В этом уроке мы рассмотрим возможности стилометрического анализа с использованием пакета {stylo}. К пакету прилагается внятный HOWTO.
library(stylo)
### stylo version: 0.7.5 ###
If you plan to cite this software (please do!), use the following reference:
Eder, M., Rybicki, J. and Kestemont, M. (2016). Stylometry with R:
a package for computational text analysis. R Journal 8(1): 107-121.
<https://journal.r-project.org/archive/2016/RJ-2016-007/index.html>
To get full BibTeX entry, type: citation("stylo")
Возможности этого инструмента мы исследуем на корпусе древнегреческой литературы, подробнее о котором можно прочитать в препринте (upd.: опубликованная версия). Для этого эксперимента корпус был немного урезан и разложен по папкам. Корпус в формате .zip надо забрать по ссылке и сделать рабочей директорией.
Тексты могут быть на любом языке, но обязательно в кодировке Unicode.
На Mac может потребоваться поставить XQuartz.
16.2stylo()
Главная рабочая лошадка этого пакета – функция stylo(). Если вызвать ее без аргументов, то запустится GUI (который можно отключить).
stylo()
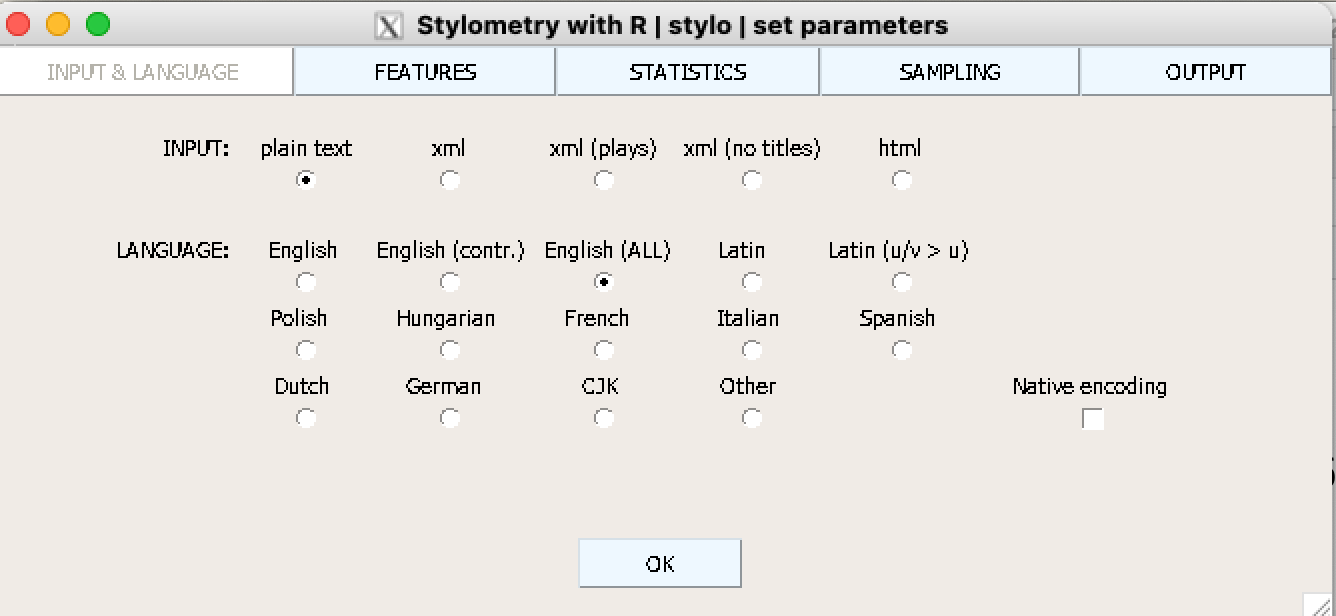
На вкладке Input & Language выбираете формат файла и язык.
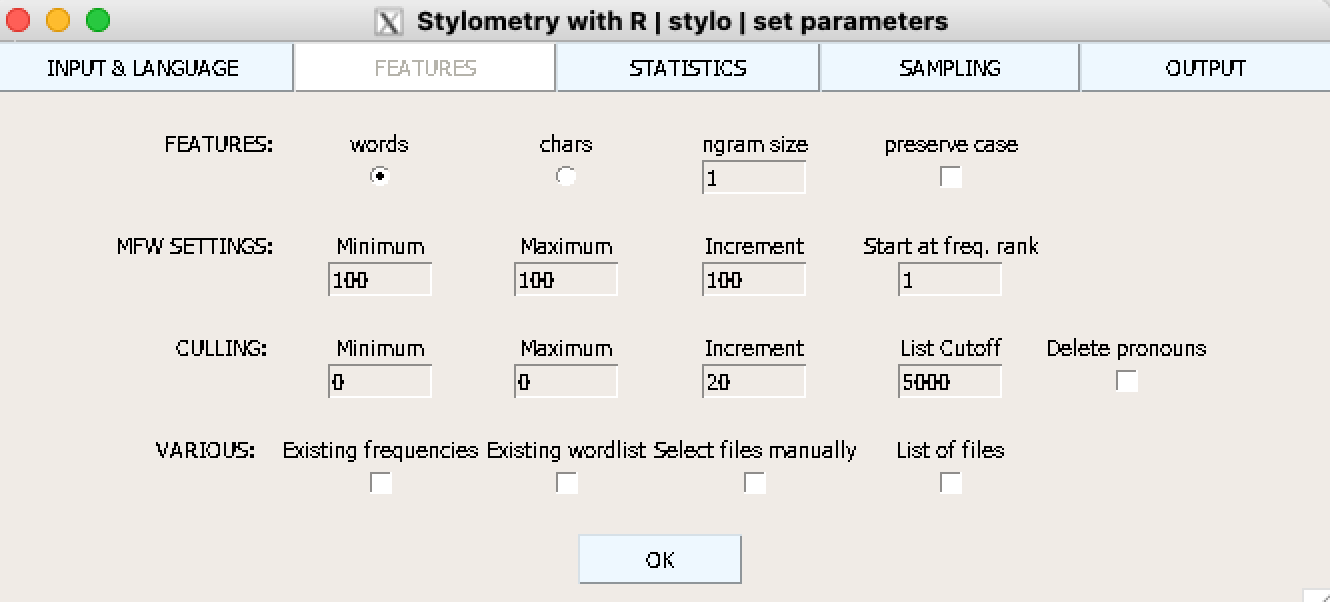
На вкладке Features указываете, как разбивать текст: на слова, символы, словесные или символьные энграмы. Также можно уточнить, что делать с прописными буквами (в нашем случае это нерелевантно). Параметр MFW указывает, сколько слов использовать для анализа. CULLING задает порог отсечения для слов: 20 означает, что будут использованы слова, которые встречаются как минимум в 20% текстов, 0 – все слова, 100 - только те, которые есть во всех текстах корпуса.
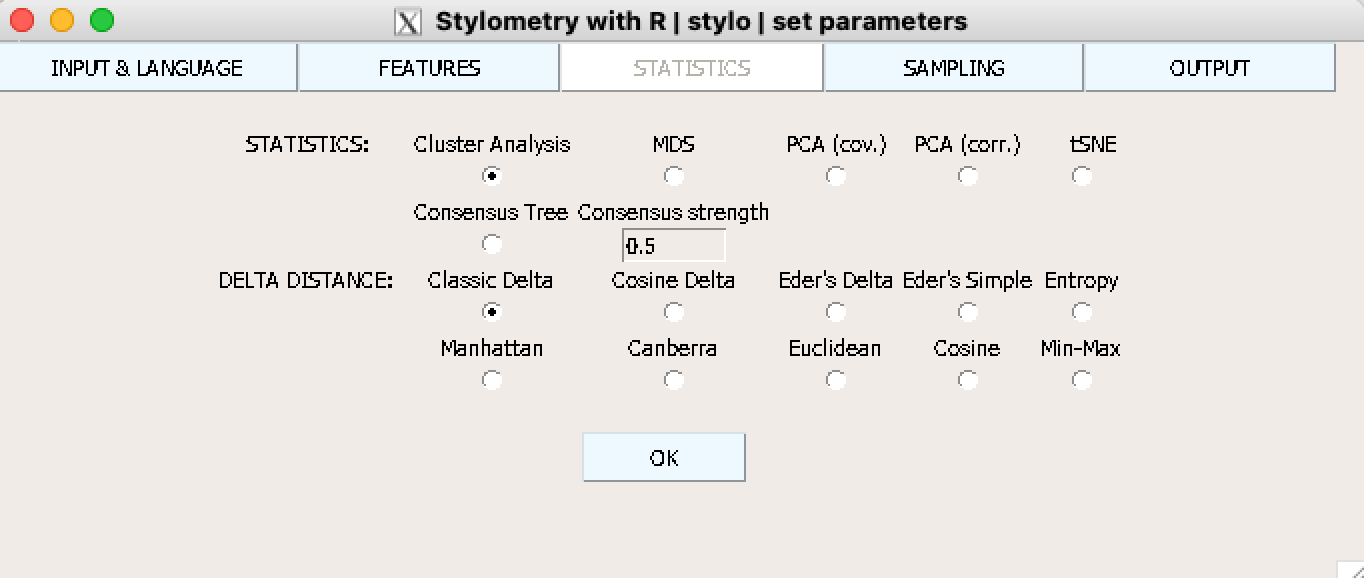
Следующая вкладка определяет метод, который будет использоваться для анализа.
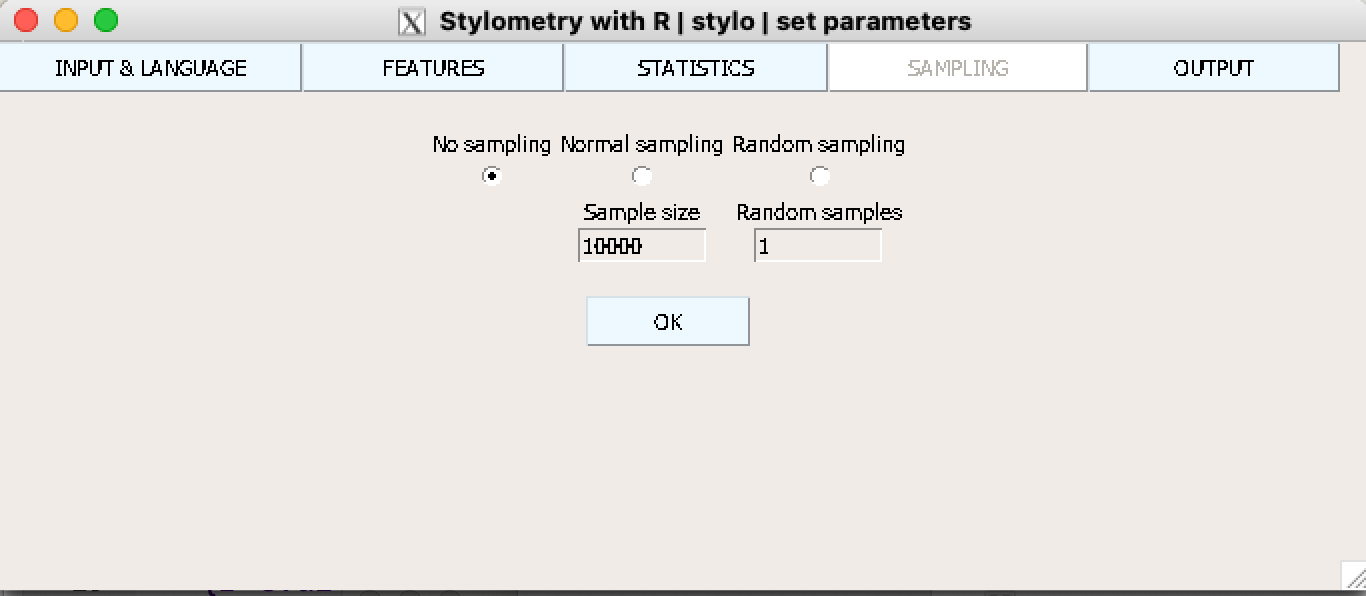
Можно также уточнить метод выборки.
И, наконец, формат, в котором следует вернуть результат.
Без графического интерфейса команда будет выглядеть так.
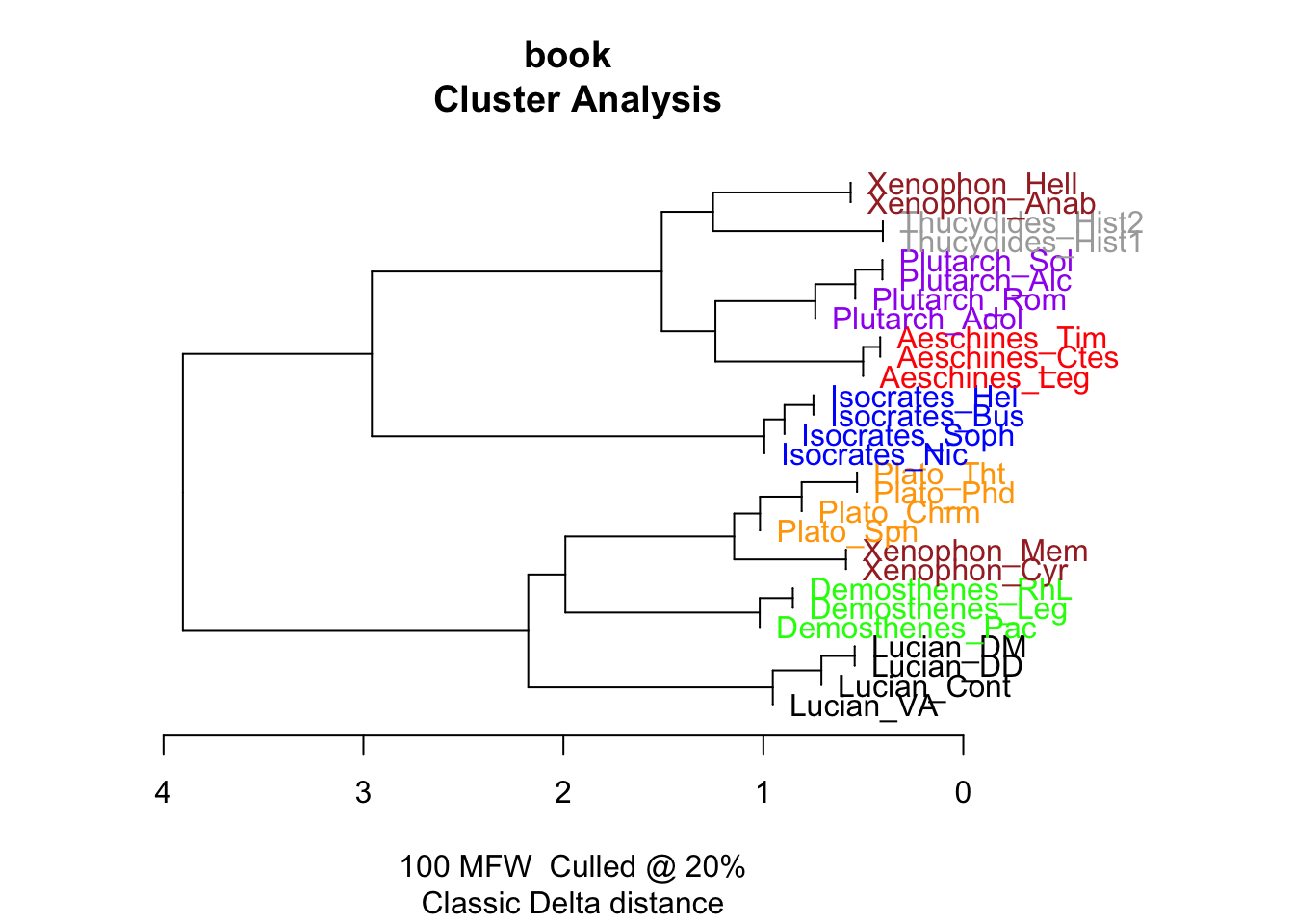
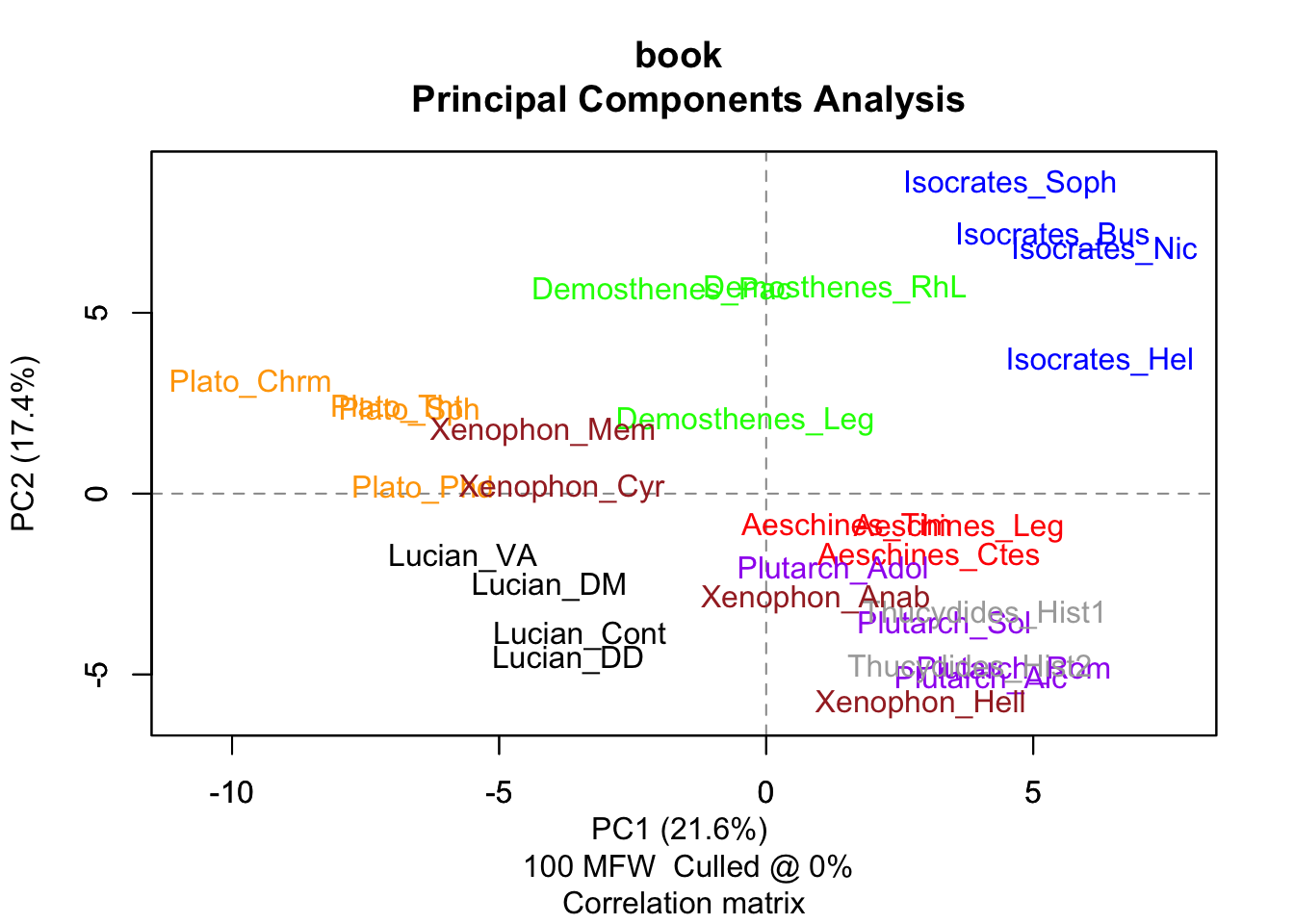
Подписи и цвета функция подбирает автоматически. Попробуйте использовать другие меры расстояния и другие статистические методы, и сравните результат (пока можно не обращать внимания на Consensus Tree – об этом поговорим на следующем занятии). После каждого запуска функции в рабочей директории сохраняются файлы с конфигурацией, признаками, которые использовались для анализа и, опционально, визуализация.
Delta Берроуза – это мера стилистической близости между текстами. Метод был предложен в 2001 году австралийским филологом Джоном Бёрроузом. С тех пор дельту используют во многих исследованиях, большая часть которых посвящена установлению авторства различных произведений.
Суть метода заключается в том, что для корпуса текстов рассчитывается частотность ряда признаков; это могут быть слова (словоформы) или так называемые n-граммы, то есть последовательности n символов подряд. Для сравнения берутся самые частотные слова, среди которых будет значительная доля служебных, в наименьшей степени связанных с тематикой текста (предлоги, союзы, частицы и т.п.). Поскольку сравниваемые тексты, как правило, имеют разную длину, в стилометрических исследованиях принято брать для сравнения относительную, а не абсолютную частотность; Берроуз идет еще дальше, предлагая использовать так называемые z-scores, то есть стандартизированные оценки, показывающие разброс значений относительно средних. Z-score вычисляется по формуле:
\[Ζ =\frac{x-\mu}{sd}\]
Здесь случайная величина \(x\) — это значение частотности, \(μ\) — математическое ожидание (среднее), а \(sd\) — стандартное отклонение. Иными словами, z-score показывает, на сколько стандартных отклонений x отстоит от ожидаемого. Зная z-scores для заданных слов у известных авторов/текстов, можно сравнить их с z-scores спорного текста; искомая дистанция Delta вычисляется как сумма взятых по модулю разниц между z-scores у двух сравниваемых текстов, поделенная на количество слов:
где i – конкретное слово, n – общее число слов, а A и B – сравниваемые авторы (знак | указывает, что суммируется абсолютное значение разницы). Чем больше дистанция, тем менее вероятно авторство.
Простота метода позволяет использовать его в традиционных методах обучения без учителя, таких как кластерный анализ, так и с машинно-обучаемыми классификаторами, когда для каждого значения предиктора \(x_i\) имеется значение отклика \(y_i\). Это позволяет, имея показатели предикторов, прогнозировать отклик, то есть, в нашем примере, определять наиболее вероятного автора. Количество классов формально не ограничено: мы можем сравнивать спорные тексты (test set) как с двумя, так и с двадцатью кандидатами, которые включаются в обучающую выборку (training set).
Пакет stylo дает возможность работать не только с классической Delta, но и с ее вариациями, из которых заслуживает внимание т.н. “вюрцбургская Delta”. В отличие от Delta Берроуза, она использует не манхэттенское, а косинусное расстояние, что во многих случаях позволяет повысить точность классификации. Подробнее о разных расстояниях (на примере древнегреческого корпуса) см. препринт. Upd. 2026: Ссылка на публикацию.
16.4classify()
Если stylo() возвращает результат, который должен интерпретировать человек, то classify() используется для машинного обучения с учителем. Вызов функции без аргументов вернет GUI, похожий на тот, что мы видели выше. Отличие будет на вкладке “Статистика”.
Среди доступных методов классификации: Delta, k-NN, SVM, Наивный Байес, метод ближайших центроидов. Подробнее о них мы будем говорить позже, а пока можно поэкспериментировать с Delta.
Перед запуском функции необходимо создать в рабочей директории две папки: primary_set и secondary_set (они есть в архиве, который вы уже скачали). В первой находится так называемые обучающие данные, во второй - тестовые (контрольные) данные. Обычно это тексты неизвестного авторства, но к ним можно добавить и несколько произведений известного авторства для дополнительного контроля. Мы примем за спорные отрывок из “Греческой истории” Ксенофонта, диалог “Софист” Платона, “Наблюдателей” Лукиана и “Против софистов” Исократа.
После того, как функция вернет управление, в рабочей директории появится несколько файлов, среди них – final_results.txt. В нашем случае успех 100%, но не стоит переоценивать этот результат: пример был совсем игрушечный. О подводных камнях поговорим в модуле про машинное обучение.
Теперь попробуйте поэкспериментировать с разными методами и настройками.
16.5samplesize.penalize()
Одна из известных проблем стилометрии связана с тем, что любые метрики плохо работают на небольших отрывках. Но какого размера должен быть текст, чтобы мы могли установить его автора?
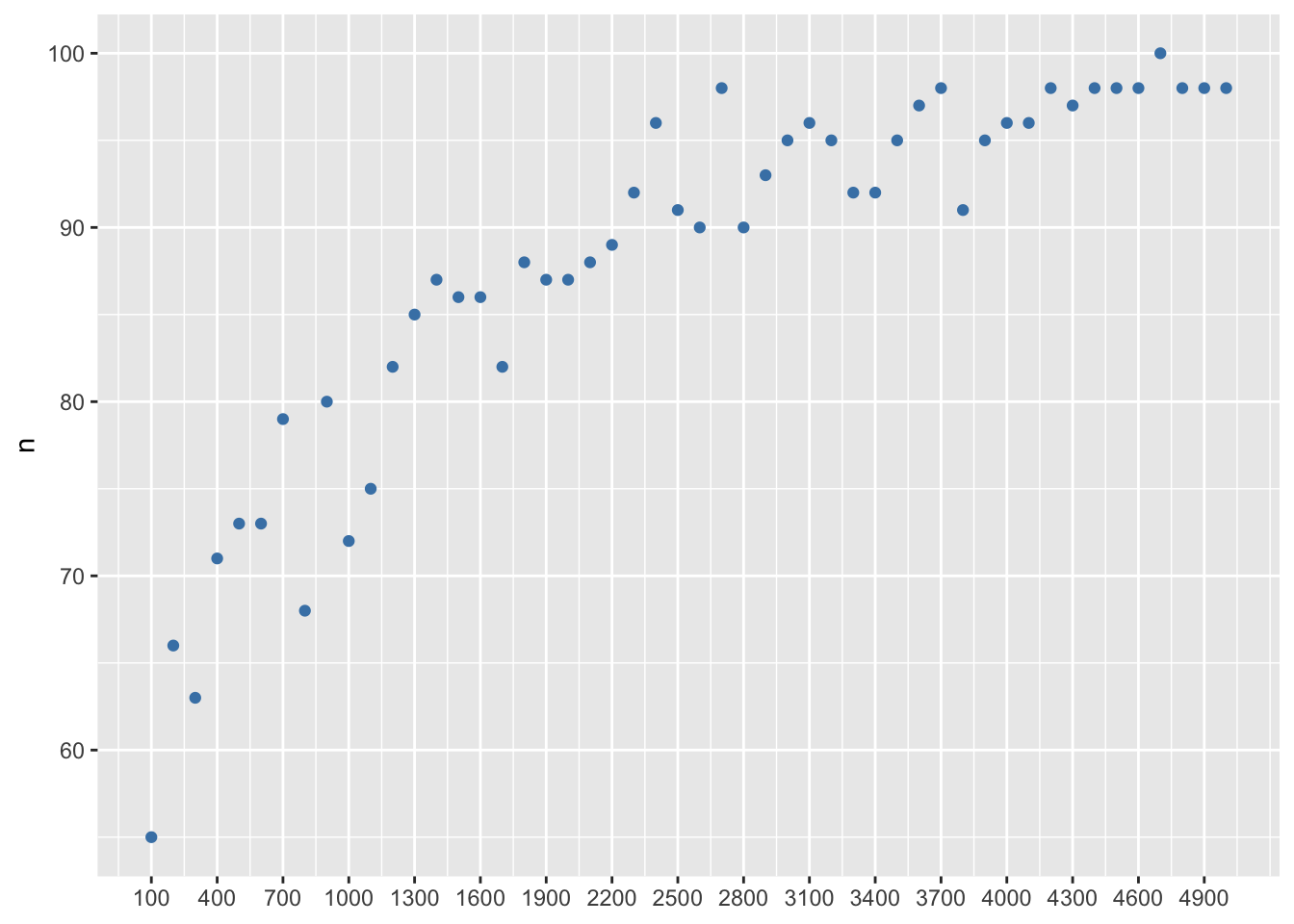
Функция samplesize.penalize() позволяет проверить эффективность метода на отрывках разной длины при работе с различными машинно-обучаемыми классификаторами, в том числе Delta.
Функция извлекает из текста случайные выборки все большей и большей длины и сравнивает их с обучающей выборкой для классификации с применением разного числа mfw; по умолчанию для каждой заданной длины отрывка проводится 100 итераций. На выходе функция возвращает матрицы с указанием количества успешных классификаций для каждой длины отрывка и заданного количества mfw, а также матрицы смешения, позволяющие судить о том, между какими авторами чаще возникала путаница.
Функция вернет список с показателями точность и матрицами смешения и некоторыми другими показателями. Подробнее о матрицах смешения мы будем говорить в разделе про машинное обучение, а пока просто посмотрим на то, как это выглядит.
Больше о подборе оптимального размера выборки см. статью в журнале Schole.
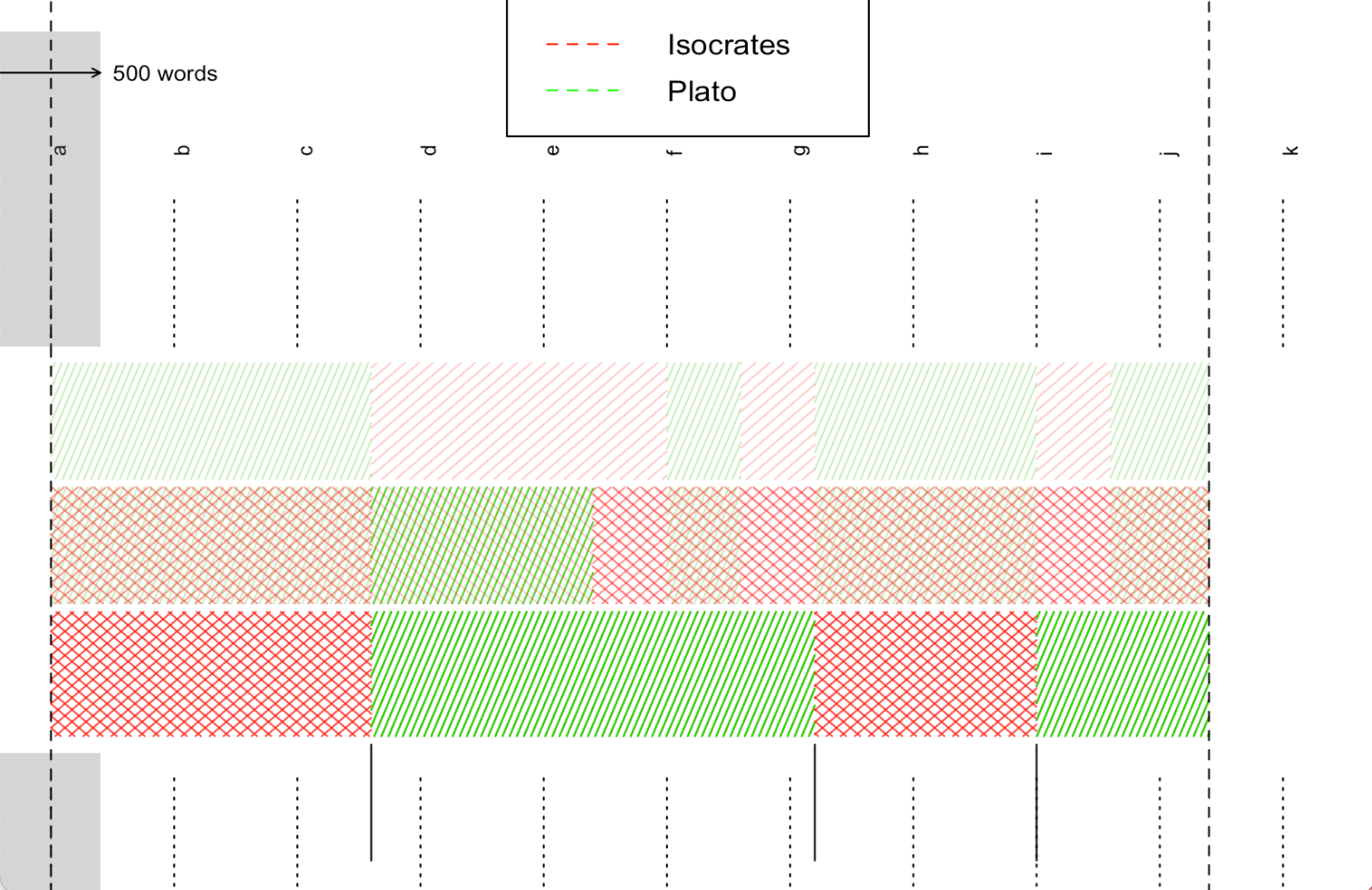
16.6rolling.delta()
Еще одна “фирменная” функция stylo называется rolling.delta(). Она подходит для тех случаев, когда текст написан в соавторстве (или мы предполагаем, что это так). Delta “прокатится” по всему тексту и для каждого его отрывка оценит вероятность того, что он создан тем или иным автором. Разумеется, это имеет смысл лишь в том случае, если у нас, во-первых, достаточно длинный спорный текст, а, во-вторых, есть понятные кандидаты. Статья от создателей с красивой картинкой (и еще одна).
Для демонстрации работы функции мы составили “монстра” из “Бусириса” Исократа и “Софиста” Платона: первая тысяча слов из Исократа, потом две тысячи из Платона, потом еще тысяча из Исократа и тысяча из Платона. Монстр лежит в папке test_set. Обучающие данные находятся в папке reference_set.
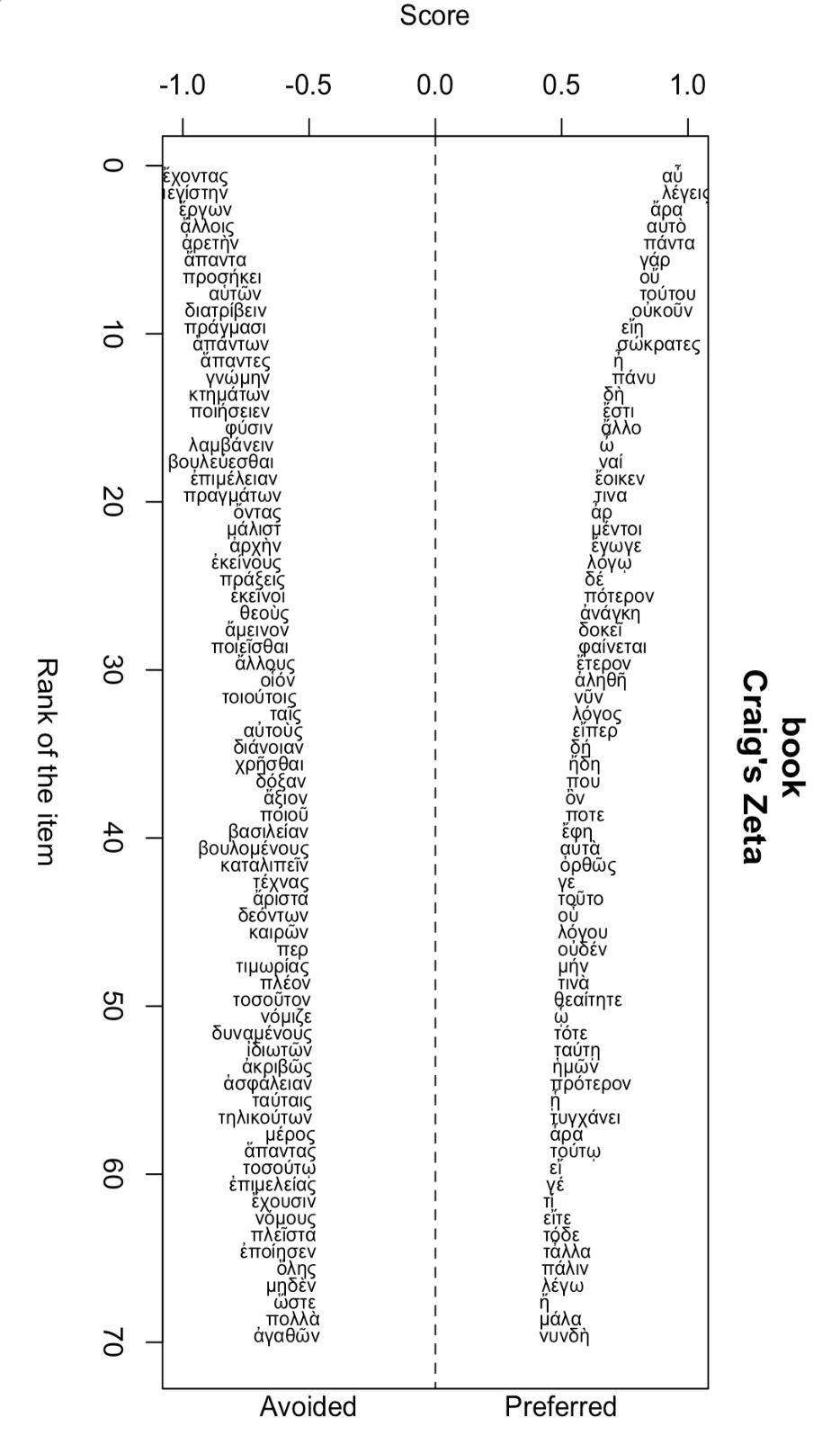
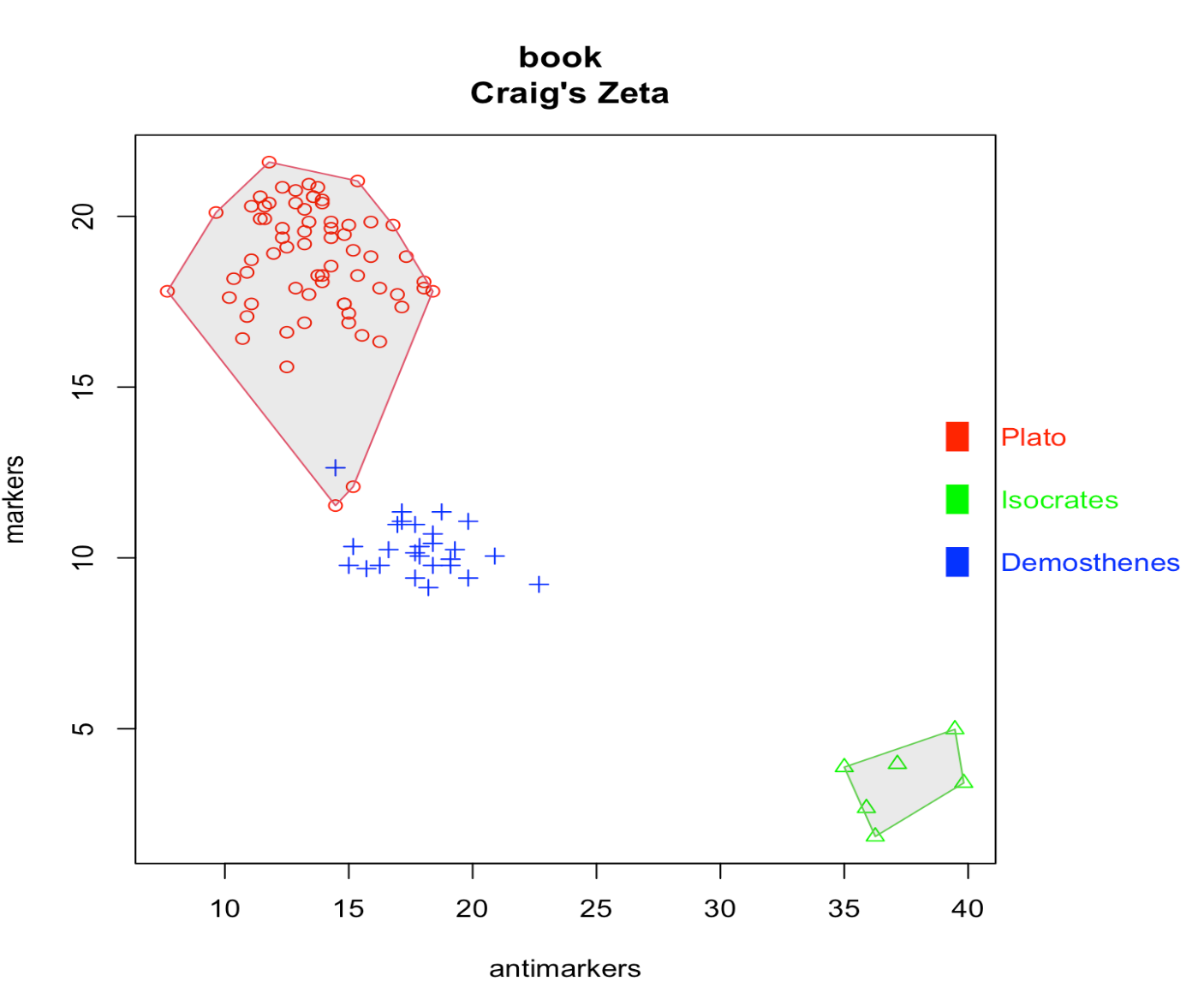
Функция oppose() реализует контрастивный анализ, помогая понять, каких слов авторы избегают, а какие – предпочитают. Функция возвращает два файла: words-preferred.txt и words-avoided.txt. Она тоже поддерживает графический интерфейс, но с древнегреческим бывают трудности токенизации, поэтому прописываем правило при помощи регулярных выражений.
Для сравнения возьмем Платона и Исократа (они тоже есть в архиве).
Контрастивный анализ, который проводит функция oppose(), тоже основан на методе, предложенном Д. Берроузом. Этот метод был описан и доработан рядом других исследователей, в том числе Хью Крейгом.
Его смысл подробно объясняет Savoy (2020), а более популярное объяснение (со ссылками на специальную литературу) можно найти на сайте https://zeta-project.eu. Общий смысл такой. Берутся два корпуса, которые необходимо сравнить. Это может быть корпус мужской и женской прозы, корпус Шекспира и других драматургов его времени, корпус американских и британских детективов… you name it. Один из корпусов (назовем его primary set) принимается за основу сравнения.
Все тексты делятся на фрагменты фиксированной длины, обычно от 900 до 6000 слов (Savoy 2020, 154). Дальше считается, в какой доле фрагментов из primary set слово встретилось и в какой доле фрагментов из secondary set оно не встретилось. Затем доли суммируются (тогда \(0 \leqslant z \leqslant 2\)). Допустим, мы сравниваем Шекспира и Марлоу. Если у Шекспира слово есть во всех фрагментах, а у Марлоу – ни в одном, то \(1 + 1 = 2\). Если наоборот, то \(0 + 0 = 0\). На практике крайние значения встречаются очень редко.
Другой вариант с примерно тем же смыслом. Считаем долю документов, в которых слово встречается у Шекспира и у Марлоу. Например, у Шекспира в 100%, а у Марло - ни в одном. Вторая доля вычитается из первой: \(1 - 0 = 1\). Если наоборот, то Zeta равна \(-1\). Таким образом, \(-1 \leqslant z \leqslant 1\).
Достоинство этого метода в том, что результат легко интерпретировать: мы сразу видим слова-дискриминаторы. Но надо помнить, что Zeta работает не с самыми частотными словами (точнее, не только с ними), а значит подвержена влиянию тематики и жанра.
16.9imposters()
Функция imposters() реализует метод верификации авторства, предложенный в статье М. Коппеля и Я. Винтера и апробированный на корпусе Цезаря.
Название метода отражает его суть: вместо того чтобы сравнивать текст неизвестного автора с текстами предполагаемых авторов, метод использует “импостеров” — случайно выбранные тексты, не принадлежащие ни одному из кандидатов, — для создания фона, на котором оценивается вероятность принадлежности текста конкретному автору.
Основные идеи метода imposters:
Создание обучающей выборки. Для проверки гипотезы о принадлежности текста определенному автору берется его текст, тексты кандидатов и большое количество “самозванцев” (то есть случайные тексты, которые заведомо не принадлежат ни одному из кандидатов).
Бустреп-подход. Метод много раз случайным образом выбирает подмножества признаков и случайные наборы “импостеров”, а затем выполняет этап классификации.
Проверка гипотезы. Если текст подозреваемого автора чаще всего классифицируется как принадлежащий этому автору, можно с высокой вероятностью утверждать, что это действительно так. Если же нет, значит, автором с большей долей вероятности является кто-то другой.
Почему такой метод эффективен? Классические методы (например, Delta-классификатор Бэрроуза) могут быть чувствительны к дисбалансу классов или менее устойчивы к вариативности текстов. Кроме того, использование “самозванцев” позволяет создать “естественный уровень шумова”, на фоне которого можно оценить значимость конкретной атрибуции.
Автор считается установленным, если атрибуция одному автору превышает некий установленный порог; значение этого порога устанавливается в зависимости от того, какова цена ошибки, то есть что для нас важнее – точность, precision (доля объектов, названными классификатором положительными и при этом действительно являющимися положительными) или полнота, recall (доля объектов положительного класса из всех объектов положительного класса). В качестве подмоги можно использовать функцию imposters.optimize().
Об этой функции см. подробнее виньетку и документацию. На входе она требует уже подготовленные таблицы с частотностями. Обратите внимание: если не задать значение аргументу candidate.set, функция проверит на авторство все доступные в reference.set классы.
data("galbraith")# забираем 8-й ряд из датасета:my_text_to_be_tested = galbraith[8,]# исключаем 8-й ряд из датасетаmy_frequency_table = galbraith[-c(8),]# поехали:imposters(reference.set = my_frequency_table, test = my_text_to_be_tested,iterations =100,features =0.5)
coben lewis rowling tolkien
0.28 0.00 1.00 0.00
Функция возвращает вектор вероятностей, где значения, близкие к 1, соответствуют наиболее правдоподобным кандидатам на авторство.
library(stringr)# кандидатыidx =str_detect(rownames(my_frequency_table), "rowling")my_candidates <- my_frequency_table[idx, ]my_imposters <- my_frequency_table[-idx, ]# поехали:imposters(reference.set = my_imposters, test = my_text_to_be_tested,# вот тут задаем кандидатовcandidate.set = my_candidates,iterations =100,features =0.5,# доля импостеров для каждой итерацииimposters =1)
Testing a given candidate against imposters...
rowling 1
rowling
1
16.10 Полезные материалы
О стилометрии есть множество отличных материалов на “Системном блоке”: