set.seed(07092024)
x = matrix(rnorm(50 * 2), ncol = 2)
x[1:25, 1:2] = x[1:25, 1:2] + 3
x[26:50, 1:2] = x[1:25, 1:2] - 415 Кластеризация и метод главных компонент
15.1 Виды кластерного анализа
Все методы машинного обучения делятся на методы обучения с учителем и методы обучения без учителя. В первом случае у нас есть некоторое количество признаков X, измеренных у n объектов, и некоторый отклик Y. Задача заключается в предсказании Y по X. Например, мы измерили вес и пушистость у сотни котов известных пород, и хотим предсказать породу других котов, зная их вес и пушистость.
Обучение без учителя предназначено для случаев, когда у нас есть только некоторый набор признаков X, но нет значения отклика. Например, есть группа котов, для которых мы измерили вес и пушистость, но мы не знаем, на какие породы они делятся.
Кластеризация относится к числу методов для обнаружения неизвестных групп (кластеров) в данных. Точнее, это целый набор методов. Мы рассмотрим два из них:
- кластеризация по методу K средних
- иерархическая кластеризация
В случае с кластеризацией по методу K средних мы пытаемся разбить наблюдения на некоторое заранее заданное число кластеров. Иерархическая кластеризация возвращает результат в виде дерева (дендрограммы), которая позволяет увидеть все возможные кластеры.
15.2 Кластеризация по методу K средних
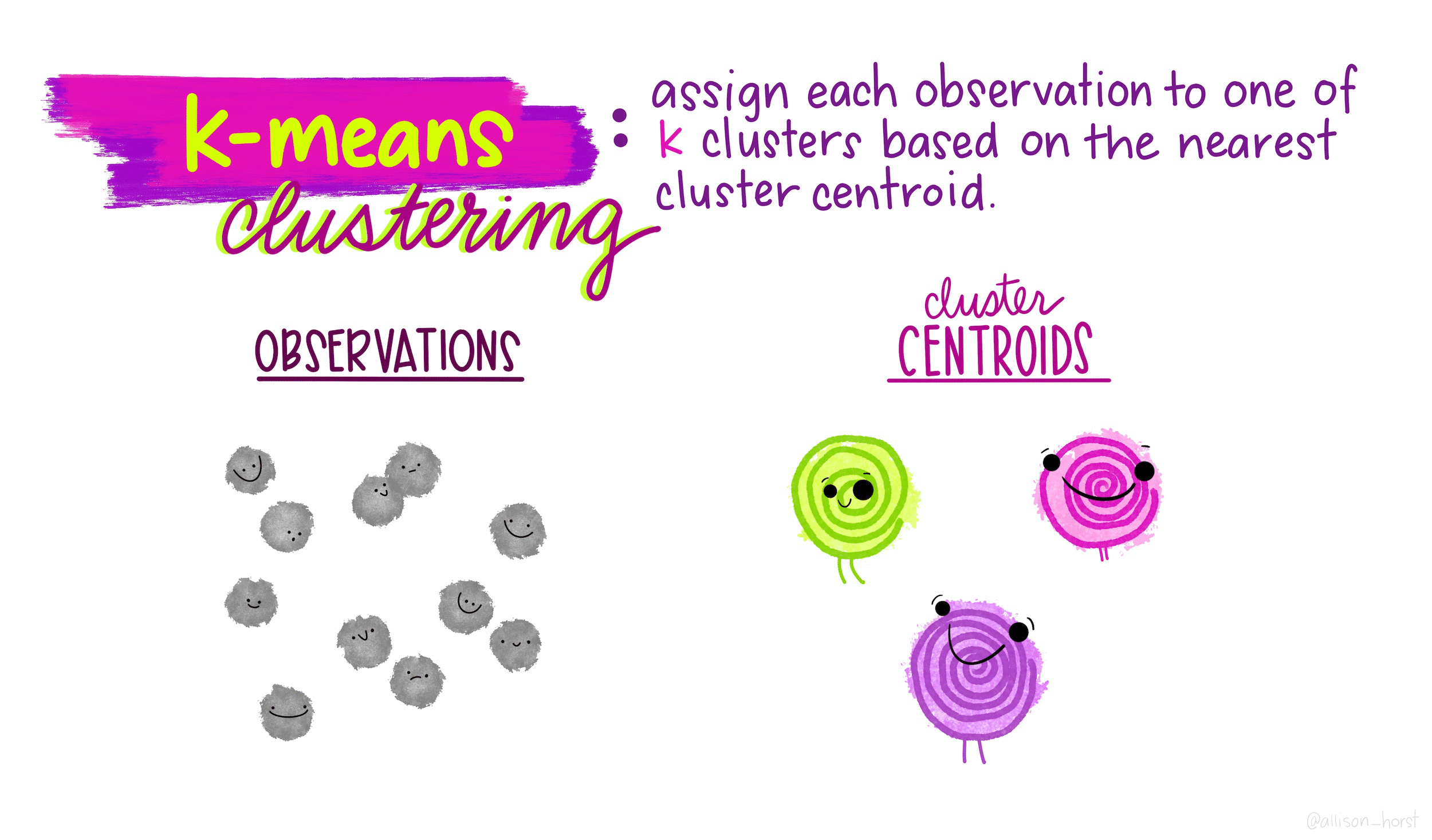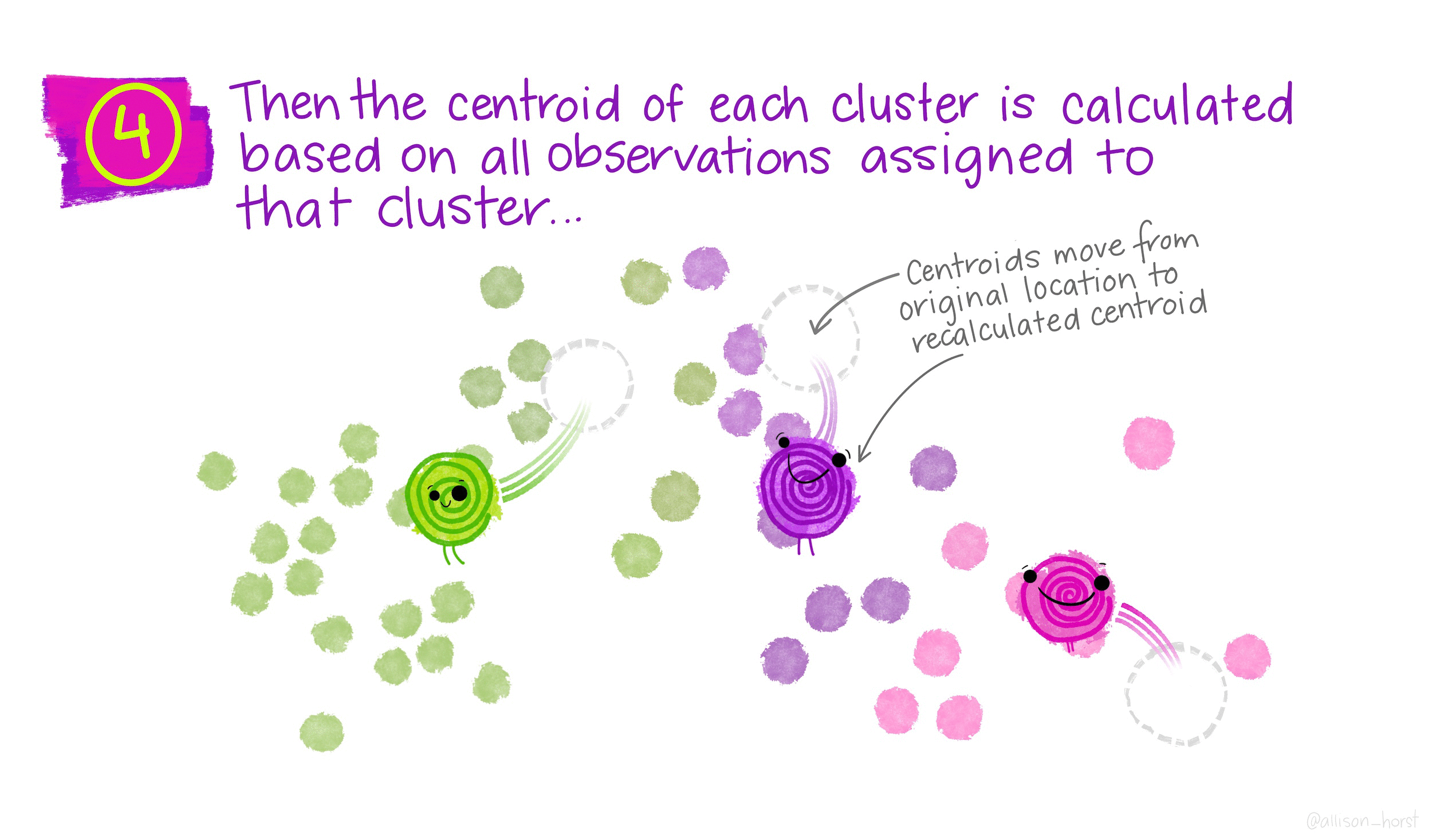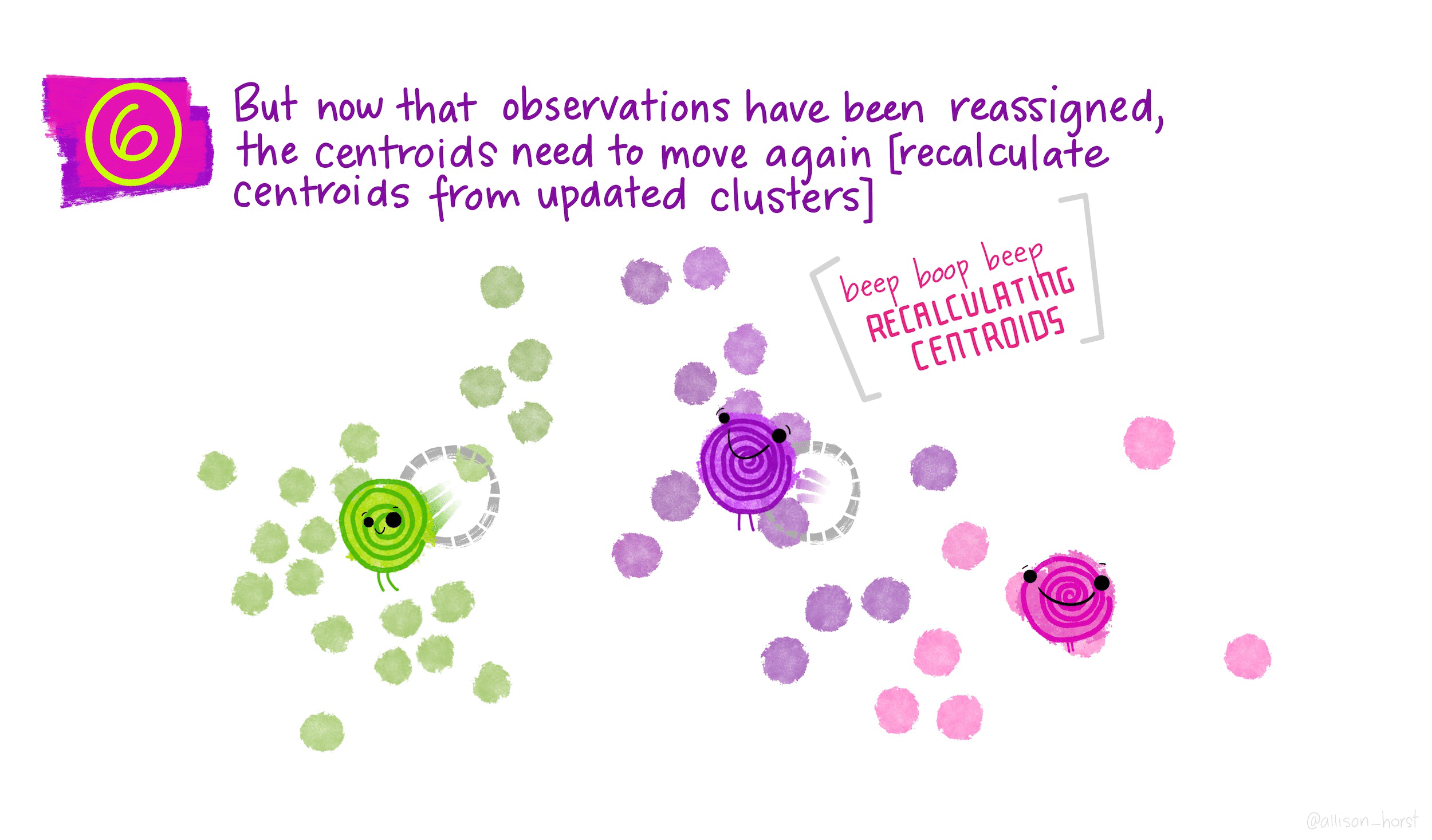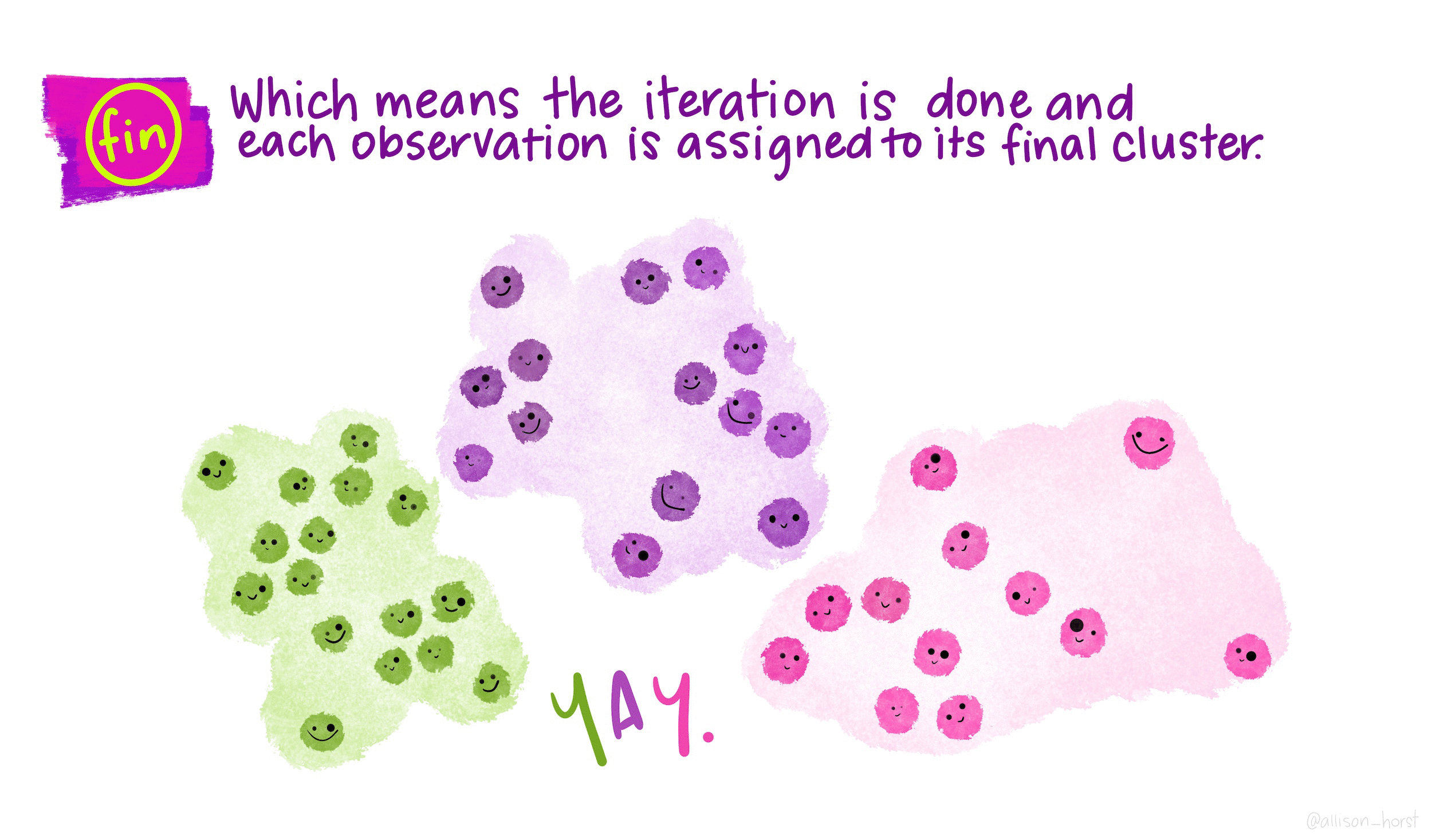
Алгоритм кластеризации:
- Каждому наблюдению присваивается случайно выбранное число из интервала от 1 до K (число кластеров). Это исходные метки.

Вычисляется центроид для каждого из кластеров. Центроид k-го класса – вектор из p средних значений признаков, описывающих наблюдения из этого кластера.
Каждому наблюдению присваивается метка того кластера, чей центроид находится ближе всего к этому наблюдению (удаленность выражается обычно в виде евклидова расстояния).
Шаги 2-3 до тех пор, пока метки классов не станут изменяться.
Это дает возможность минимизировать внутрикластерный разброс: хорошей считается такая кластеризация, при которой такой разброс минимален.
Когда центроиды двигаются, кластеры приобретают и теряют документы.
Внутрикластерный разброс в кластере k – это сумма квадратов евклидовых расстояний между всеми парами наблюдений в этом кластере, разделенная на общее число входящих в него наблюдений.
15.2.1 K-means в R
Рассмотрим это сначала на симулированных, а затем на реальных данных.
set.seed(123)
km.out <- kmeans(x, centers = 2, nstart = 20)
km.out$cluster [1] 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1
[39] 1 1 1 1 1 1 1 1 1 1 1 1Наблюдения разделились идеально. Вот так выглядят наши центроиды:
library(tidyverse)
as_tibble(x) |>
ggplot(aes(V1, V2, color = as.factor(km.out$cluster))) +
geom_point(show.legend = F) +
geom_point(data = as.data.frame(km.out$centers), color = "grey40", size = 3, alpha = 0.7) +
theme_light()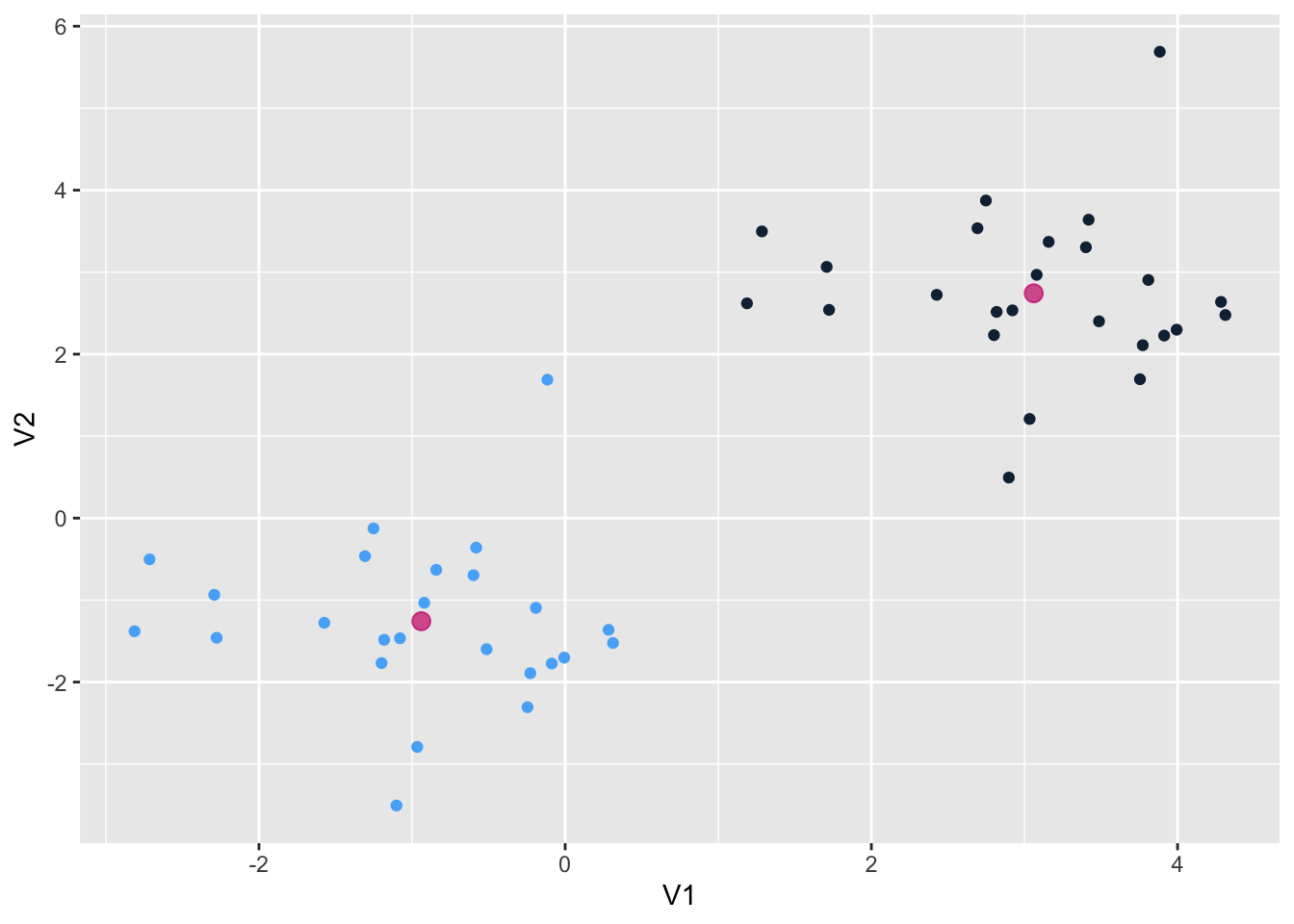
Аргумент nstart позволяет запустить алгоритм функции несколько раз с разными начальными метками кластеров; функция вернет наилучший результат.
15.2.2 Кластеризация текстов
Я воспользуюсь датасетом из пакета stylo, в котором хранятся частотности 3000 наиболее частотных слов для 26 книг 5 авторов. Один из этих авторов – таинственный Роберт Гэлбрейт, как выяснилось – псевдоним Джоан Роулинг.
library(stylo)
data("galbraith")
galbraith <- as.data.frame.matrix(galbraith) |>
select(1:150)
galbraith[1:10, 1:10] |>
knitr::kable()| the | and | to | of | a | was | I | in | he | said | |
|---|---|---|---|---|---|---|---|---|---|---|
| coben_breaker | 3.592199 | 1.175108 | 2.162724 | 1.375736 | 2.518600 | 1.502323 | 1.4450004 | 1.176302 | 0.8956614 | 0.9123804 |
| coben_dropshot | 3.587836 | 1.178543 | 2.122161 | 1.268598 | 2.375359 | 1.567476 | 1.4969982 | 1.040198 | 0.7543722 | 1.0023493 |
| coben_fadeaway | 3.931392 | 1.445498 | 2.200406 | 1.213045 | 2.306477 | 1.322501 | 1.3303995 | 1.198375 | 1.0415256 | 1.0234710 |
| coben_falsemove | 3.625411 | 1.613339 | 2.133533 | 1.236688 | 2.400991 | 1.375325 | 1.3458802 | 1.109094 | 0.8686264 | 0.9680031 |
| coben_goneforgood | 3.834031 | 1.816723 | 2.152941 | 1.175808 | 1.961908 | 1.732668 | 3.8139721 | 1.130915 | 0.6753014 | 0.8080692 |
| coben_nosecondchance | 4.098293 | 1.588967 | 2.271255 | 1.205863 | 1.992137 | 1.757715 | 3.8547491 | 1.151134 | 0.4323595 | 0.6476270 |
| coben_tellnoone | 4.101556 | 1.790136 | 2.030637 | 1.246342 | 2.176360 | 1.418129 | 3.4985250 | 1.162226 | 0.6302795 | 0.7783715 |
| galbraith_cuckoos | 4.523028 | 2.267404 | 2.494006 | 2.179397 | 2.141283 | 1.655510 | 1.1267723 | 1.380400 | 1.3270411 | 0.8281014 |
| lewis_battle | 5.050713 | 3.404538 | 2.138425 | 2.138425 | 1.959842 | 1.511093 | 0.9020766 | 1.284429 | 1.1722417 | 1.2249010 |
| lewis_caspian | 4.865472 | 3.591812 | 2.152883 | 2.144069 | 2.168308 | 1.352989 | 1.1150041 | 1.211961 | 0.8880368 | 1.5248672 |
Если одни признаки имеют больший разброс значений, чем другие, то при вычислении расстояний будут преобладать элементы с более широкими диапазонами. Поэтому перед применением алгоритма в некоторых случаях рекомендуется нормализовать данные по Z-оценке: из значения признака Х вычитается среднее арифметическое, а результат разделить на стандартное отклонение Х. Это делает функция scale().
\[ X_{new} = \frac{X - Mean(X)}{StDev(X)}\]
set.seed(07092024)
km.out <- kmeans(scale(galbraith), centers = 5, nstart = 20)
km.out$cluster coben_breaker coben_dropshot coben_fadeaway
3 3 3
coben_falsemove coben_goneforgood coben_nosecondchance
3 3 3
coben_tellnoone galbraith_cuckoos lewis_battle
3 4 5
lewis_caspian lewis_chair lewis_horse
5 5 5
lewis_lion lewis_nephew lewis_voyage
5 5 5
rowling_casual rowling_chamber rowling_goblet
4 2 2
rowling_hallows rowling_order rowling_prince
2 2 2
rowling_prisoner rowling_stone tolkien_lord1
2 2 1
tolkien_lord2 tolkien_lord3
1 1 expected <- str_remove_all(names(km.out$cluster), "_.*")
tibble(expected = expected,
predicted = km.out$cluster) |>
group_by(expected) |>
count(predicted) |>
knitr::kable()| expected | predicted | n |
|---|---|---|
| coben | 3 | 7 |
| galbraith | 4 | 1 |
| lewis | 5 | 7 |
| rowling | 2 | 7 |
| rowling | 4 | 1 |
| tolkien | 1 | 3 |
Почти все авторы разошлись по разным кластерам (кроме Роулинг), при этом Гэлбрейт в одном кластере с Роулинг. Результат кластеризации по методу k-средних можно визуализировать в двумерном пространстве, прибегнув к методу главных компонент.
Задание
Загрузите датасет с пингвинами и кластеризуйте пингвинов по методу k-средних, используя любые два признака. Сравните результаты с нормализацией и без. Используйте разные наборы признаков. Выберите наилучший результат. Визуализируйте кластеры и раскрасьте их по видам пингвинов.
library(palmerpenguins)
penguins <- penguins15.3 Метод главных компонент
15.3.1 PCA: общий смысл
Метод главных компонент (англ. principal component analysis, PCA) — один из основных способов уменьшить размерность данных, потеряв наименьшее количество информации. Этот метод привлекается, в частности, когда надо визуализировать многомерные данные.
Общий принцип хорошо объясняет Гаральд Баайен (Baayen 2008, 119).
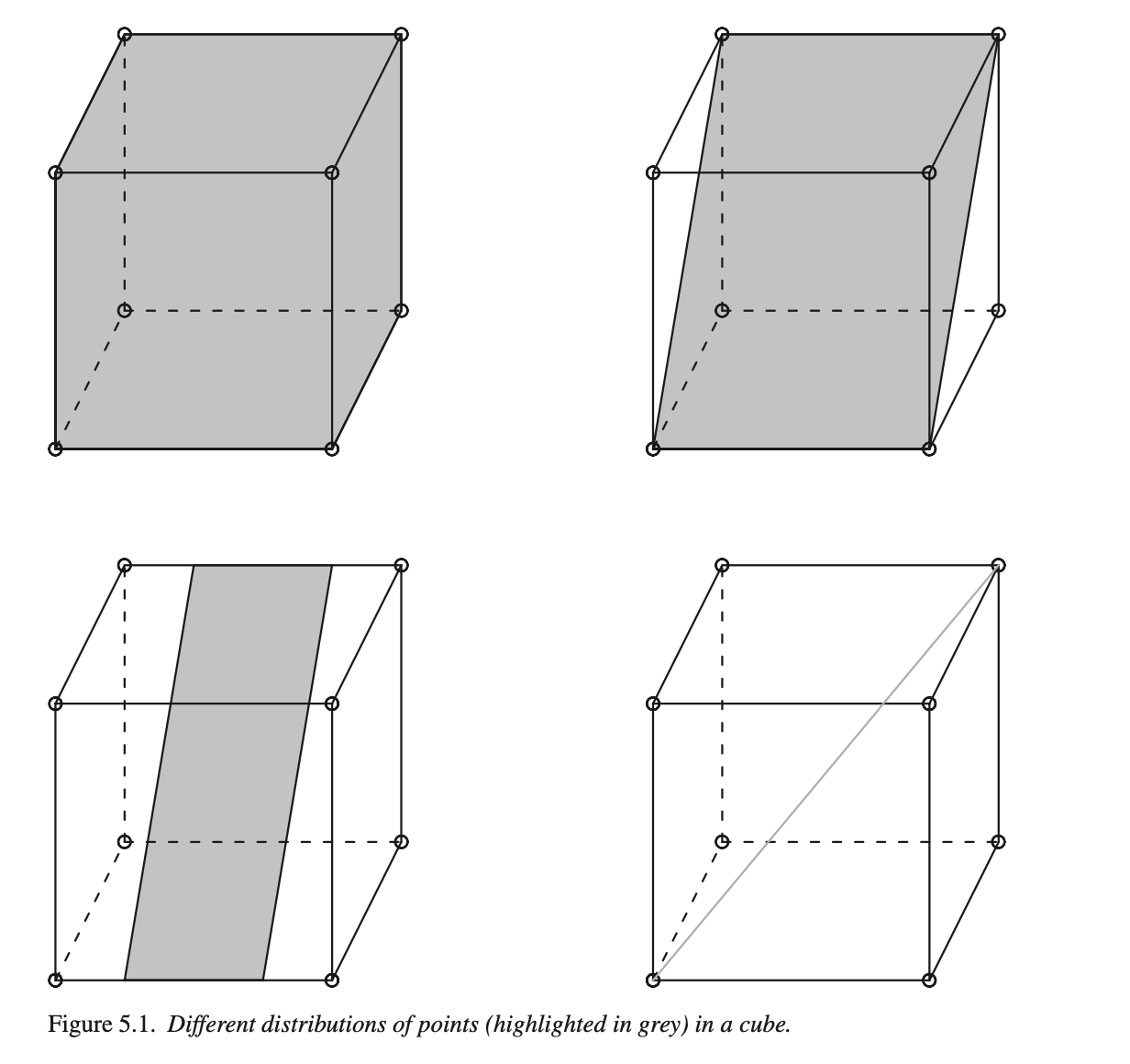
Серый цвет верхнего левого куба означает, что точки распределены равномерно – нужны все три измерения для того, чтобы описать положение точки в кубе. Куб справа сверху по-прежнему имеет три измерения, но нам достаточно только двух, вдоль которых рассеяны данные. Куб слева снизу тоже имеет два измерения, но вдоль оси y разброс данных меньше, чем вдоль x. Наконец, для куба справа снизу достаточно только одного измерения.
Метод главных компонент ищет такие измерения, вдоль которых наблюдается наибольший разброс данных, причем каждая следующая компонента будет объяснять меньше разброса.
15.3.2 PCA в базовом R
pca_fit <- prcomp(galbraith, scale. = TRUE, center = TRUE)
names(pca_fit)[1] "sdev" "rotation" "center" "scale" "x" Первый элемент хранит данные о стандартном отклонении, соответствующем каждой компоненте.
round(pca_fit$sdev, 3) [1] 7.100 5.586 4.055 3.147 2.891 2.318 1.799 1.720 1.691 1.653 1.385 1.345
[13] 1.293 1.259 1.230 1.137 1.074 1.034 0.927 0.904 0.833 0.812 0.753 0.738
[25] 0.612 0.000Это можно узнать также, вызвав функцию summary.
summary(pca_fit)Importance of components:
PC1 PC2 PC3 PC4 PC5 PC6 PC7
Standard deviation 7.1000 5.5857 4.0551 3.14673 2.89110 2.31817 1.79909
Proportion of Variance 0.3361 0.2080 0.1096 0.06601 0.05572 0.03583 0.02158
Cumulative Proportion 0.3361 0.5441 0.6537 0.71971 0.77543 0.81126 0.83283
PC8 PC9 PC10 PC11 PC12 PC13 PC14
Standard deviation 1.71973 1.69124 1.65255 1.38483 1.34501 1.29297 1.25850
Proportion of Variance 0.01972 0.01907 0.01821 0.01279 0.01206 0.01115 0.01056
Cumulative Proportion 0.85255 0.87162 0.88983 0.90261 0.91467 0.92582 0.93637
PC15 PC16 PC17 PC18 PC19 PC20 PC21
Standard deviation 1.22957 1.13749 1.07351 1.03397 0.92701 0.90422 0.83317
Proportion of Variance 0.01008 0.00863 0.00768 0.00713 0.00573 0.00545 0.00463
Cumulative Proportion 0.94645 0.95508 0.96276 0.96989 0.97562 0.98107 0.98570
PC22 PC23 PC24 PC25 PC26
Standard deviation 0.8121 0.75291 0.73778 0.6122 6.667e-15
Proportion of Variance 0.0044 0.00378 0.00363 0.0025 0.000e+00
Cumulative Proportion 0.9901 0.99387 0.99750 1.0000 1.000e+00Таким образом, первые две компоненты объясняют почти половину дисперсии, а последняя почти не имеет объяснительной ценности.
plot(pca_fit)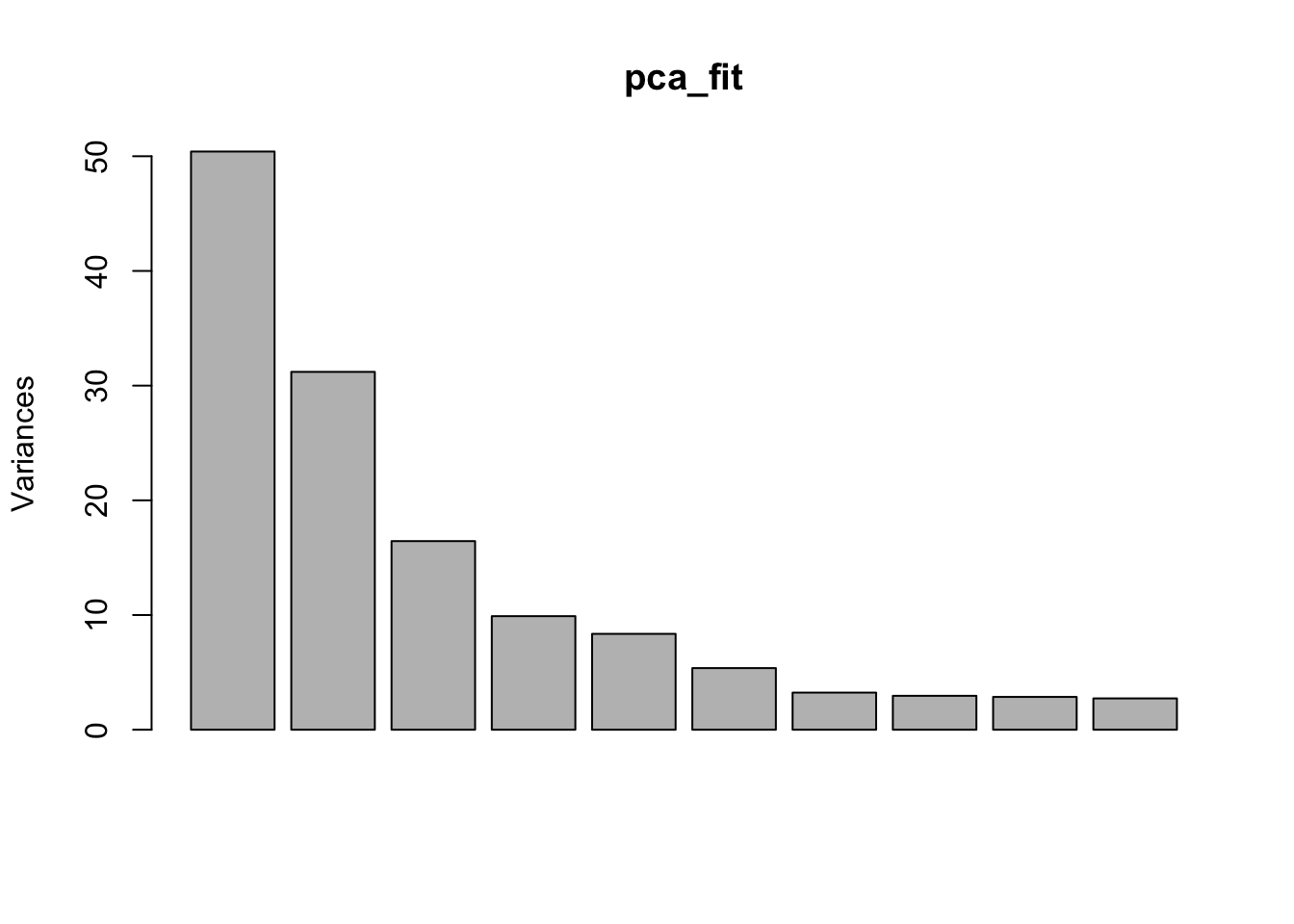
Координаты текстов в новом двумерном пространстве, определяемом первыми двумя компонентами, хранятся в элементе под названием x.
pca_fit$x[,1:2] PC1 PC2
coben_breaker -8.757336 4.352396
coben_dropshot -9.459904 5.276560
coben_fadeaway -8.964170 4.572739
coben_falsemove -8.738214 4.707646
coben_goneforgood -8.113474 7.115332
coben_nosecondchance -6.783907 7.946904
coben_tellnoone -7.779098 5.535273
galbraith_cuckoos -3.828020 -5.113776
lewis_battle 8.179671 2.898561
lewis_caspian 6.991680 3.005847
lewis_chair 6.743976 3.867256
lewis_horse 6.451278 2.783159
lewis_lion 6.281176 2.401030
lewis_nephew 5.682845 4.443366
lewis_voyage 7.947284 3.612055
rowling_casual -1.807538 -6.273038
rowling_chamber -3.168879 -7.780693
rowling_goblet -2.249544 -8.491719
rowling_hallows -1.350855 -7.684606
rowling_order -2.364382 -7.381456
rowling_prince -1.366061 -6.124957
rowling_prisoner -3.373330 -9.270778
rowling_stone -3.152846 -5.291951
tolkien_lord1 10.392543 0.650889
tolkien_lord2 10.799804 1.429537
tolkien_lord3 11.787300 -1.18557715.3.3 PCA и кластеры K-means
Функция augment() из пакета {broom} позволяет соединить результат анализа с исходными данными.
library(broom)
pca_fit |>
augment(galbraith) |>
mutate(expected = str_remove_all(.rownames, "_.+")) |>
ggplot(aes(.fittedPC1, .fittedPC2,
color = expected,
shape = as.factor(km.out$cluster))) +
geom_point(size = 3, alpha = 0.7) +
scale_color_discrete(name = "автор") +
scale_shape_discrete(name = "кластер") +
theme_minimal()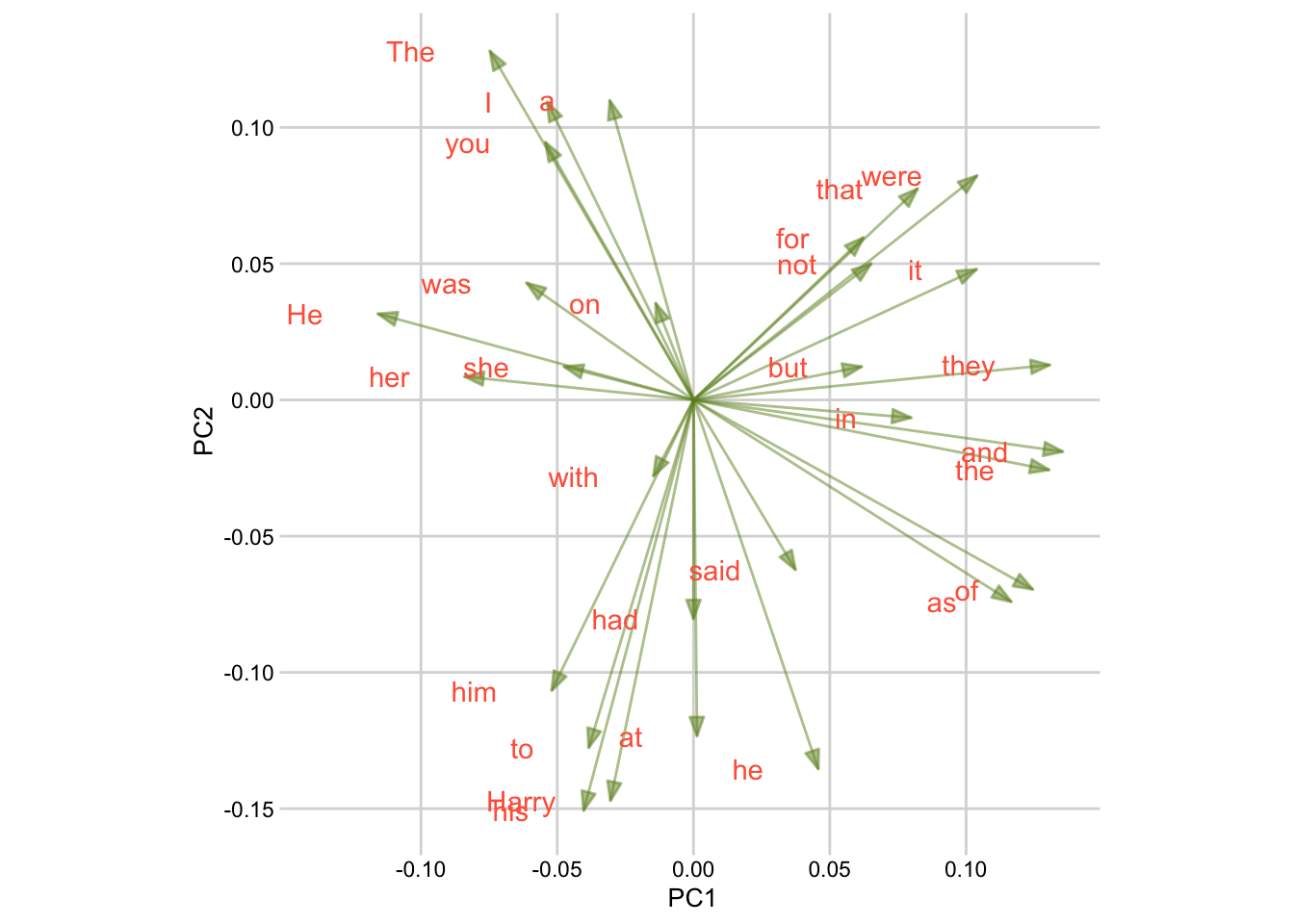
Еще один способ представить наблюдения.
# install.packages("FactoMineR")
# install.packages("factoextra")
library(FactoMineR)
library(factoextra)
fviz_pca_ind(pca_fit, geom = c("text"),
habillage = as.factor(km.out$cluster),
addEllipses = TRUE) +
theme(legend.position = "none")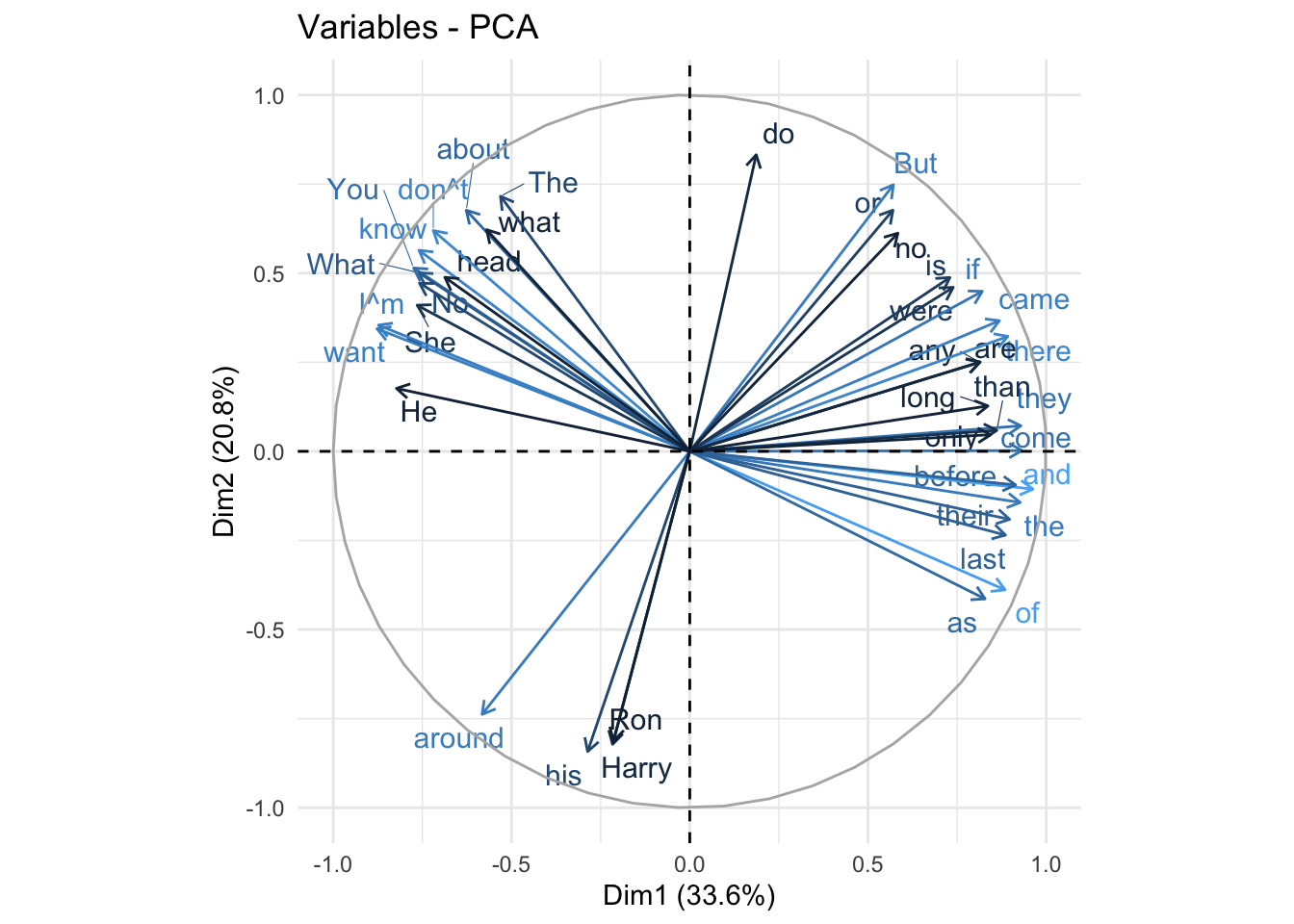
Аналогично можно представить и нагрузки компонент.
fviz_pca_var(pca_fit, col.var="contrib",
select.var = list(contrib = 40),
repel = TRUE)+
theme_minimal() +
theme(legend.position = "none")
При интерпретации этого графика следует учитывать, что положительно коррелированные переменные находятся рядом, а отрицательно коррелированные переменные находятся в противоположных квадрантах. Например, для первого измерения “his” и “as” коррелированы отрицательно. Это можно проверить, достав матрицу c нагрузками компонент из объекта pca_fit (в качестве координат используются коэффициенты корреляции между переменными и компонентами):
pca_fit$rotation[c("his", "as"),1:2] PC1 PC2
his -0.04033987 -0.15077917
as 0.11665675 -0.07410514Теперь - наблюдения и переменные на одном графике.
fviz_pca_biplot(pca_fit, geom = c("text"),
select.var = list(cos2 = 40),
habillage = as.factor(km.out$cluster),
col.var = "steelblue",
alpha.var = 0.3,
repel = TRUE,
ggtheme = theme_minimal()) +
theme(legend.position = "none")
Поработать над оформлением такого графика вы сможете в домашнем задании.
Задание
Проведите PCA-анализ датасета с пингвинами.
15.4 Видео
15.5 Домашнее задание
Дедлайн: 30 января 20-59.
Оценивание: 0/1
Данные, подробные инструкции и заготовку для скрипта вы найдете в репозитории. Репозиторий надо клонировать (создать новый локальный проект под контролем версий), отредактировать скрипт согласно инструкции (не переименовывайте файл и переменные!), запушить изменения.
Проверка автоматическая, обычно занимает до 20 минут, выполняется после каждого коммита / пуша. При повторных коммитах должно быть быстрее за счет кэширования, но все равно не стоит на последний момент все откладывать.
Можно пушить сколько угодно раз до дедлайна. В случае прохождения всех тестов (после обновления страницы) вы увидите зеленую галочку.
Почему это не быстро? Потому что GitHub Actions при каждой проверке запускает “чистую” виртуальную машину (как правило, Ubuntu), где установлены только базовые вещи типа R, Python и т.д.
Если тесты не пройдены, напротив коммита будет красный крест.
- Вы можете пройти на вкладку Actions (см. фото выше), найти там свой коммит (вы же его как-то назвали, помните?) и посмотреть ошибку. После исправления ошибки сделайте новый коммит.
Вот так выглядит вкладка Actions. Желтый цвет означает, что workflow в работе.
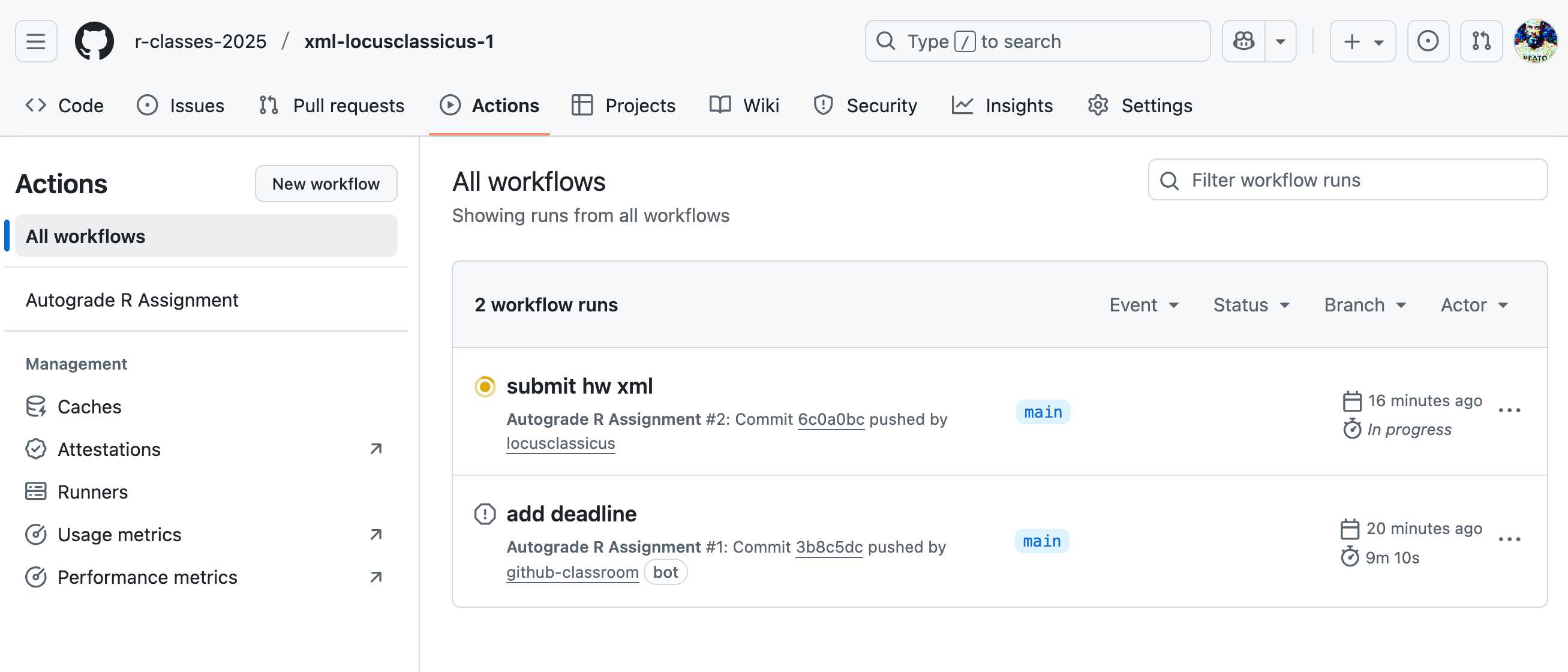
Если нажать на конкретный коммит -> test -> Run tests, можно увидеть детали проверки.
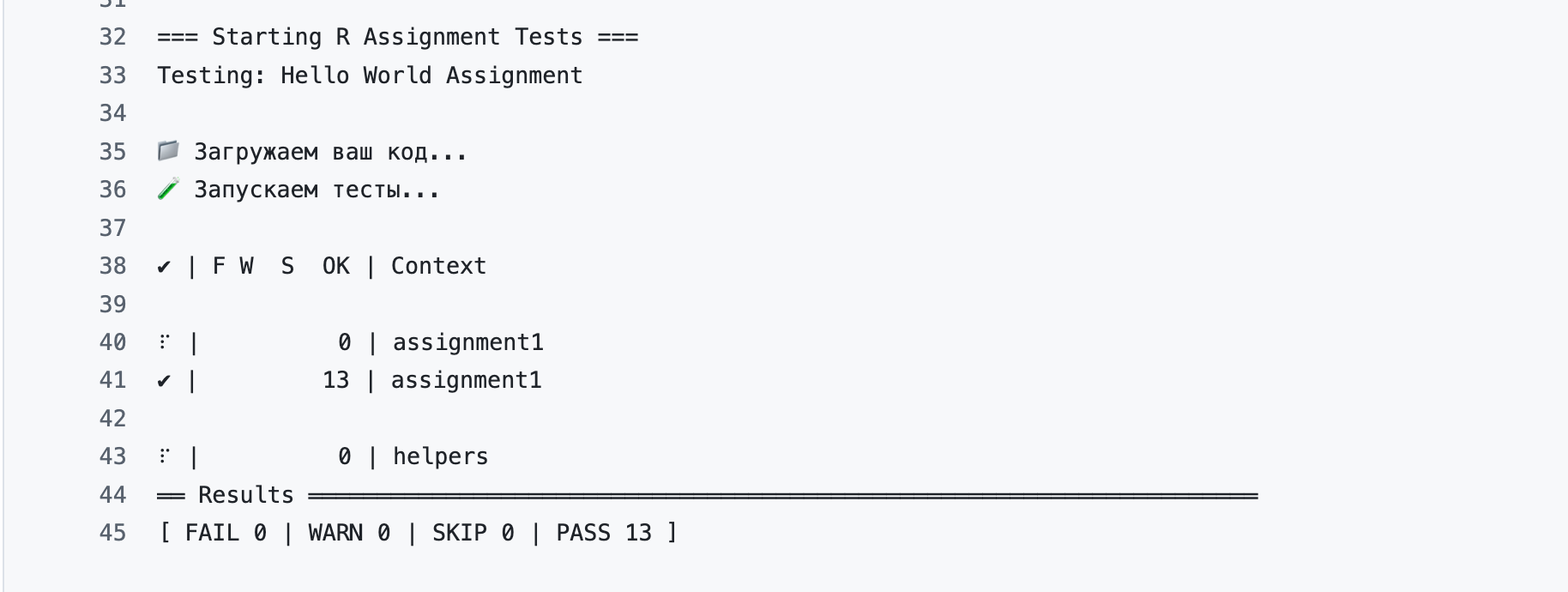
Внимательно читайте сообщения об ошибках! Их можно и нужно показывать LLM (например, DeepSeek), которые помогут доработать код.
Ваша задача: добиться прохождения всех тестов! В противном случае задание не засчитывается.
Дополнительный челленж (не оценивается) — оформить биплот как на картинке.
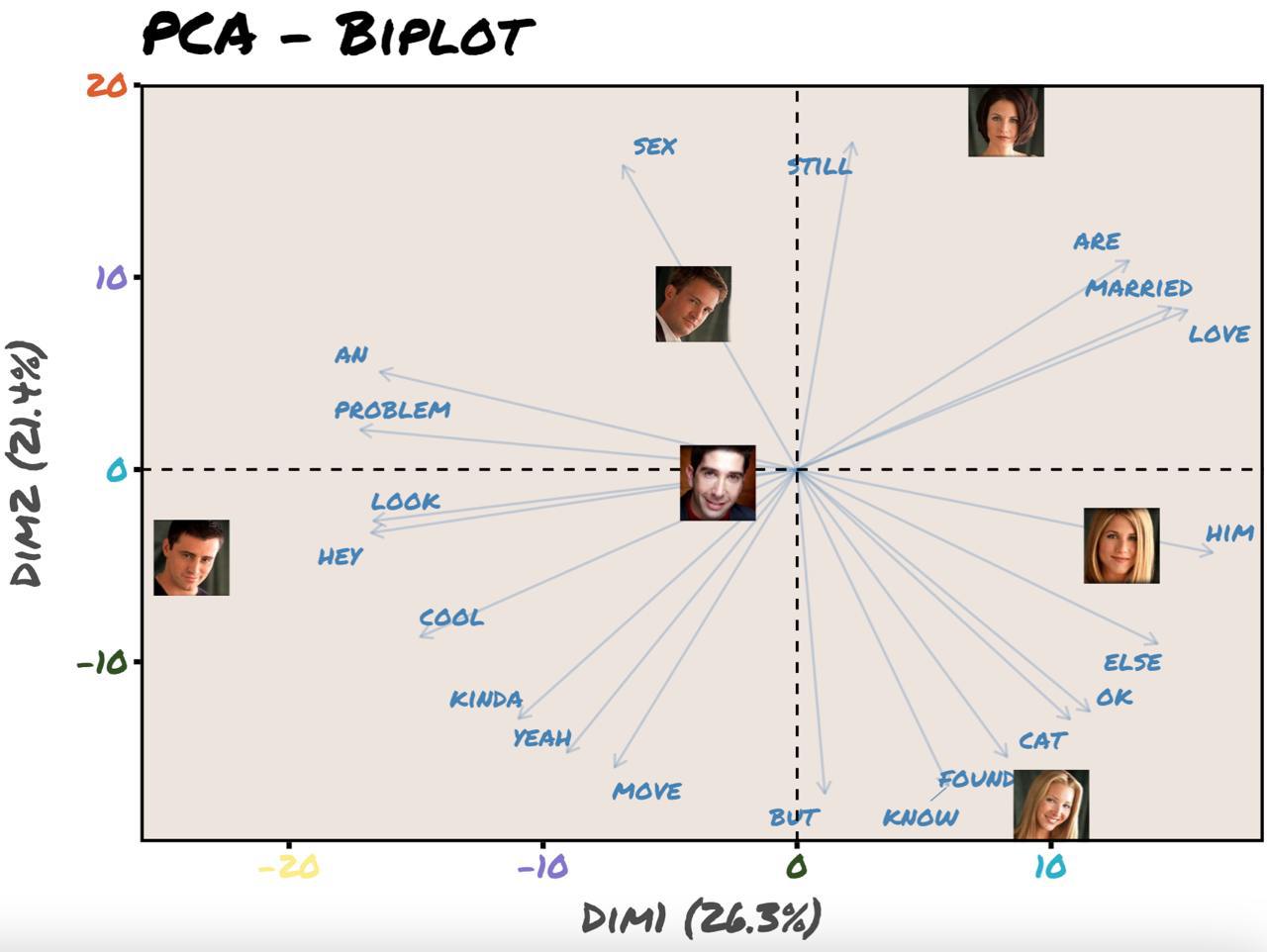
Вот некоторые подсказки, как это сделать, а необходимые изображения вы найдете в репозитории.
- весь текст шрифтом “Permanent Marker” от Google Fonts;
- вместо геома
textиспользуйтеimage; - координаты передаются в отдельном слое, его можно добавить через
+как в обычном{ggplot2}; - передайте
geom_image()координаты каждого персонажа; - тема
theme_friends()из пакета{ThemePark}.
library(showtext)
font_add_google("Permanent Marker", family = "friends")
showtext_auto()
# install.packages("remotes")
#remotes::install_github("MatthewBJane/ThemePark")
library(ThemePark)
library(ggimage)
pca_coords <- # здесь ваш код
# здесь ваш код
Baayen, R. H. 2008. Analyzing Linguistic Data: A Practical Introduction to Statistics using R. Cambridge University Press.