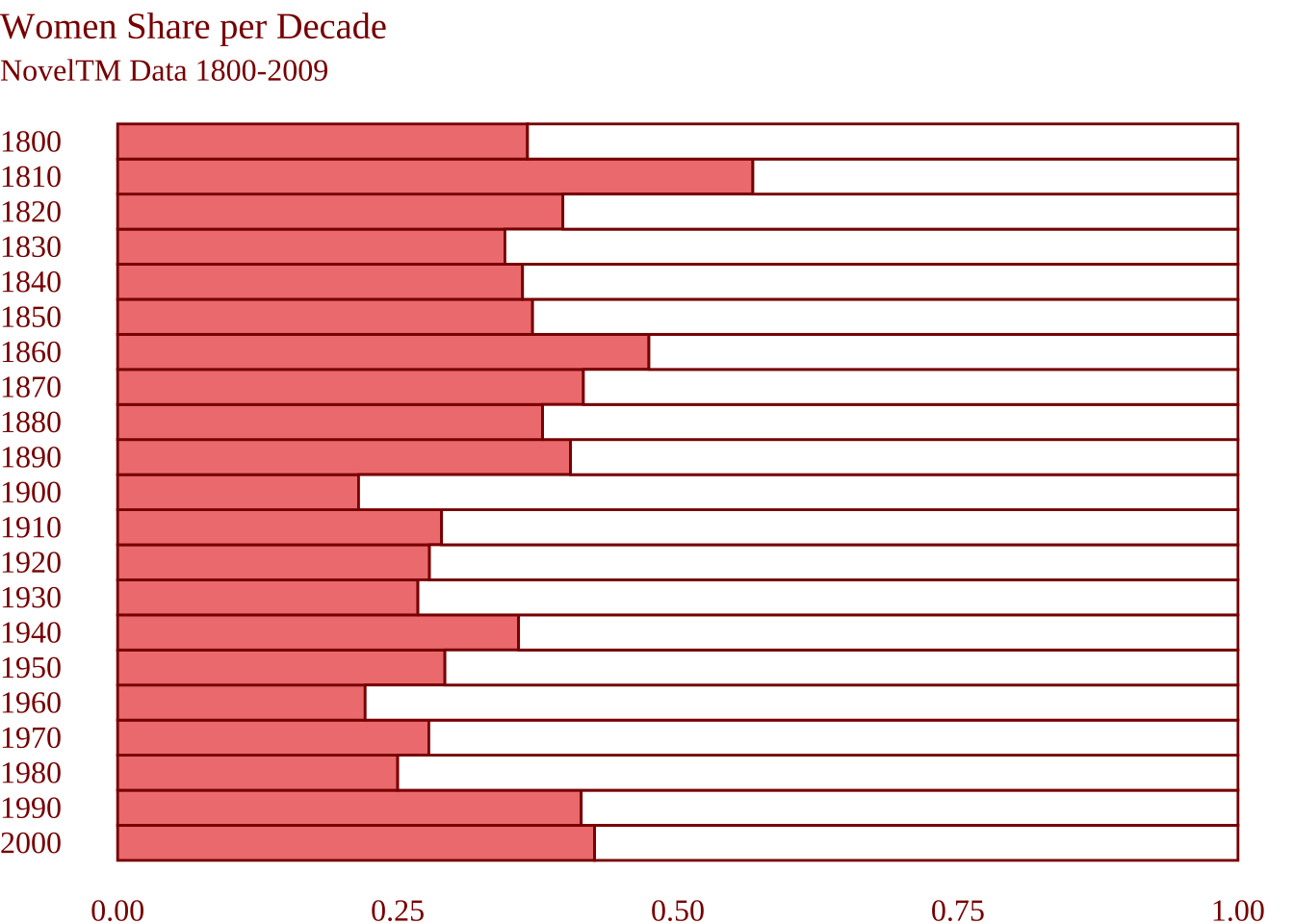
Убавим цвет в мужской части диаграммы и добавим заголовки.
noveltm_new |>
ggplot(aes(decade, fill = gender)) +
geom_bar(position = position_fill(reverse = TRUE),
# обводим столбики
color = "darkred",
# убираем легенду
show.legend = FALSE) +
scale_x_reverse() +
# беремся за палитру
scale_fill_manual(values = c("lightcoral", "white")) +
coord_flip() +
theme_minimal() +
labs(
x = NULL,
y = NULL,
title = "Women Share per Decade",
subtitle = "NovelTM Data 1800-2009"
) +
# меняем цвет и шрифт текста
theme(
text=element_text(size=12, family="serif", color = "darkred"),
axis.text = element_text(color = "darkred")
)
Стоит подвинуть заголовок и убрать просветы между столбцами.
# почти ничего нового!
noveltm_new |>
ggplot(aes(decade, fill = gender)) +
geom_bar(position = position_fill(reverse = TRUE),
color = "darkred",
show.legend = FALSE,
# столбик во всю ширину
width = 10
) +
# добавляем делений на оси
scale_x_reverse(breaks = seq(1800, 2000, 10)) +
scale_fill_manual(values = c("lightcoral", "white")) +
coord_flip() +
theme_void() +
labs(
x = NULL,
y = NULL,
title = "Women Share per Decade",
subtitle = "NovelTM Data 1800-2009"
) +
theme(
text=element_text(size=12, family="serif", color = "darkred"),
axis.text = element_text(color = "darkred"),
# выравниваем заголовок
plot.title.position = "plot"
)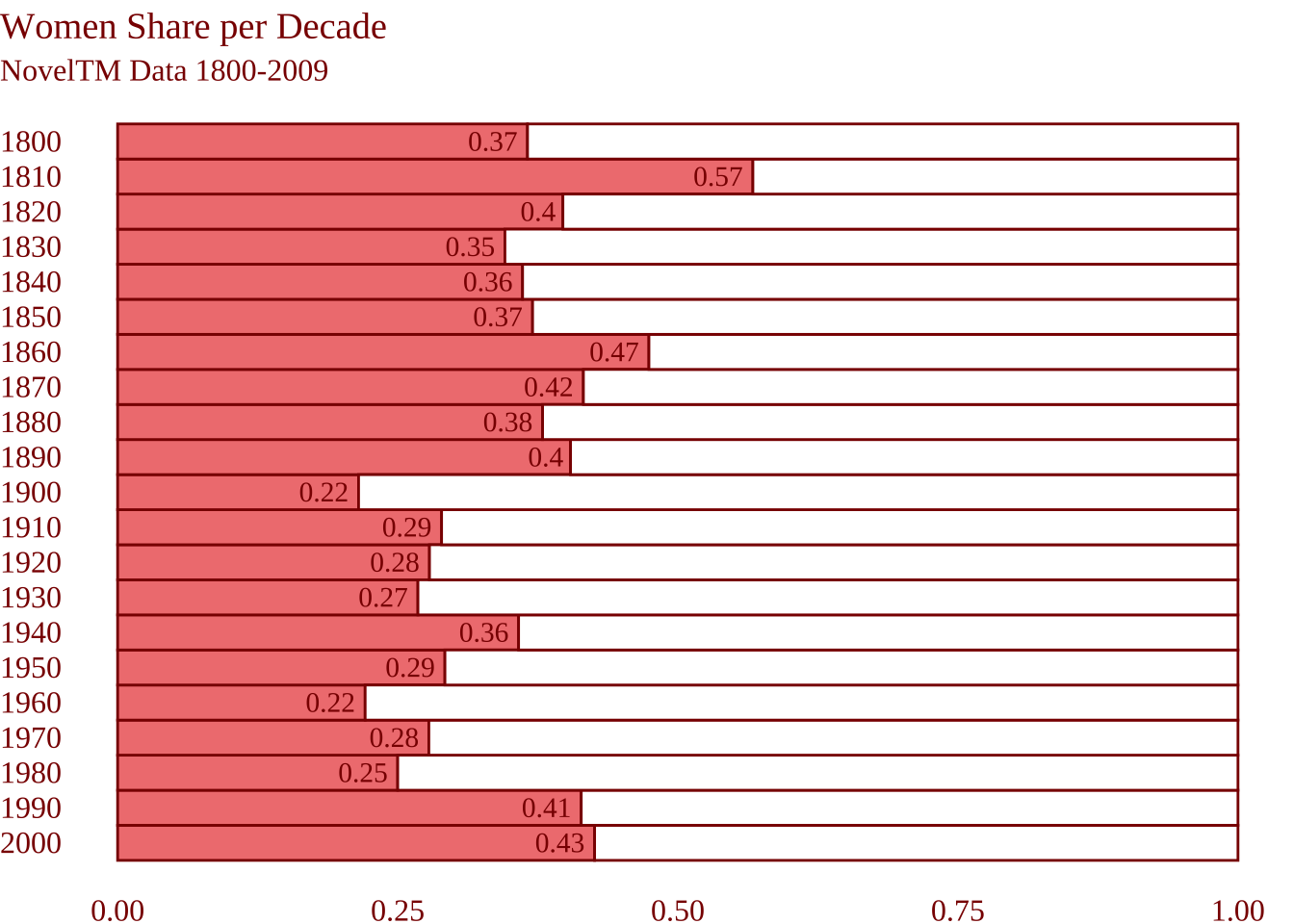
3.11 Подписи с geom_text()
Функции geom_text() можно передать таблицу, которую мы сделали выше и которая хранит сведения о доле женщин по декадам. Обратите внимание: у геомов могут быть разные данные!
label_data <- noveltm_new_prop |>
filter(gender == "f")
# тут все старое
noveltm_new |>
ggplot(aes(decade, fill = gender)) +
geom_bar(position = position_fill(reverse = TRUE),
color = "darkred",
show.legend = FALSE,
width = 10
) +
scale_x_reverse(breaks = seq(1800, 2000, 10)) +
scale_fill_manual(values = c("lightcoral", "white")) +
coord_flip() +
theme_void() +
labs(
x = NULL,
y = NULL,
title = "Women Share per Decade",
subtitle = "NovelTM Data 1800-2009"
) +
theme(
text=element_text(size=12, family="serif", color = "darkred"),
axis.text = element_text(color = "darkred"),
plot.title.position = "plot"
) +
# тут чуть-чуть нового
geom_text(data = label_data,
aes(label = round(share, 2),
y = share),
family = "serif",
hjust = 1.2,
color = "darkred")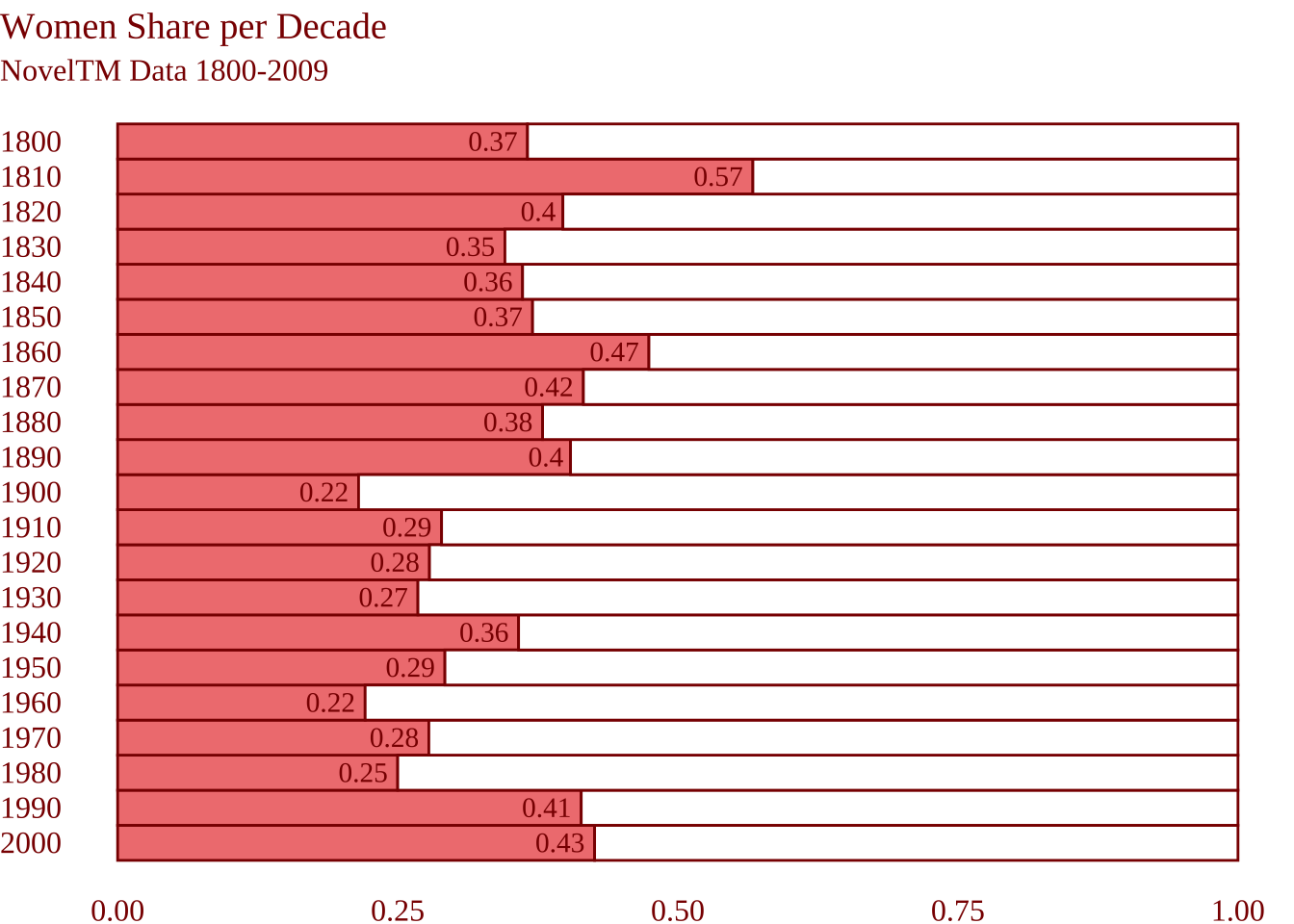
Отличная работа! Все сестры Бронте вами гордятся.
3.12 Экспорт графиков из среды R
Способы:
- реализованные в R драйверы стандартных графических устройств;
- функция
ggsave() - меню программы RStudio.
# код сохранит pdf в рабочую директорию
pdf(file = "plot.pdf")
g
dev.off()Еще один способ сохранить последний график из пакета ggplot2.
ggsave(
filename = "plot.png",
plot = last_plot(),
device = "png",
scale = 1,
width = NA,
height = 500,
units = "px",
dpi = 300
)3.13 Видео
3.14 Домашнее задание
Вам надо построить график к датасету “Старофрацузская литература”. Инструкции ниже; код и само изображение надо будет загрузить в GitHub Classroom (ссылка). Дедлайн: 3 октября 2025, 21-00 мск. Оценка: 0/1.
Сохраните файл скрипта под именем hw3.R.
library(languageR)
library(ggplot2)
# загружаем датасет
meta <- oldFrenchMeta
# допишите ваш код ниже
g <- meta |>
# постройте в ggplot столбиковую диаграмму (_bar),
# показывающую распределение произведений по темам; цветом-заливкой закодируйте жанр;
# уберите названия осей;
# добавьте заголовок "Old French Data"
# поверните координатную ось;
# поменяйте тему оформления на черно-белую (bw)
# !!!! сохраните график как объект в окружении под именем g
# !!!!вызов class(g) должен возвращать "gg" "ggplot"
Underwood, Ted. 2019. Distant Horizons: Digital Evidence and Literary Change. University of Chicago Press.
Wickham, Hadley, и Garrett Grolemund. 2016. R for Data Science. O’Reilly. https://r4ds.had.co.nz/index.html.
Мастицкий, Сергей. 2017. Визуализация данных с помощью ggplot2. ДМК.
С. Мастицкий и В. Шитиков. 2015. Статистический анализ и визуализация данных с помощью R. ДМК.