library(tidyverse)
library(tidymodels)
library(textrecipes)24 Регрессионные модели: SVR
24.1 Регрессионные алгоритмы
В машинном обучении проблемы, связанные с количественным откликом, называют проблемами регрессии, а проблемы, связанные с качественным откликом, проблемами классификации. В прошлом уроке мы познакомились с простой и множественной регрессией.
Но регрессионных алгоритмов великое множество. Вот лишь некоторые из них.
полиномиальная регрессия: расширение линейной регрессии, позволяющее учитывать нелинейные зависимости.
логистическая регрессия: используется для прогнозирования категориальных (бинарных) откликов.
регрессия на опорных векторах (SVM): ищет гиперплоскость, позволяющую минимизировать ошибку в многомерном пространстве.
деревья регрессии: строят иерархическую древовидную модель, последовательно разбивая данные на подгруппы.
случайный лес: комбинирует предсказания множества деревьев для повышения точности и устойчивости.
Кроме того, существуют методы регуляризации линейных моделей, позволяющие существенно улучшить их качество на данных большой размерности (т.е. с большим количеством предкторов). К таким алгоритмам относятся гребневая регрессия и метод лассо. О них мы поговорим в одном из следующих уроков.
О математической стороне дела см. Г. Джеймс, Д. Уиттон, Т. Хасти, Р. Тибришани (2017). В этом уроке мы начнем работать с различными регрессионными алгоритмами, используя библиотеку {tidymodels}.
24.2 Библиотека tidymodels
Библиотека tidymodels позволяет обучать модели и оценивать их эффективность с использованием принципов опрятных данных. Она представляет собой набор пакетов R, которые разработаны для работы с машинным обучением и совместима с экосистемой {tidyverse}.
Вот некоторые из ключевых пакетов, входящих в состав {tidymodels}:
{parsnip}- универсальный интерфейс для различных моделей машинного обучения, который упрощает переключение между разными типами моделей;{recipes}- фреймворк для создания и управления “рецептами” предварительной обработки данных перед тренировкой модели;{rsample}- инструменты для разделения данных на обучающую и тестовую выборки, а также для кросс-валидации;{tune}- функции для оптимизации гиперпараметров моделей машинного обучения;{yardstick}- инструменты для оценки производительности моделей;{workflow}позволяет объединить различные компоненты модели в единый объект: препроцессинг данных, модель машинного обучения, настройку гиперпараметров.
Мы также будем использовать пакет {textrecipes}, который представляет собой аналог {recipes} для текстовых данных.
24.3 Данные
Датасет для этого урока хранит данные о названиях, рейтингах, жанре, цене и числе отзывов на некоторые книги с Amazon. Мы попробуем построить регресионную модель, которая будет предсказывать цену книги. Скачайте данные по ссылке и прочитайте в окружение.
books <- readxl::read_xlsx("../files/AmazonBooks.xlsx")
booksДанные не очень опрятны, и прежде всего их надо тайдифицировать.
colnames(books) <- tolower(colnames(books))
books <- books |>
rename(rating = `user rating`)На графике ниже видно, что сильной корреляции между количественными переменными не прослеживается, так что задача перед нами стоит незаурядная. Посмотрим, что можно сделать в такой ситуации.
books |>
select_if(is.numeric) |>
cor() |>
corrplot::corrplot(method = "ellipse")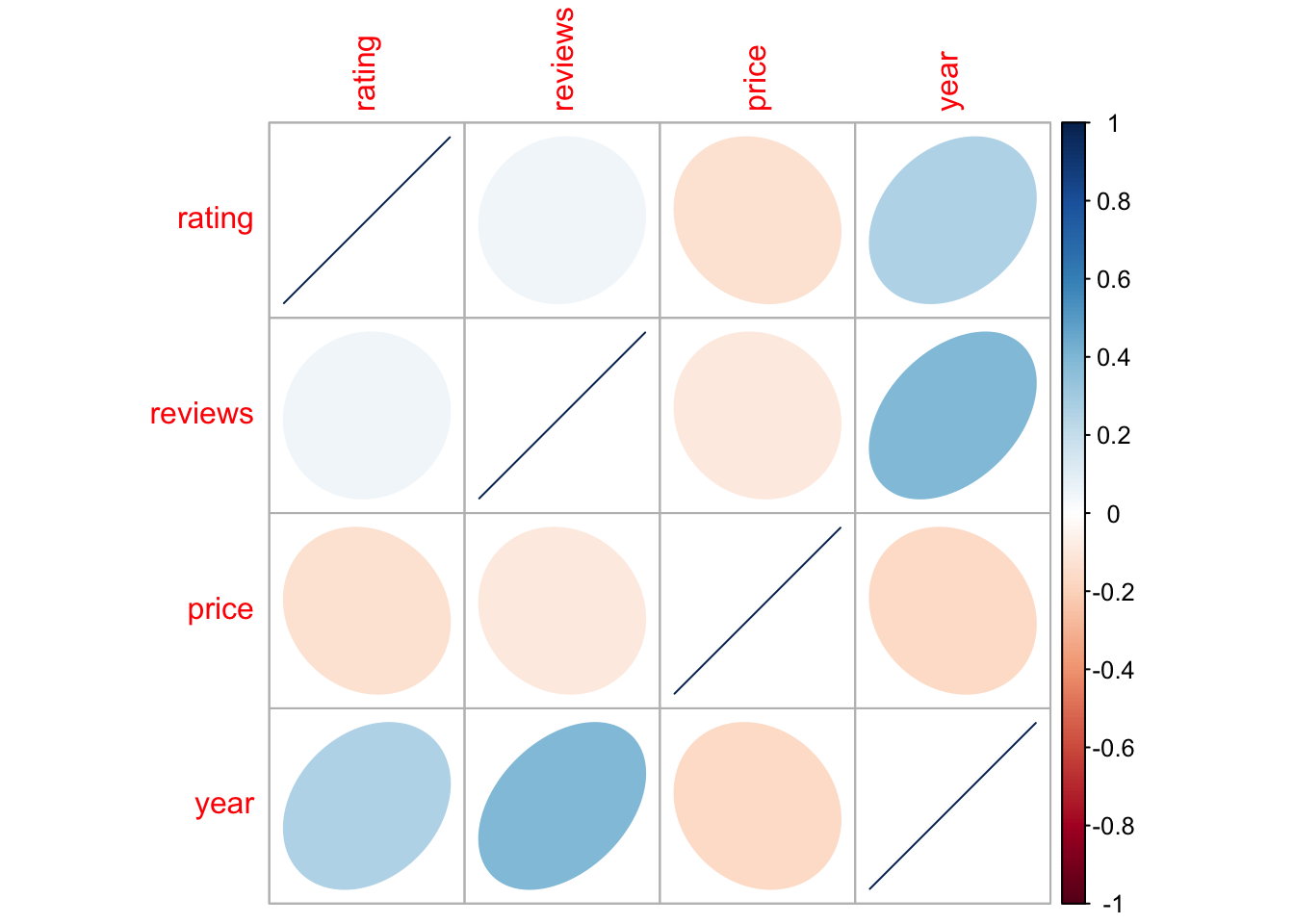
Мы видим, что количественные предикторы объясняют лишь ничтожную долю дисперсии (чуть более информативен жанр).
summary(lm(price ~ reviews + year + rating + genre, data = books))
Call:
lm(formula = price ~ reviews + year + rating + genre, data = books)
Residuals:
Min 1Q Median 3Q Max
-16.472 -5.050 -1.841 2.307 89.686
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 8.987e+02 2.734e+02 3.287 0.00107 **
reviews 7.779e-07 3.181e-05 0.024 0.98050
year -4.324e-01 1.370e-01 -3.156 0.00168 **
rating -3.655e+00 1.933e+00 -1.891 0.05909 .
genreNon Fiction 3.920e+00 8.669e-01 4.522 7.41e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 10.16 on 595 degrees of freedom
Multiple R-squared: 0.06903, Adjusted R-squared: 0.06277
F-statistic: 11.03 on 4 and 595 DF, p-value: 1.235e-08Посмотрим, можно ли как-то улучшить этот результат. Но сначала оценим визуально связь между ценой, с одной стороны, и годом и жанром, с другой.
g1 <- books |>
ggplot(aes(year, price, color = genre, group = genre)) +
geom_jitter(show.legend = FALSE, alpha = 0.7) +
geom_smooth(method = "lm", se = FALSE) +
theme_minimal()
g2 <- books |>
ggplot(aes(genre, price, color = genre)) +
geom_boxplot() +
theme_minimal()
gridExtra::grid.arrange(g1, g2, nrow = 1)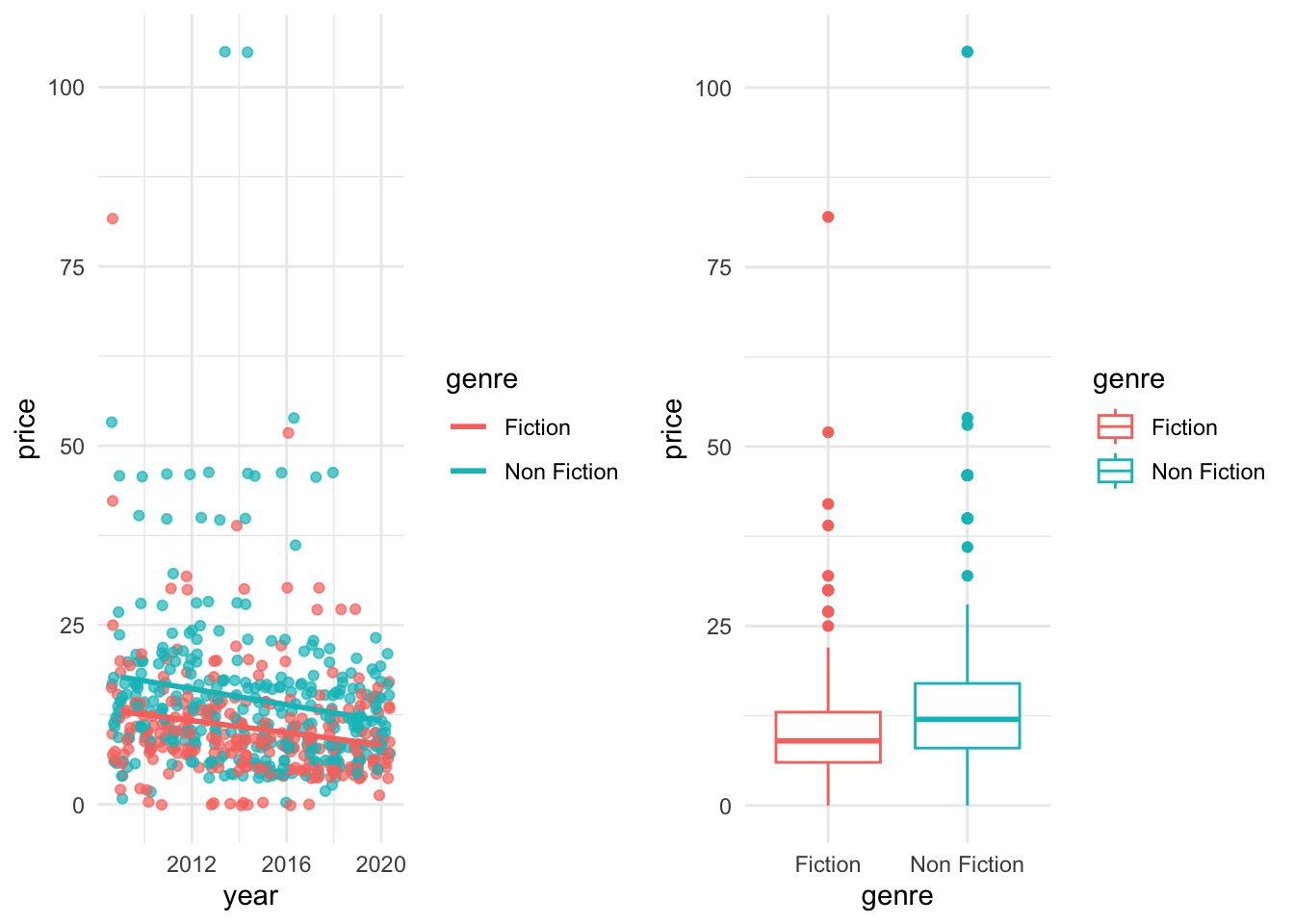
24.4 Обучающая и контрольная выборка
Вы уже знаете, при обучении модели мы стремимся к минимизации среднеквадратичной ошибки (MSE), однако в большинстве случаев нас интересует не то, как метод работает на обучающих данных, а то, как он покажет себя на контрольных данных. Чтобы избежать переобучения, очень важно в самом начале разделить доступные наблюдения на две группы.
set.seed(080426)
books_split <- books |>
initial_split()
books_train <- training(books_split)
books_test <- testing(books_split)24.5 Определение модели
Определение модели включает следующие шаги:
указывается тип модели на основе ее математической структуры (например, линейная регрессия, случайный лес, KNN и т. д.);
указывается механизм для подгонки модели – чаще всего это программный пакет, который должен быть использован, например
{glmnet}. Это самостоятельные модели, и{parsnip}обеспечивает согласованные интерфейсы, используя их в качестве движков для моделирования.при необходимости объявляется режим модели. Режим отражает тип прогнозируемого результата. Для числовых результатов режимом является регрессия, для качественных - классификация. Если алгоритм модели может работать только с одним типом результатов прогнозирования, например, линейной регрессией, режим уже задан.
На заметку
В R существует много разных пакетов и отдельных функций для построения моделей. У каждого пакета свой синтаксис и свои названия параметров. Например, в {ranger}, чтобы задать количество деревьев, пишут num.trees, а в {xgboost} — nrounds. Это неудобно: каждый раз нужно вспоминать правила конкретного пакета. {parsnip} создает единый, унифицированный интерфейс для всех моделей. Это позволяет переключаться между разными пакетами, не переучивая синтаксис.
24.6 Регрессия на опорных векторах
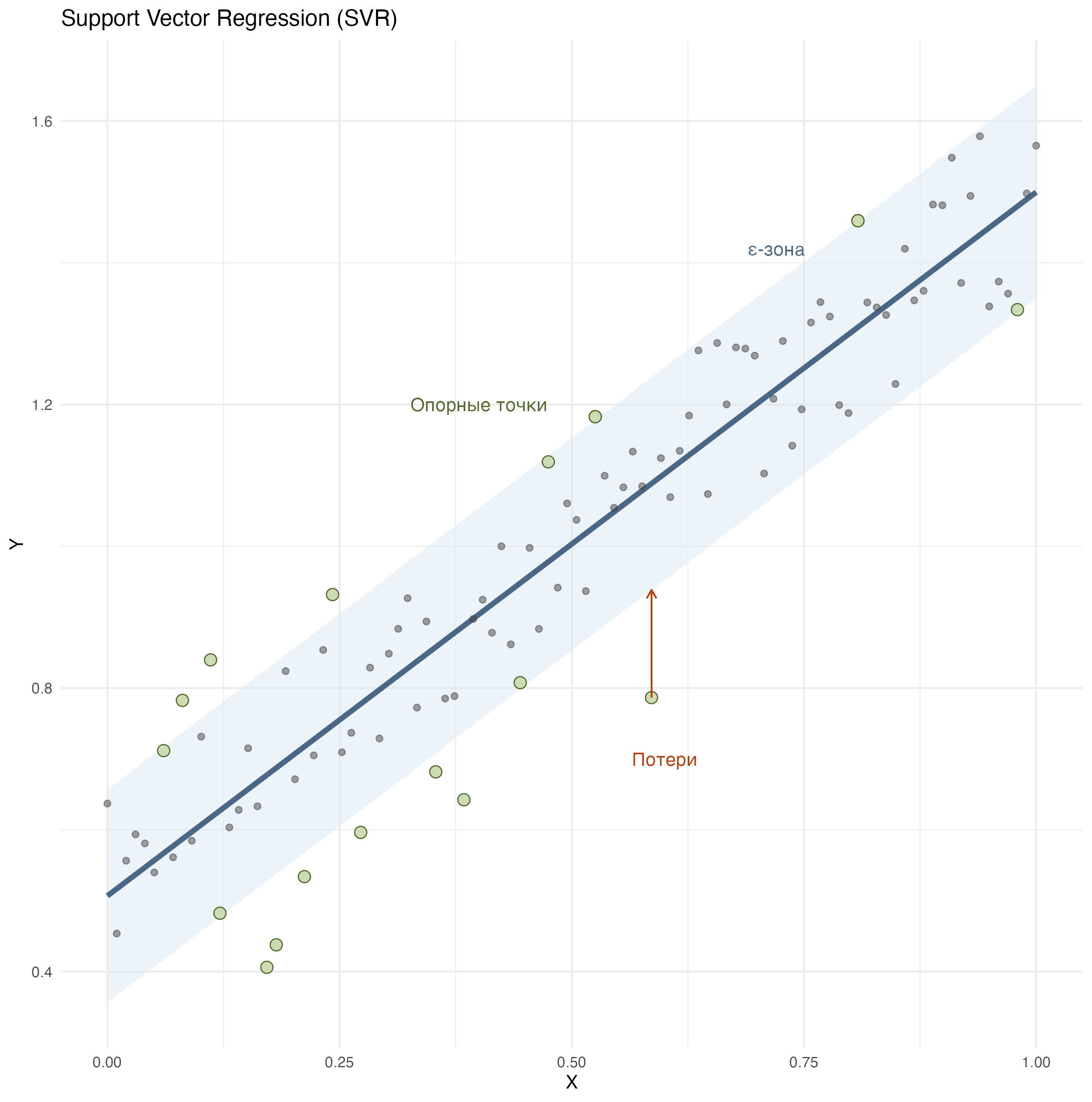
Support Vector Regression — это метод машинного обучения, основанный на идеях метода опорных векторов (SVM), но адаптированный к задаче регрессии, а не классификации (о чем см. следующий урок).
Вместо поиска разделяющей гиперплоскости между классами (как в классификации), SVR старается найти функцию, которая:
- игнорирует небольшие отклонения внутри некоторого допустимого порога ε (эпсилон),
- акцентирует внимание на точках, которые лежат вне этой “трубы”, — это и есть опорные векторы.
В этом заключается отличие от обычной регрессии, которая старается проложить прямую, наиболее близкую ко всем точкам и “наказывает” любое отклонение.
SVR тоже строит линию (или кривую в случае нелинейного ядра), но с другим подходом. Она “довольна”, если предсказание находится в пределах допустимой ошибки ε (эпсилон) от настоящего значения.
SVR концентрируется только на тех точках, что выходят за эту “зону безразличия” или лежат на ее границе — они называются опорными векторами. Именно они определяют форму и положение модели. Остальные точки (в пределах ε) никак не влияют на модель.
24.7 Линейная SVR
Функция translate() позволяет понять, как parsnip переводит пользовательский код на язык пакета.
svm_spec <- svm_linear() |>
set_engine("LiblineaR") |>
set_mode("regression")
# svm_spec |>
# translate()Пока это просто спецификация модели без данных и без формулы. Добавим ее к воркфлоу.
svm_wflow <- workflow() |>
add_model(svm_spec)
svm_wflow══ Workflow ════════════════════════════════════════════════════════════════════
Preprocessor: None
Model: svm_linear()
── Model ───────────────────────────────────────────────────────────────────────
Linear Support Vector Machine Model Specification (regression)
Computational engine: LiblineaR 24.8 Дизайн переменных
Теперь нам нужен препроцессор. За него отвечает пакет {recipes}. Если вы не уверены, какие шаги необходимы на этом этапе, можно заглянуть в шпаргалку. В случае с линейной регрессией это может быть логарифмическая трансформация, нормализация, отсев переменных с нулевой дисперсией (zero variance), добавление (impute) недостающих значений или удаление переменных, которые коррелируют с другими переменными.
Вот так выглядит наш первый рецепт. Обратите внимание, что формула записывается так же, как мы это делали ранее внутри функции lm(). Порядок шагов важен (поэтому применяем нормализацию в самом конце)!
books_rec <- recipe(price ~ year + genre + name + reviews + rating,
data = books_train) |>
step_dummy(genre) |>
step_tokenize(name) |>
step_tokenfilter(name, max_tokens = 1000) |>
step_tfidf(name) |>
step_normalize(all_predictors())При желании можно посмотреть на результат предобработки.
Для этого сначала передаем функции prep(), которая отвечает за подготовку (обучение рецепта). На этом этапе компьютер внимательно изучает ваши тренировочные данные, чтобы вычислить параметры для каждого шага, например среднее и стандартное отклонение для step_normalize(), словарь для step_tokenfilter() и т.д. Рецепт “запоминает” эти значения, чтобы потом применить их точно так же к новым данным. Сами данные на этом этапе еще не меняются.
Команда bake() примененяет рецепт к данным, т.е. берет таблицу с данными и прогоняет её через все шаги, используя параметры из prep(). В результате вы получаете готовую широкую матрицу с числами, которую уже можно “скармливать” алгоритму SVR.
prep(books_rec, books_train) |>
bake(new_data = NULL) |>
head(5) |>
gt::gt()| year | reviews | rating | price | genre_Non.Fiction | tfidf_name_1 | tfidf_name_1,111 | tfidf_name_10 | tfidf_name_100 | tfidf_name_11 | tfidf_name_12 | tfidf_name_150 | tfidf_name_17 | tfidf_name_1936 | tfidf_name_2 | tfidf_name_2.0 | tfidf_name_20 | tfidf_name_2016 | tfidf_name_22 | tfidf_name_3 | tfidf_name_30 | tfidf_name_300 | tfidf_name_4 | tfidf_name_451 | tfidf_name_49 | tfidf_name_5 | tfidf_name_500 | tfidf_name_5000 | tfidf_name_52 | tfidf_name_5th | tfidf_name_6 | tfidf_name_60 | tfidf_name_6th | tfidf_name_7 | tfidf_name_700 | tfidf_name_8 | tfidf_name_a | tfidf_name_about | tfidf_name_absurd | tfidf_name_account | tfidf_name_achieving | tfidf_name_acid | tfidf_name_activity | tfidf_name_adult | tfidf_name_adults | tfidf_name_advanced | tfidf_name_adventures | tfidf_name_adversity | tfidf_name_afterlife | tfidf_name_aftermath | tfidf_name_against | tfidf_name_ages | tfidf_name_agreements | tfidf_name_ahead | tfidf_name_alaska | tfidf_name_alchemist | tfidf_name_alex | tfidf_name_all | tfidf_name_allâ | tfidf_name_allegiant | tfidf_name_almost | tfidf_name_alphabet | tfidf_name_am | tfidf_name_amateur | tfidf_name_amazing | tfidf_name_america | tfidf_name_america's | tfidf_name_american | tfidf_name_americans | tfidf_name_an | tfidf_name_ancient | tfidf_name_and | tfidf_name_animal | tfidf_name_animals | tfidf_name_answers | tfidf_name_antidote | tfidf_name_antiracist | tfidf_name_apologizing | tfidf_name_approach | tfidf_name_are | tfidf_name_arguing | tfidf_name_art | tfidf_name_as | tfidf_name_asians | tfidf_name_assassination | tfidf_name_association | tfidf_name_at | tfidf_name_athena | tfidf_name_atomic | tfidf_name_attitude | tfidf_name_audacious | tfidf_name_autobiography | tfidf_name_awesome | tfidf_name_azkaban | tfidf_name_b | tfidf_name_back | tfidf_name_bad | tfidf_name_badass | tfidf_name_ball | tfidf_name_ballad | tfidf_name_barefoot | tfidf_name_be | tfidf_name_bear | tfidf_name_beasts | tfidf_name_beautiful | tfidf_name_beck's | tfidf_name_become | tfidf_name_becoming | tfidf_name_bed | tfidf_name_bee | tfidf_name_beginner's | tfidf_name_beginners | tfidf_name_believing | tfidf_name_belly | tfidf_name_berlin | tfidf_name_between | tfidf_name_big | tfidf_name_bill | tfidf_name_billionaires | tfidf_name_bin | tfidf_name_birth | tfidf_name_blitz | tfidf_name_blood | tfidf_name_blue | tfidf_name_boat | tfidf_name_body | tfidf_name_bombers | tfidf_name_book | tfidf_name_books | tfidf_name_boom | tfidf_name_born | tfidf_name_bossypants | tfidf_name_boxed | tfidf_name_boy | tfidf_name_boys | tfidf_name_brain | tfidf_name_brain's | tfidf_name_brave | tfidf_name_brawl | tfidf_name_break | tfidf_name_breaking | tfidf_name_bree | tfidf_name_brigance | tfidf_name_brink | tfidf_name_broke | tfidf_name_brothers | tfidf_name_brown | tfidf_name_brush | tfidf_name_build | tfidf_name_building | tfidf_name_business | tfidf_name_buy | tfidf_name_by | tfidf_name_cabin | tfidf_name_cakes | tfidf_name_called | tfidf_name_calligraphy | tfidf_name_calling | tfidf_name_calm | tfidf_name_camelot | tfidf_name_can | tfidf_name_can't | tfidf_name_cannot | tfidf_name_capital | tfidf_name_captain | tfidf_name_carbs | tfidf_name_case | tfidf_name_caste | tfidf_name_catching | tfidf_name_caterpillar | tfidf_name_cats | tfidf_name_cauldron | tfidf_name_century | tfidf_name_chamber | tfidf_name_champion | tfidf_name_change | tfidf_name_changed | tfidf_name_changing | tfidf_name_chaos | tfidf_name_chicka | tfidf_name_choose | tfidf_name_christian | tfidf_name_chronicles | tfidf_name_churchill | tfidf_name_ck | tfidf_name_clash | tfidf_name_class | tfidf_name_classic | tfidf_name_clintons | tfidf_name_club | tfidf_name_collected | tfidf_name_collection | tfidf_name_college | tfidf_name_color | tfidf_name_coloring | tfidf_name_colors | tfidf_name_columbus's | tfidf_name_comfort | tfidf_name_commander | tfidf_name_comments | tfidf_name_common | tfidf_name_companies | tfidf_name_complete | tfidf_name_confession | tfidf_name_confident | tfidf_name_confronts | tfidf_name_constitution | tfidf_name_construction | tfidf_name_contessa | tfidf_name_control | tfidf_name_cookbook | tfidf_name_cookbooks | tfidf_name_cooker | tfidf_name_cooking | tfidf_name_cooks | tfidf_name_cooling | tfidf_name_counterintuitive | tfidf_name_crawdads | tfidf_name_crayons | tfidf_name_crazy | tfidf_name_create | tfidf_name_created | tfidf_name_creating | tfidf_name_creative | tfidf_name_creator | tfidf_name_crest | tfidf_name_crisis | tfidf_name_cross | tfidf_name_crows | tfidf_name_cultivate | tfidf_name_culture | tfidf_name_cups | tfidf_name_cutting | tfidf_name_cycle | tfidf_name_da | tfidf_name_dad | tfidf_name_dance | tfidf_name_dangerous | tfidf_name_danny | tfidf_name_dare | tfidf_name_darker | tfidf_name_dawn | tfidf_name_day | tfidf_name_days | tfidf_name_dead | tfidf_name_dear | tfidf_name_death | tfidf_name_decades | tfidf_name_decision | tfidf_name_deckled | tfidf_name_decluttering | tfidf_name_defiance | tfidf_name_definitive | tfidf_name_defy | tfidf_name_delicious | tfidf_name_delivering | tfidf_name_deluxe | tfidf_name_designed | tfidf_name_designs | tfidf_name_devotional | tfidf_name_diagnostic | tfidf_name_diary | tfidf_name_die | tfidf_name_diet | tfidf_name_difference | tfidf_name_difficult | tfidf_name_dirt | tfidf_name_discontents | tfidf_name_discovery | tfidf_name_disease | tfidf_name_disorders | tfidf_name_divergent | tfidf_name_divine | tfidf_name_do | tfidf_name_doctor's | tfidf_name_documents | tfidf_name_dog | tfidf_name_dome | tfidf_name_don't | tfidf_name_donkey | tfidf_name_doomsday | tfidf_name_double | tfidf_name_doubting | tfidf_name_down | tfidf_name_dragon | tfidf_name_dragons | tfidf_name_dream | tfidf_name_drive | tfidf_name_dsm | tfidf_name_duck | tfidf_name_dungeons | tfidf_name_during | tfidf_name_dysfunctions | tfidf_name_earth | tfidf_name_easy | tfidf_name_eat | tfidf_name_eater's | tfidf_name_echoed | tfidf_name_eclipse | tfidf_name_edge | tfidf_name_edition | tfidf_name_educated | tfidf_name_effective | tfidf_name_electric | tfidf_name_elegance | tfidf_name_elegy | tfidf_name_elements | tfidf_name_elephants | tfidf_name_embracing | tfidf_name_end | tfidf_name_english | tfidf_name_enjoying | tfidf_name_enough | tfidf_name_epic | tfidf_name_essential | tfidf_name_eternity | tfidf_name_everyday | tfidf_name_everything | tfidf_name_everywhere | tfidf_name_exceptional | tfidf_name_f | tfidf_name_fable | tfidf_name_face | tfidf_name_facing | tfidf_name_facts | tfidf_name_fahrenheit | tfidf_name_faith | tfidf_name_families | tfidf_name_family | tfidf_name_fast | tfidf_name_fat | tfidf_name_fault | tfidf_name_fbi | tfidf_name_fear | tfidf_name_feast | tfidf_name_featuring | tfidf_name_feel | tfidf_name_feeling | tfidf_name_fetch | tfidf_name_fever | tfidf_name_fey | tfidf_name_fifty | tfidf_name_find | tfidf_name_finding | tfidf_name_fire | tfidf_name_fires | tfidf_name_first | tfidf_name_firsthand | tfidf_name_fish | tfidf_name_five | tfidf_name_flap | tfidf_name_fleas | tfidf_name_flower | tfidf_name_flowers | tfidf_name_food | tfidf_name_foolproof | tfidf_name_for | tfidf_name_forâ | tfidf_name_forever | tfidf_name_found | tfidf_name_four | tfidf_name_fox | tfidf_name_fragility | tfidf_name_freakonomics | tfidf_name_free | tfidf_name_freed | tfidf_name_freedom | tfidf_name_french | tfidf_name_friends | tfidf_name_from | tfidf_name_frontier | tfidf_name_frozen | tfidf_name_full | tfidf_name_fully | tfidf_name_fun | tfidf_name_future | tfidf_name_game | tfidf_name_games | tfidf_name_garden | tfidf_name_gathering | tfidf_name_gatsby | tfidf_name_general | tfidf_name_gentleman | tfidf_name_geographic | tfidf_name_george | tfidf_name_get | tfidf_name_getaway | tfidf_name_gifts | tfidf_name_giraffes | tfidf_name_girl | tfidf_name_girls | tfidf_name_give | tfidf_name_giving | tfidf_name_glenn | tfidf_name_glitter | tfidf_name_global | tfidf_name_glory | tfidf_name_go | tfidf_name_goals | tfidf_name_goblet | tfidf_name_god | tfidf_name_going | tfidf_name_gold | tfidf_name_gone | tfidf_name_good | tfidf_name_goodnight | tfidf_name_government | tfidf_name_grades | tfidf_name_grain | tfidf_name_gratitude | tfidf_name_great | tfidf_name_greatness | tfidf_name_greenlights | tfidf_name_grey | tfidf_name_grime | tfidf_name_guardians | tfidf_name_guernsey | tfidf_name_guide | tfidf_name_guided | tfidf_name_gut | tfidf_name_guts | tfidf_name_habit | tfidf_name_habits | tfidf_name_half | tfidf_name_hamilton | tfidf_name_hand | tfidf_name_handbook | tfidf_name_handmaid's | tfidf_name_hands | tfidf_name_happened | tfidf_name_happiness | tfidf_name_happy | tfidf_name_harbinger | tfidf_name_hard | tfidf_name_hardcover | tfidf_name_harry | tfidf_name_hate | tfidf_name_haul | tfidf_name_have | tfidf_name_haven | tfidf_name_hayek | tfidf_name_head | tfidf_name_heal | tfidf_name_healing | tfidf_name_health | tfidf_name_healthy | tfidf_name_healthyâ | tfidf_name_heat | tfidf_name_heaven | tfidf_name_hedgehog | tfidf_name_help | tfidf_name_henna | tfidf_name_henrietta | tfidf_name_her | tfidf_name_heroes | tfidf_name_higher | tfidf_name_highly | tfidf_name_hillbilly | tfidf_name_his | tfidf_name_historia | tfidf_name_history | tfidf_name_hitler's | tfidf_name_holds | tfidf_name_homebody | tfidf_name_honey | tfidf_name_hornet's | tfidf_name_horse | tfidf_name_hour | tfidf_name_house | tfidf_name_how | tfidf_name_human | tfidf_name_humanity | tfidf_name_humans | tfidf_name_hunger | tfidf_name_hungry | tfidf_name_hurricane | tfidf_name_hurt | tfidf_name_hypothetical | tfidf_name_hyrule | tfidf_name_i | tfidf_name_ice | tfidf_name_icons | tfidf_name_ideas | tfidf_name_idiots | tfidf_name_if | tfidf_name_ii | tfidf_name_ii's | tfidf_name_illustrated | tfidf_name_imagination | tfidf_name_immortal | tfidf_name_in | tfidf_name_inches | tfidf_name_includes | tfidf_name_incredible | tfidf_name_inferno | tfidf_name_influence | tfidf_name_inheritance | tfidf_name_inside | tfidf_name_inspired | tfidf_name_instant | tfidf_name_insurance | tfidf_name_insurgent | tfidf_name_intimate | tfidf_name_into | tfidf_name_introverts | tfidf_name_irreverent | tfidf_name_is | tfidf_name_it | tfidf_name_it's | tfidf_name_iv | tfidf_name_jackson | tfidf_name_jake | tfidf_name_japan | tfidf_name_japanese | tfidf_name_jesus | tfidf_name_jobs | tfidf_name_jokes | tfidf_name_journal | tfidf_name_journey | tfidf_name_joy | tfidf_name_k | tfidf_name_kane | tfidf_name_keeps | tfidf_name_kennedy | tfidf_name_keto | tfidf_name_ketogenic | tfidf_name_kicked | tfidf_name_kid | tfidf_name_kids | tfidf_name_kill | tfidf_name_killed | tfidf_name_killers | tfidf_name_killing | tfidf_name_kings | tfidf_name_kissed | tfidf_name_kitchen | tfidf_name_kitties | tfidf_name_knickerbocker | tfidf_name_knock | tfidf_name_know | tfidf_name_knowledge | tfidf_name_lacks | tfidf_name_laden | tfidf_name_land | tfidf_name_languages | tfidf_name_last | tfidf_name_lasts | tfidf_name_laugh | tfidf_name_lead | tfidf_name_leadership | tfidf_name_lean | tfidf_name_leap | tfidf_name_learn | tfidf_name_leave | tfidf_name_lectin | tfidf_name_lecture | tfidf_name_left | tfidf_name_legacy | tfidf_name_legend | tfidf_name_lego | tfidf_name_leonardo | tfidf_name_less | tfidf_name_lessons | tfidf_name_lettering | tfidf_name_lies | tfidf_name_life | tfidf_name_lifestyle | tfidf_name_lifetime | tfidf_name_lift | tfidf_name_light | tfidf_name_like | tfidf_name_lincoln | tfidf_name_literary | tfidf_name_litigators | tfidf_name_little | tfidf_name_live | tfidf_name_living | tfidf_name_lonely | tfidf_name_long | tfidf_name_looking | tfidf_name_lord | tfidf_name_lose | tfidf_name_losing | tfidf_name_loss | tfidf_name_lost | tfidf_name_loud | tfidf_name_love | tfidf_name_loved | tfidf_name_loyalty | tfidf_name_luck | tfidf_name_machine | tfidf_name_magic | tfidf_name_magical | tfidf_name_magnolia | tfidf_name_make | tfidf_name_man | tfidf_name_man's | tfidf_name_mandalas | tfidf_name_manual | tfidf_name_mark | tfidf_name_martian | tfidf_name_master | tfidf_name_mastering | tfidf_name_matter | tfidf_name_maze | tfidf_name_mccain | tfidf_name_me | tfidf_name_meals | tfidf_name_meant | tfidf_name_memoir | tfidf_name_mental | tfidf_name_midnight | tfidf_name_milk | tfidf_name_millennium | tfidf_name_mind | tfidf_name_minds | tfidf_name_miracles | tfidf_name_mission | tfidf_name_mockingbird | tfidf_name_mockingjay | tfidf_name_modern | tfidf_name_mole | tfidf_name_mon | tfidf_name_moon | tfidf_name_more | tfidf_name_moscow | tfidf_name_most | tfidf_name_mother | tfidf_name_motivates | tfidf_name_mountains | tfidf_name_much | tfidf_name_mueller | tfidf_name_murders | tfidf_name_my | tfidf_name_mystery | tfidf_name_national | tfidf_name_navy | tfidf_name_need | tfidf_name_neptune | tfidf_name_nest | tfidf_name_neurosurgeon's | tfidf_name_never | tfidf_name_new | tfidf_name_night | tfidf_name_nightingale | tfidf_name_nine | tfidf_name_no | tfidf_name_not | tfidf_name_novel | tfidf_name_novella | tfidf_name_now | tfidf_name_numbers | tfidf_name_nutrient | tfidf_name_o'reilly's | tfidf_name_obama | tfidf_name_odds | tfidf_name_of | tfidf_name_official | tfidf_name_oh | tfidf_name_old | tfidf_name_olympian | tfidf_name_olympians | tfidf_name_olympics | tfidf_name_olympus | tfidf_name_on | tfidf_name_one | tfidf_name_ones | tfidf_name_oprah's | tfidf_name_option | tfidf_name_or | tfidf_name_organizing | tfidf_name_origins | tfidf_name_orphan | tfidf_name_osage | tfidf_name_osama | tfidf_name_others | tfidf_name_our | tfidf_name_out | tfidf_name_outliers | tfidf_name_ove | tfidf_name_over | tfidf_name_overwhelmed | tfidf_name_p | tfidf_name_pacific | tfidf_name_paine | tfidf_name_paint | tfidf_name_paisley | tfidf_name_paisleyâ | tfidf_name_palin | tfidf_name_paperback | tfidf_name_paradox | tfidf_name_paris | tfidf_name_passion | tfidf_name_passions | tfidf_name_pastimes | tfidf_name_path | tfidf_name_patriot's | tfidf_name_patriotic | tfidf_name_patriots | tfidf_name_patterns | tfidf_name_patton | tfidf_name_peace | tfidf_name_peel | tfidf_name_people | tfidf_name_percy | tfidf_name_performers | tfidf_name_personal | tfidf_name_pet | tfidf_name_pictures | tfidf_name_pie | tfidf_name_pilgrims | tfidf_name_pioneer | tfidf_name_places | tfidf_name_plan | tfidf_name_planet | tfidf_name_plant | tfidf_name_played | tfidf_name_player | tfidf_name_player's | tfidf_name_point | tfidf_name_points | tfidf_name_pokã | tfidf_name_politics | tfidf_name_portrait | tfidf_name_pot | tfidf_name_potato | tfidf_name_potter | tfidf_name_potty | tfidf_name_pounds | tfidf_name_pout | tfidf_name_power | tfidf_name_powerful | tfidf_name_practical | tfidf_name_prayer | tfidf_name_pre | tfidf_name_preschool | tfidf_name_presence | tfidf_name_press | tfidf_name_pressure | tfidf_name_preventing | tfidf_name_prisoner | tfidf_name_profits | tfidf_name_program | tfidf_name_promised | tfidf_name_promote | tfidf_name_proof | tfidf_name_prostitutes | tfidf_name_proven | tfidf_name_psychological | tfidf_name_publication | tfidf_name_punishment | tfidf_name_purpose | tfidf_name_put | tfidf_name_pyramid | tfidf_name_quest | tfidf_name_questions | tfidf_name_quiet | tfidf_name_quintet | tfidf_name_quit | tfidf_name_race | tfidf_name_racing | tfidf_name_racism | tfidf_name_racketeer | tfidf_name_radical | tfidf_name_rain | tfidf_name_rapid | tfidf_name_readingâ | tfidf_name_ready | tfidf_name_recipes | tfidf_name_reckoning | tfidf_name_red | tfidf_name_redemption | tfidf_name_references | tfidf_name_relentless | tfidf_name_relief | tfidf_name_relieving | tfidf_name_report | tfidf_name_resilience | tfidf_name_restore | tfidf_name_results | tfidf_name_reusable | tfidf_name_revere | tfidf_name_revised | tfidf_name_revolution | tfidf_name_revolutionary | tfidf_name_rich | tfidf_name_riddles | tfidf_name_right | tfidf_name_ring | tfidf_name_rising | tfidf_name_road | tfidf_name_rogue | tfidf_name_rolls | tfidf_name_room | tfidf_name_routines | tfidf_name_row | tfidf_name_rules | tfidf_name_run | tfidf_name_runner | tfidf_name_rush | tfidf_name_sacred | tfidf_name_saga | tfidf_name_sagas | tfidf_name_salt | tfidf_name_sat | tfidf_name_save | tfidf_name_saved | tfidf_name_says | tfidf_name_school | tfidf_name_scientific | tfidf_name_score | tfidf_name_scripture | tfidf_name_seal | tfidf_name_second | tfidf_name_secret | tfidf_name_secrets | tfidf_name_see | tfidf_name_sense | tfidf_name_serfdom | tfidf_name_series | tfidf_name_serious | tfidf_name_serpent's | tfidf_name_sesame | tfidf_name_set | tfidf_name_seuss | tfidf_name_sex | tfidf_name_sh | tfidf_name_shack | tfidf_name_shades | tfidf_name_shadow | tfidf_name_shame | tfidf_name_shapes | tfidf_name_shocking | tfidf_name_short | tfidf_name_should | tfidf_name_shred | tfidf_name_silent | tfidf_name_silly | tfidf_name_simple | tfidf_name_sing | tfidf_name_site | tfidf_name_six | tfidf_name_sizes | tfidf_name_sleep | tfidf_name_slow | tfidf_name_small | tfidf_name_smart | tfidf_name_snakes | tfidf_name_so | tfidf_name_society | tfidf_name_solution | tfidf_name_some | tfidf_name_son | tfidf_name_song | tfidf_name_songbirds | tfidf_name_sookie | tfidf_name_soul | tfidf_name_spaces | tfidf_name_spiral | tfidf_name_spiritualâ | tfidf_name_splendid | tfidf_name_spy | tfidf_name_stackhouse | tfidf_name_stars | tfidf_name_start | tfidf_name_states | tfidf_name_statistical | tfidf_name_stats | tfidf_name_steve | tfidf_name_sticker | tfidf_name_stickers | tfidf_name_stolen | tfidf_name_stone | tfidf_name_stop | tfidf_name_stopping | tfidf_name_stories | tfidf_name_storm | tfidf_name_story | tfidf_name_strange | tfidf_name_straw | tfidf_name_street | tfidf_name_strengthsfinder | tfidf_name_stress | tfidf_name_students | tfidf_name_study | tfidf_name_subtle | tfidf_name_success | tfidf_name_sugar | tfidf_name_suicide | tfidf_name_sun | tfidf_name_super | tfidf_name_superhuman | tfidf_name_supermarket | tfidf_name_surprising | tfidf_name_survival | tfidf_name_sustained | tfidf_name_swaps | tfidf_name_switch | tfidf_name_swords | tfidf_name_sycamore | tfidf_name_symbol | tfidf_name_system | tfidf_name_t | tfidf_name_table | tfidf_name_tactics | tfidf_name_taking | tfidf_name_tale | tfidf_name_talk | tfidf_name_talking | tfidf_name_tanner | tfidf_name_tattoo | tfidf_name_tea | tfidf_name_teach | tfidf_name_team | tfidf_name_teasers | tfidf_name_techniques | tfidf_name_terror | tfidf_name_text | tfidf_name_than | tfidf_name_that | tfidf_name_the | tfidf_name_their | tfidf_name_thief | tfidf_name_things | tfidf_name_thinking | tfidf_name_third | tfidf_name_thirteen | tfidf_name_this | tfidf_name_thomas | tfidf_name_thoughts | tfidf_name_thousand | tfidf_name_thousands | tfidf_name_three | tfidf_name_throne | tfidf_name_thrones | tfidf_name_thug | tfidf_name_tidying | tfidf_name_time | tfidf_name_tina | tfidf_name_tipping | tfidf_name_titans | tfidf_name_to | tfidf_name_toddlers | tfidf_name_told | tfidf_name_toltec | tfidf_name_too | tfidf_name_tools | tfidf_name_total | tfidf_name_towers | tfidf_name_toxic | tfidf_name_tragedy | tfidf_name_train | tfidf_name_trauma | tfidf_name_travel | tfidf_name_trilogy | tfidf_name_true | tfidf_name_trust | tfidf_name_truth | tfidf_name_try | tfidf_name_twilight | tfidf_name_two | tfidf_name_unbroken | tfidf_name_underpants | tfidf_name_united | tfidf_name_unlock | tfidf_name_up | tfidf_name_us | tfidf_name_users | tfidf_name_very | tfidf_name_vol | tfidf_name_volume | tfidf_name_war | tfidf_name_wash | tfidf_name_way | tfidf_name_we | tfidf_name_week | tfidf_name_weight | tfidf_name_were | tfidf_name_what | tfidf_name_wheat | tfidf_name_wheel | tfidf_name_when | tfidf_name_where | tfidf_name_white | tfidf_name_who | tfidf_name_whole30 | tfidf_name_why | tfidf_name_wife | tfidf_name_wild | tfidf_name_will | tfidf_name_wimpy | tfidf_name_win | tfidf_name_wisdom | tfidf_name_with | tfidf_name_women | tfidf_name_wonder | tfidf_name_wonderful | tfidf_name_wonky | tfidf_name_words | tfidf_name_world | tfidf_name_you | tfidf_name_you'll | tfidf_name_your | tfidf_name_zone | tfidf_name_zoo |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| -1.50571868 | -0.8285292 | 0.7962705 | 4 | 0.9015021 | -0.1492394 | -0.04714045 | -0.110236 | -0.08581185 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.1203383 | -0.1426983 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1223608 | -0.08026371 | -0.04714045 | -0.1172005 | -0.04714045 | -0.06674103 | -0.1781026 | -0.06674103 | -0.04714045 | -0.06525315 | -0.06674103 | -0.09174882 | -0.04714045 | -0.1505881 | -0.1420555 | -0.04714045 | -0.08049407 | 3.3637606 | -0.09824361 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1082732 | -0.04714045 | -0.06674103 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06615299 | -0.1044831 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.09420321 | -0.04714045 | -0.1783099 | -0.09337989 | -0.1708534 | -0.0660673 | -0.4167383 | -0.04714045 | -0.09256043 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1237127 | -0.04714045 | -0.1210515 | -0.06626352 | -0.04714045 | -0.06674103 | -0.1505881 | -0.1156064 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.05719618 | -0.09459746 | -0.04714045 | -0.04714045 | -0.07943828 | -0.04714045 | -0.09459746 | -0.04714045 | -0.04714045 | -0.08130992 | -0.1048871 | -0.07529404 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.06889929 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08146842 | -0.06674103 | -0.04714045 | -0.08121622 | -0.06674103 | -0.1016855 | -0.09750765 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.09240317 | -0.04714045 | -0.07354929 | -0.09848498 | -0.04714045 | -0.3409382 | -0.1057687 | -0.04714045 | -0.04714045 | -0.04714045 | -0.0964032 | -0.04714045 | -0.06674103 | -0.09410592 | -0.04714045 | -0.06617796 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1172967 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08183212 | -0.04714045 | -0.04714045 | -0.09857689 | -0.1295147 | -0.04714045 | -0.04714045 | -0.11587 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.1255637 | -0.04714045 | -0.04714045 | -0.06416229 | -0.04714045 | -0.06674103 | -0.1293958 | -0.06674103 | -0.08183212 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08171052 | -0.04714045 | -0.105491 | -0.08180999 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06416229 | -0.04714045 | -0.06330197 | -0.06674103 | -0.04714045 | -0.127022 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.09459746 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.08130992 | -0.04714045 | -0.1471225 | -0.08183212 | -0.08112843 | -0.06633102 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08183212 | -0.08934328 | -0.06659255 | -0.04714045 | -0.04714045 | -0.04714045 | -0.11587 | -0.04714045 | -0.06674103 | -0.04714045 | -0.08180999 | -0.04714045 | -0.06674103 | -0.06674103 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1237857 | -0.04714045 | -0.06227454 | -0.06674103 | -0.04714045 | -0.04714045 | -0.1130823 | -0.06525315 | -0.08107111 | -0.08183212 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08183212 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06670121 | -0.04714045 | -0.06674103 | -0.1418956 | -0.04714045 | -0.09316993 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.07872342 | -0.04714045 | -0.1003208 | -0.04714045 | -0.04714045 | -0.1315247 | -0.04714045 | -0.1056972 | -0.06674103 | -0.04714045 | -0.04714045 | -0.09459746 | -0.06491832 | -0.06674103 | -0.08282482 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.06674103 | -0.04714045 | -0.1058819 | -0.04714045 | -0.1044032 | -0.115415 | -0.04714045 | -0.04714045 | -0.07092784 | -0.04714045 | -0.2095443 | -0.08183212 | -0.1255637 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08183212 | -0.04714045 | -0.06674103 | -0.06642931 | -0.06674103 | -0.06674103 | -0.06674103 | -0.06674103 | -0.06674103 | -0.1142516 | -0.1058819 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | 16.69656801 | -0.04714045 | -0.1151256 | -0.08227817 | -0.06543935 | -0.08183212 | -0.04714045 | -0.04714045 | -0.08180999 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1007641 | -0.04714045 | -0.04714045 | -0.1086785 | -0.06674103 | -0.1056379 | -0.04714045 | -0.04714045 | -0.1058819 | -0.09410592 | -0.04714045 | -0.04714045 | -0.05856169 | -0.1167537 | -0.04714045 | -0.2440958 | -0.04714045 | -0.06556575 | -0.04714045 | -0.1044831 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07998879 | -0.04714045 | -0.124363 | -0.04714045 | -0.06674103 | -0.1503954 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.09169931 | -0.1460621 | -0.06670121 | -0.04714045 | -0.08183212 | -0.04714045 | -0.04714045 | -0.06662535 | -0.04714045 | -0.06514489 | -0.04714045 | -0.06674103 | -0.1161184 | -0.1204415 | -0.04714045 | -0.07137192 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1341687 | -0.04714045 | -0.04714045 | -0.09410592 | -0.06674103 | -0.06674103 | -0.08635 | -0.1351465 | -0.08934328 | -0.0656204 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1140338 | -0.09459746 | -0.04714045 | -0.0870768 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1890469 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1379494 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07361686 | -0.04714045 | -0.04714045 | -0.05627064 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08077688 | -0.04714045 | -0.09107652 | -0.04714045 | -0.04714045 | 21.16606298 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06671656 | -0.08991972 | -0.08141501 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08818622 | -0.04714045 | -0.06674103 | -0.04714045 | -0.06674103 | -0.04714045 | -0.1255637 | -0.06674103 | -0.08183212 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06416229 | -0.1500232 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1460621 | -0.1255637 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08358194 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.07944875 | -0.1054552 | -0.04714045 | -0.0817896 | -0.06674103 | -0.06674103 | -0.2529304 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.06671027 | -0.08112843 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.08036796 | -0.06622337 | -0.04714045 | -0.04714045 | -0.08175178 | -0.04714045 | -0.04714045 | -0.08183212 | -0.09180441 | -0.06674103 | -0.1156614 | -0.05940107 | -0.04714045 | -0.04714045 | -0.06260929 | -0.08171052 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1418956 | -0.1673911 | -0.1058819 | -0.04714045 | -0.06674103 | -0.1080531 | -0.08180999 | -0.06674103 | -0.08183212 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.134385 | -0.07964131 | -0.134385 | -0.09459746 | -0.04714045 | -0.1155152 | -0.04714045 | -0.08453476 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.1255637 | -0.04714045 | -0.07044155 | -0.1160197 | -0.04714045 | -0.04714045 | -0.09410592 | -0.04714045 | -0.10582 | -0.06674103 | -0.04714045 | -0.04714045 | 3.8918705 | -0.1039193 | -0.1241045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.0612029 | -0.04714045 | -0.08151339 | -0.05966836 | -0.09459746 | -0.1779864 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.09444883 | -0.04714045 | -0.07690057 | -0.1131106 | -0.1391449 | -0.06674103 | -0.06661048 | -0.1680313 | -0.06416229 | -0.04714045 | -0.04714045 | -0.06633102 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07872342 | -0.04714045 | -0.06674103 | -0.111536 | -0.06674103 | -0.05719618 | -0.06674103 | -0.0944808 | -0.09246799 | -0.04714045 | -0.04714045 | -0.08115966 | -0.1058819 | -0.08183212 | -0.06391453 | -0.04714045 | -0.04714045 | -0.09966922 | -0.07868789 | -0.04714045 | -0.06638519 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08839375 | -0.04714045 | -0.06662535 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06617796 | -0.08262232 | -0.06356299 | -0.06674103 | -0.06674103 | -0.08373561 | -0.0807445 | -0.1783251 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.09750765 | -0.0577271 | -0.04714045 | -0.5042883 | -0.1319252 | -0.1255637 | -0.04714045 | -0.06674103 | -0.08175178 | -0.06674103 | -0.06674103 | -0.1215546 | -0.1357185 | -0.04714045 | -0.06416229 | -0.04714045 | -0.06447796 | -0.08183212 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.09459746 | -0.1023163 | -0.11911 | -0.04714045 | -0.04714045 | -0.06377736 | -0.08183212 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06659255 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1030436 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06132345 | -0.04714045 | -0.104031 | -0.04714045 | -0.1424384 | -0.08175178 | -0.04714045 | -0.1643958 | -0.04714045 | -0.08457259 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1255637 | -0.0809096 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08112843 | -0.04714045 | -0.09107652 | -0.04714045 | -0.04714045 | -0.04714045 | -0.0932938 | -0.1255637 | -0.1141694 | -0.04714045 | -0.04714045 | -0.06576639 | -0.08183212 | -0.04714045 | -0.08112843 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06670618 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1505881 | -0.1505881 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.06674103 | -0.04714045 | -0.06674103 | -0.04714045 | -0.08183212 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.06596154 | -0.04714045 | -0.06674103 | -0.1187755 | -0.04714045 | -0.04714045 | -0.09459746 | -0.08183212 | -0.08183212 | -0.04714045 | -0.06654357 | -0.04714045 | -0.1054963 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.05791563 | -0.04714045 | -0.05615139 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06502453 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.1069175 | -0.04714045 | -0.04714045 | -0.1153898 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07317727 | -0.04714045 | -0.06674103 | -0.09452013 | -0.04714045 | -0.04714045 | -0.1503501 | -0.04714045 | -0.08102054 | -0.04714045 | -0.04714045 | -0.1705609 | -0.04714045 | -0.04714045 | -0.04714045 | -0.0964032 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.1007641 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.06391453 | -0.08584293 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07908111 | -0.04714045 | -0.06657067 | -0.09459746 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07932692 | -0.06662535 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07932692 | -0.08183212 | -0.1058516 | -0.06073559 | -0.06674103 | -0.04714045 | -0.06674103 | -0.08099862 | -0.06502453 | -0.04714045 | -0.06674103 | -0.1469904 | -0.04714045 | -0.04714045 | -0.08180999 | 6.6233834 | -0.05387103 | -0.04714045 | -0.04714045 | -0.1426983 | -0.07744647 | -0.06674103 | -0.1153898 | -0.04714045 | -0.04714045 | -0.06670121 | -0.04714045 | -0.06701863 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06437938 | -0.1056668 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08180999 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06330197 | -0.04714045 | -0.04714045 | -0.05504269 | -0.04714045 | -0.06674103 | -0.04714045 | -0.06674103 | -0.06674103 | -0.06674103 | -0.1058819 | -0.04714045 | -0.08167683 | -0.06659255 | -0.04714045 | -0.08039799 | -0.2180258 | -0.85809913 | -0.06674103 | -0.04714045 | -0.1203103 | -0.06674103 | -0.04714045 | -0.04714045 | -0.08085704 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.09380314 | -0.04714045 | -0.07906384 | -0.08183212 | -0.08183212 | -0.1077152 | -0.04714045 | -0.04714045 | -0.04714045 | -0.3635161 | -0.04714045 | -0.04714045 | -0.09459746 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.06674103 | -0.06132345 | -0.06674103 | -0.06674103 | -0.1270799 | 12.95396910 | -0.06674103 | -0.1036071 | -0.06674103 | -0.112243 | -0.06425878 | -0.09459746 | -0.11587 | -0.06073559 | -0.06674103 | -0.09429395 | -0.06491832 | -0.06674103 | -0.1255637 | -0.06502453 | -0.06885996 | -0.1239419 | -0.06674103 | -0.06588576 | -0.06654357 | -0.06525315 | -0.1051144 | -0.06674103 | -0.1156589 | -0.06387334 | -0.06633102 | -0.06640834 | -0.1171896 | -0.07966228 | -0.0936996 | -0.06674103 | -0.1409088 | -0.06473981 | -0.08487739 | -0.1008278 | -0.1418956 | -0.06674103 | -0.1055584 | -0.1661186 | -0.08116132 | -0.09459746 | -0.08183212 | -0.06674103 | -0.08183212 | -0.1583724 | -0.2049717 | -0.1255637 | -0.1792152 | -0.05233905 | -0.09180441 |
| -1.22138238 | -0.6413027 | 0.7962705 | 7 | -1.1067947 | -0.1492394 | -0.04714045 | -0.110236 | -0.08581185 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.1203383 | -0.1426983 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1223608 | -0.08026371 | -0.04714045 | -0.1172005 | -0.04714045 | -0.06674103 | 5.7167503 | -0.06674103 | -0.04714045 | -0.06525315 | -0.06674103 | -0.09174882 | -0.04714045 | -0.1505881 | -0.1420555 | -0.04714045 | -0.08049407 | -0.4615286 | -0.09824361 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1082732 | -0.04714045 | -0.06674103 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06615299 | -0.1044831 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.09420321 | -0.04714045 | -0.1783099 | -0.09337989 | -0.1708534 | -0.0660673 | 1.6361451 | -0.04714045 | -0.09256043 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1237127 | -0.04714045 | -0.1210515 | -0.06626352 | -0.04714045 | -0.06674103 | -0.1505881 | -0.1156064 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.05719618 | -0.09459746 | -0.04714045 | -0.04714045 | -0.07943828 | -0.04714045 | -0.09459746 | -0.04714045 | -0.04714045 | -0.08130992 | -0.1048871 | -0.07529404 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.06889929 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08146842 | -0.06674103 | -0.04714045 | -0.08121622 | -0.06674103 | -0.1016855 | -0.09750765 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.09240317 | -0.04714045 | -0.07354929 | -0.09848498 | -0.04714045 | 1.9037651 | -0.1057687 | -0.04714045 | -0.04714045 | -0.04714045 | -0.0964032 | -0.04714045 | -0.06674103 | -0.09410592 | -0.04714045 | -0.06617796 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1172967 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08183212 | -0.04714045 | -0.04714045 | -0.09857689 | -0.1295147 | -0.04714045 | -0.04714045 | -0.11587 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.1255637 | -0.04714045 | -0.04714045 | -0.06416229 | -0.04714045 | -0.06674103 | -0.1293958 | -0.06674103 | -0.08183212 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08171052 | -0.04714045 | -0.105491 | -0.08180999 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06416229 | -0.04714045 | -0.06330197 | -0.06674103 | -0.04714045 | -0.127022 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.09459746 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.08130992 | -0.04714045 | -0.1471225 | -0.08183212 | -0.08112843 | -0.06633102 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08183212 | -0.08934328 | -0.06659255 | -0.04714045 | -0.04714045 | -0.04714045 | -0.11587 | -0.04714045 | -0.06674103 | -0.04714045 | -0.08180999 | -0.04714045 | -0.06674103 | -0.06674103 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1237857 | -0.04714045 | -0.06227454 | -0.06674103 | -0.04714045 | -0.04714045 | -0.1130823 | -0.06525315 | -0.08107111 | -0.08183212 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08183212 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06670121 | -0.04714045 | -0.06674103 | -0.1418956 | -0.04714045 | -0.09316993 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.07872342 | -0.04714045 | -0.1003208 | -0.04714045 | -0.04714045 | -0.1315247 | -0.04714045 | -0.1056972 | -0.06674103 | -0.04714045 | -0.04714045 | -0.09459746 | -0.06491832 | -0.06674103 | -0.08282482 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.06674103 | -0.04714045 | -0.1058819 | -0.04714045 | -0.1044032 | -0.115415 | -0.04714045 | -0.04714045 | -0.07092784 | -0.04714045 | -0.2095443 | -0.08183212 | -0.1255637 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08183212 | -0.04714045 | -0.06674103 | -0.06642931 | -0.06674103 | -0.06674103 | -0.06674103 | -0.06674103 | -0.06674103 | -0.1142516 | -0.1058819 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06622337 | -0.04714045 | -0.1151256 | -0.08227817 | -0.06543935 | -0.08183212 | -0.04714045 | -0.04714045 | -0.08180999 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1007641 | -0.04714045 | -0.04714045 | -0.1086785 | -0.06674103 | -0.1056379 | -0.04714045 | -0.04714045 | -0.1058819 | -0.09410592 | -0.04714045 | -0.04714045 | -0.05856169 | -0.1167537 | -0.04714045 | -0.2440958 | -0.04714045 | -0.06556575 | -0.04714045 | -0.1044831 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07998879 | -0.04714045 | -0.124363 | -0.04714045 | -0.06674103 | -0.1503954 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.09169931 | -0.1460621 | -0.06670121 | -0.04714045 | -0.08183212 | -0.04714045 | -0.04714045 | -0.06662535 | -0.04714045 | -0.06514489 | -0.04714045 | -0.06674103 | -0.1161184 | -0.1204415 | -0.04714045 | -0.07137192 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1341687 | -0.04714045 | -0.04714045 | -0.09410592 | -0.06674103 | -0.06674103 | -0.08635 | -0.1351465 | -0.08934328 | -0.0656204 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1140338 | -0.09459746 | -0.04714045 | -0.0870768 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1890469 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1379494 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07361686 | -0.04714045 | -0.04714045 | -0.05627064 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08077688 | -0.04714045 | -0.09107652 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06671656 | -0.08991972 | -0.08141501 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08818622 | -0.04714045 | -0.06674103 | -0.04714045 | -0.06674103 | -0.04714045 | -0.1255637 | -0.06674103 | -0.08183212 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06416229 | -0.1500232 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1460621 | -0.1255637 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08358194 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.07944875 | -0.1054552 | -0.04714045 | -0.0817896 | -0.06674103 | -0.06674103 | -0.2529304 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.06671027 | -0.08112843 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.08036796 | -0.06622337 | -0.04714045 | -0.04714045 | 12.56422724 | -0.04714045 | -0.04714045 | -0.08183212 | -0.09180441 | -0.06674103 | -0.1156614 | -0.05940107 | -0.04714045 | -0.04714045 | -0.06260929 | -0.08171052 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1418956 | -0.1673911 | -0.1058819 | -0.04714045 | -0.06674103 | -0.1080531 | -0.08180999 | -0.06674103 | -0.08183212 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.134385 | 5.57908346 | -0.134385 | -0.09459746 | -0.04714045 | -0.1155152 | -0.04714045 | -0.08453476 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.1255637 | -0.04714045 | -0.07044155 | -0.1160197 | -0.04714045 | -0.04714045 | -0.09410592 | -0.04714045 | -0.10582 | -0.06674103 | -0.04714045 | -0.04714045 | -0.1105379 | -0.1039193 | -0.1241045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.0612029 | -0.04714045 | -0.08151339 | -0.05966836 | -0.09459746 | -0.1779864 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.09444883 | -0.04714045 | -0.07690057 | -0.1131106 | -0.1391449 | -0.06674103 | -0.06661048 | -0.1680313 | -0.06416229 | -0.04714045 | -0.04714045 | -0.06633102 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07872342 | -0.04714045 | -0.06674103 | -0.111536 | -0.06674103 | -0.05719618 | -0.06674103 | -0.0944808 | -0.09246799 | -0.04714045 | -0.04714045 | -0.08115966 | -0.1058819 | -0.08183212 | -0.06391453 | -0.04714045 | -0.04714045 | -0.09966922 | -0.07868789 | -0.04714045 | -0.06638519 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08839375 | -0.04714045 | -0.06662535 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06617796 | -0.08262232 | -0.06356299 | -0.06674103 | -0.06674103 | -0.08373561 | -0.0807445 | -0.1783251 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.09750765 | -0.0577271 | -0.04714045 | -0.5042883 | -0.1319252 | -0.1255637 | -0.04714045 | 14.94999071 | 12.56422724 | -0.06674103 | -0.06674103 | -0.1215546 | -0.1357185 | -0.04714045 | -0.06416229 | -0.04714045 | -0.06447796 | -0.08183212 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.09459746 | -0.1023163 | -0.11911 | -0.04714045 | -0.04714045 | -0.06377736 | -0.08183212 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06659255 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1030436 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06132345 | -0.04714045 | -0.104031 | -0.04714045 | -0.1424384 | 12.56422724 | -0.04714045 | -0.1643958 | -0.04714045 | -0.08457259 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1255637 | -0.0809096 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08112843 | -0.04714045 | -0.09107652 | -0.04714045 | -0.04714045 | -0.04714045 | -0.0932938 | -0.1255637 | -0.1141694 | -0.04714045 | -0.04714045 | -0.06576639 | -0.08183212 | -0.04714045 | -0.08112843 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06670618 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1505881 | -0.1505881 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.06674103 | -0.04714045 | -0.06674103 | -0.04714045 | -0.08183212 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.06596154 | -0.04714045 | -0.06674103 | -0.1187755 | -0.04714045 | -0.04714045 | -0.09459746 | -0.08183212 | -0.08183212 | -0.04714045 | -0.06654357 | -0.04714045 | -0.1054963 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.05791563 | -0.04714045 | -0.05615139 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06502453 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.1069175 | -0.04714045 | -0.04714045 | -0.1153898 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07317727 | -0.04714045 | -0.06674103 | -0.09452013 | -0.04714045 | -0.04714045 | -0.1503501 | -0.04714045 | -0.08102054 | -0.04714045 | -0.04714045 | -0.1705609 | -0.04714045 | -0.04714045 | -0.04714045 | -0.0964032 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.1007641 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.06391453 | -0.08584293 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07908111 | -0.04714045 | -0.06657067 | -0.09459746 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07932692 | -0.06662535 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07932692 | -0.08183212 | -0.1058516 | -0.06073559 | -0.06674103 | -0.04714045 | -0.06674103 | -0.08099862 | -0.06502453 | -0.04714045 | -0.06674103 | -0.1469904 | -0.04714045 | -0.04714045 | -0.08180999 | -0.1088952 | -0.05387103 | -0.04714045 | -0.04714045 | -0.1426983 | -0.07744647 | -0.06674103 | -0.1153898 | -0.04714045 | -0.04714045 | -0.06670121 | -0.04714045 | -0.06701863 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06437938 | -0.1056668 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08180999 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06330197 | -0.04714045 | -0.04714045 | -0.05504269 | -0.04714045 | -0.06674103 | -0.04714045 | -0.06674103 | -0.06674103 | -0.06674103 | -0.1058819 | -0.04714045 | -0.08167683 | -0.06659255 | -0.04714045 | -0.08039799 | -0.2180258 | 0.78807240 | -0.06674103 | -0.04714045 | -0.1203103 | -0.06674103 | -0.04714045 | -0.04714045 | -0.08085704 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.09380314 | -0.04714045 | -0.07906384 | -0.08183212 | -0.08183212 | -0.1077152 | -0.04714045 | -0.04714045 | -0.04714045 | -0.3635161 | -0.04714045 | -0.04714045 | -0.09459746 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.06674103 | -0.06132345 | -0.06674103 | -0.06674103 | -0.1270799 | -0.09310869 | -0.06674103 | -0.1036071 | -0.06674103 | -0.112243 | -0.06425878 | -0.09459746 | -0.11587 | -0.06073559 | -0.06674103 | -0.09429395 | -0.06491832 | -0.06674103 | -0.1255637 | -0.06502453 | -0.06885996 | -0.1239419 | -0.06674103 | -0.06588576 | -0.06654357 | -0.06525315 | -0.1051144 | -0.06674103 | -0.1156589 | -0.06387334 | -0.06633102 | -0.06640834 | -0.1171896 | -0.07966228 | -0.0936996 | -0.06674103 | -0.1409088 | -0.06473981 | -0.08487739 | -0.1008278 | -0.1418956 | -0.06674103 | -0.1055584 | -0.1661186 | -0.08116132 | -0.09459746 | -0.08183212 | -0.06674103 | -0.08183212 | -0.1583724 | -0.2049717 | -0.1255637 | -0.1792152 | -0.05233905 | -0.09180441 |
| -0.08403717 | -0.3670554 | -0.5889939 | 46 | 0.9015021 | -0.1492394 | -0.04714045 | -0.110236 | -0.08581185 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.1203383 | -0.1426983 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1223608 | -0.08026371 | -0.04714045 | -0.1172005 | -0.04714045 | -0.06674103 | -0.1781026 | -0.06674103 | -0.04714045 | -0.06525315 | -0.06674103 | -0.09174882 | -0.04714045 | 6.6258752 | -0.1420555 | -0.04714045 | -0.08049407 | -0.4615286 | -0.09824361 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1082732 | -0.04714045 | -0.06674103 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06615299 | -0.1044831 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.09420321 | -0.04714045 | 4.8175959 | -0.09337989 | -0.1708534 | -0.0660673 | -0.4167383 | -0.04714045 | -0.09256043 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1237127 | -0.04714045 | -0.1210515 | -0.06626352 | -0.04714045 | -0.06674103 | 6.6258752 | -0.1156064 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.05719618 | -0.09459746 | -0.04714045 | -0.04714045 | -0.07943828 | -0.04714045 | -0.09459746 | -0.04714045 | -0.04714045 | -0.08130992 | -0.1048871 | -0.07529404 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.06889929 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08146842 | -0.06674103 | -0.04714045 | -0.08121622 | -0.06674103 | -0.1016855 | -0.09750765 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.09240317 | -0.04714045 | -0.07354929 | -0.09848498 | -0.04714045 | -0.3409382 | -0.1057687 | -0.04714045 | -0.04714045 | -0.04714045 | -0.0964032 | -0.04714045 | -0.06674103 | -0.09410592 | -0.04714045 | -0.06617796 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1172967 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08183212 | -0.04714045 | -0.04714045 | -0.09857689 | -0.1295147 | -0.04714045 | -0.04714045 | -0.11587 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.1255637 | -0.04714045 | -0.04714045 | -0.06416229 | -0.04714045 | -0.06674103 | -0.1293958 | -0.06674103 | -0.08183212 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08171052 | -0.04714045 | -0.105491 | -0.08180999 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06416229 | -0.04714045 | -0.06330197 | -0.06674103 | -0.04714045 | -0.127022 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.09459746 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.08130992 | -0.04714045 | -0.1471225 | -0.08183212 | -0.08112843 | -0.06633102 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08183212 | -0.08934328 | -0.06659255 | -0.04714045 | -0.04714045 | -0.04714045 | -0.11587 | -0.04714045 | -0.06674103 | -0.04714045 | -0.08180999 | -0.04714045 | -0.06674103 | -0.06674103 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1237857 | -0.04714045 | -0.06227454 | -0.06674103 | -0.04714045 | -0.04714045 | -0.1130823 | -0.06525315 | -0.08107111 | -0.08183212 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08183212 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06670121 | -0.04714045 | -0.06674103 | -0.1418956 | -0.04714045 | -0.09316993 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.07872342 | -0.04714045 | -0.1003208 | -0.04714045 | -0.04714045 | -0.1315247 | -0.04714045 | -0.1056972 | -0.06674103 | -0.04714045 | -0.04714045 | -0.09459746 | -0.06491832 | -0.06674103 | -0.08282482 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.06674103 | -0.04714045 | -0.1058819 | -0.04714045 | -0.1044032 | -0.115415 | -0.04714045 | -0.04714045 | -0.07092784 | -0.04714045 | 5.5229656 | -0.08183212 | -0.1255637 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08183212 | -0.04714045 | -0.06674103 | -0.06642931 | -0.06674103 | -0.06674103 | -0.06674103 | -0.06674103 | -0.06674103 | -0.1142516 | -0.1058819 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06622337 | -0.04714045 | -0.1151256 | -0.08227817 | -0.06543935 | -0.08183212 | -0.04714045 | -0.04714045 | -0.08180999 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1007641 | -0.04714045 | -0.04714045 | -0.1086785 | -0.06674103 | -0.1056379 | -0.04714045 | -0.04714045 | -0.1058819 | -0.09410592 | -0.04714045 | -0.04714045 | -0.05856169 | -0.1167537 | -0.04714045 | -0.2440958 | -0.04714045 | -0.06556575 | -0.04714045 | -0.1044831 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07998879 | -0.04714045 | -0.124363 | -0.04714045 | -0.06674103 | -0.1503954 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.09169931 | -0.1460621 | -0.06670121 | -0.04714045 | -0.08183212 | -0.04714045 | -0.04714045 | -0.06662535 | -0.04714045 | -0.06514489 | -0.04714045 | -0.06674103 | -0.1161184 | -0.1204415 | -0.04714045 | -0.07137192 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1341687 | -0.04714045 | -0.04714045 | -0.09410592 | -0.06674103 | -0.06674103 | -0.08635 | -0.1351465 | -0.08934328 | -0.0656204 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1140338 | -0.09459746 | -0.04714045 | -0.0870768 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1890469 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1379494 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07361686 | -0.04714045 | -0.04714045 | -0.05627064 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08077688 | -0.04714045 | -0.09107652 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06671656 | -0.08991972 | -0.08141501 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08818622 | -0.04714045 | -0.06674103 | -0.04714045 | -0.06674103 | -0.04714045 | -0.1255637 | -0.06674103 | -0.08183212 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06416229 | -0.1500232 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1460621 | -0.1255637 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08358194 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.07944875 | -0.1054552 | -0.04714045 | -0.0817896 | -0.06674103 | -0.06674103 | -0.2529304 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.06671027 | -0.08112843 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.08036796 | -0.06622337 | -0.04714045 | -0.04714045 | -0.08175178 | -0.04714045 | -0.04714045 | -0.08183212 | -0.09180441 | -0.06674103 | -0.1156614 | -0.05940107 | -0.04714045 | -0.04714045 | -0.06260929 | -0.08171052 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1418956 | -0.1673911 | -0.1058819 | -0.04714045 | -0.06674103 | -0.1080531 | -0.08180999 | -0.06674103 | -0.08183212 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.134385 | -0.07964131 | -0.134385 | -0.09459746 | -0.04714045 | -0.1155152 | -0.04714045 | -0.08453476 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.1255637 | -0.04714045 | -0.07044155 | -0.1160197 | -0.04714045 | -0.04714045 | -0.09410592 | -0.04714045 | -0.10582 | -0.06674103 | -0.04714045 | -0.04714045 | -0.1105379 | -0.1039193 | -0.1241045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.0612029 | -0.04714045 | -0.08151339 | -0.05966836 | -0.09459746 | -0.1779864 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.09444883 | -0.04714045 | -0.07690057 | -0.1131106 | -0.1391449 | -0.06674103 | -0.06661048 | 5.4595401 | -0.06416229 | -0.04714045 | -0.04714045 | -0.06633102 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07872342 | -0.04714045 | -0.06674103 | -0.111536 | -0.06674103 | -0.05719618 | -0.06674103 | -0.0944808 | -0.09246799 | -0.04714045 | -0.04714045 | -0.08115966 | -0.1058819 | -0.08183212 | -0.06391453 | -0.04714045 | -0.04714045 | -0.09966922 | -0.07868789 | -0.04714045 | -0.06638519 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08839375 | -0.04714045 | -0.06662535 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06617796 | -0.08262232 | -0.06356299 | -0.06674103 | -0.06674103 | -0.08373561 | -0.0807445 | -0.1783251 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.09750765 | -0.0577271 | -0.04714045 | 1.4793468 | -0.1319252 | -0.1255637 | -0.04714045 | -0.06674103 | -0.08175178 | -0.06674103 | -0.06674103 | -0.1215546 | -0.1357185 | -0.04714045 | -0.06416229 | -0.04714045 | -0.06447796 | -0.08183212 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.09459746 | -0.1023163 | -0.11911 | -0.04714045 | -0.04714045 | -0.06377736 | -0.08183212 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06659255 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1030436 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06132345 | -0.04714045 | -0.104031 | -0.04714045 | -0.1424384 | -0.08175178 | -0.04714045 | -0.1643958 | -0.04714045 | -0.08457259 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1255637 | -0.0809096 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08112843 | -0.04714045 | -0.09107652 | -0.04714045 | -0.04714045 | -0.04714045 | -0.0932938 | -0.1255637 | -0.1141694 | -0.04714045 | -0.04714045 | -0.06576639 | -0.08183212 | -0.04714045 | -0.08112843 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06670618 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | 6.6258752 | 6.6258752 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.06674103 | -0.04714045 | -0.06674103 | -0.04714045 | -0.08183212 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.06596154 | -0.04714045 | -0.06674103 | -0.1187755 | -0.04714045 | -0.04714045 | -0.09459746 | -0.08183212 | -0.08183212 | -0.04714045 | -0.06654357 | -0.04714045 | -0.1054963 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.05791563 | -0.04714045 | -0.05615139 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06502453 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.1069175 | -0.04714045 | -0.04714045 | -0.1153898 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07317727 | -0.04714045 | -0.06674103 | -0.09452013 | -0.04714045 | -0.04714045 | -0.1503501 | -0.04714045 | -0.08102054 | -0.04714045 | -0.04714045 | -0.1705609 | -0.04714045 | -0.04714045 | -0.04714045 | -0.0964032 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.1007641 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.06391453 | -0.08584293 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07908111 | -0.04714045 | -0.06657067 | -0.09459746 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07932692 | -0.06662535 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07932692 | -0.08183212 | -0.1058516 | -0.06073559 | -0.06674103 | -0.04714045 | -0.06674103 | -0.08099862 | -0.06502453 | -0.04714045 | -0.06674103 | -0.1469904 | -0.04714045 | -0.04714045 | -0.08180999 | -0.1088952 | -0.05387103 | -0.04714045 | -0.04714045 | -0.1426983 | -0.07744647 | -0.06674103 | -0.1153898 | -0.04714045 | -0.04714045 | -0.06670121 | -0.04714045 | -0.06701863 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06437938 | -0.1056668 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08180999 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06330197 | -0.04714045 | -0.04714045 | -0.05504269 | -0.04714045 | -0.06674103 | -0.04714045 | -0.06674103 | -0.06674103 | -0.06674103 | -0.1058819 | -0.04714045 | -0.08167683 | -0.06659255 | -0.04714045 | -0.08039799 | -0.2180258 | 0.05644061 | -0.06674103 | -0.04714045 | -0.1203103 | -0.06674103 | -0.04714045 | -0.04714045 | -0.08085704 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.09380314 | -0.04714045 | -0.07906384 | -0.08183212 | -0.08183212 | -0.1077152 | -0.04714045 | -0.04714045 | -0.04714045 | -0.3635161 | -0.04714045 | -0.04714045 | -0.09459746 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.06674103 | -0.06132345 | -0.06674103 | -0.06674103 | -0.1270799 | -0.09310869 | -0.06674103 | -0.1036071 | -0.06674103 | -0.112243 | -0.06425878 | -0.09459746 | -0.11587 | -0.06073559 | -0.06674103 | -0.09429395 | -0.06491832 | -0.06674103 | -0.1255637 | -0.06502453 | -0.06885996 | -0.1239419 | -0.06674103 | -0.06588576 | -0.06654357 | -0.06525315 | -0.1051144 | -0.06674103 | -0.1156589 | -0.06387334 | -0.06633102 | -0.06640834 | -0.1171896 | -0.07966228 | -0.0936996 | -0.06674103 | -0.1409088 | -0.06473981 | -0.08487739 | -0.1008278 | -0.1418956 | -0.06674103 | -0.1055584 | -0.1661186 | -0.08116132 | -0.09459746 | -0.08183212 | -0.06674103 | -0.08183212 | -0.1583724 | -0.2049717 | -0.1255637 | -0.1792152 | -0.05233905 | -0.09180441 |
| 1.33764433 | 5.1332263 | 0.7962705 | 15 | -1.1067947 | -0.1492394 | -0.04714045 | -0.110236 | -0.08581185 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.1203383 | -0.1426983 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1223608 | -0.08026371 | -0.04714045 | -0.1172005 | -0.04714045 | -0.06674103 | -0.1781026 | -0.06674103 | -0.04714045 | -0.06525315 | -0.06674103 | -0.09174882 | -0.04714045 | -0.1505881 | -0.1420555 | -0.04714045 | -0.08049407 | -0.4615286 | -0.09824361 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1082732 | -0.04714045 | -0.06674103 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06615299 | -0.1044831 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.09420321 | -0.04714045 | -0.1783099 | -0.09337989 | -0.1708534 | -0.0660673 | -0.4167383 | -0.04714045 | -0.09256043 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1237127 | -0.04714045 | -0.1210515 | -0.06626352 | -0.04714045 | -0.06674103 | -0.1505881 | -0.1156064 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.05719618 | -0.09459746 | -0.04714045 | -0.04714045 | -0.07943828 | -0.04714045 | -0.09459746 | -0.04714045 | -0.04714045 | -0.08130992 | -0.1048871 | -0.07529404 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.06889929 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08146842 | -0.06674103 | -0.04714045 | -0.08121622 | -0.06674103 | -0.1016855 | -0.09750765 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.09240317 | -0.04714045 | -0.07354929 | -0.09848498 | -0.04714045 | -0.3409382 | -0.1057687 | -0.04714045 | -0.04714045 | -0.04714045 | -0.0964032 | -0.04714045 | -0.06674103 | -0.09410592 | -0.04714045 | -0.06617796 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1172967 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08183212 | -0.04714045 | -0.04714045 | -0.09857689 | -0.1295147 | -0.04714045 | -0.04714045 | -0.11587 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.1255637 | -0.04714045 | -0.04714045 | -0.06416229 | -0.04714045 | -0.06674103 | -0.1293958 | -0.06674103 | -0.08183212 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08171052 | -0.04714045 | -0.105491 | -0.08180999 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06416229 | -0.04714045 | -0.06330197 | -0.06674103 | -0.04714045 | -0.127022 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.09459746 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.08130992 | -0.04714045 | -0.1471225 | -0.08183212 | -0.08112843 | -0.06633102 | -0.04714045 | -0.04714045 | -0.04714045 | 21.16606298 | -0.08183212 | -0.08934328 | -0.06659255 | -0.04714045 | -0.04714045 | -0.04714045 | -0.11587 | -0.04714045 | -0.06674103 | -0.04714045 | -0.08180999 | -0.04714045 | -0.06674103 | -0.06674103 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1237857 | -0.04714045 | -0.06227454 | -0.06674103 | -0.04714045 | -0.04714045 | -0.1130823 | -0.06525315 | -0.08107111 | -0.08183212 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08183212 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06670121 | -0.04714045 | -0.06674103 | -0.1418956 | -0.04714045 | -0.09316993 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.07872342 | -0.04714045 | -0.1003208 | -0.04714045 | -0.04714045 | -0.1315247 | -0.04714045 | -0.1056972 | -0.06674103 | -0.04714045 | -0.04714045 | -0.09459746 | -0.06491832 | -0.06674103 | -0.08282482 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.06674103 | -0.04714045 | -0.1058819 | -0.04714045 | -0.1044032 | -0.115415 | -0.04714045 | -0.04714045 | -0.07092784 | -0.04714045 | -0.2095443 | -0.08183212 | -0.1255637 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08183212 | -0.04714045 | -0.06674103 | -0.06642931 | -0.06674103 | -0.06674103 | -0.06674103 | -0.06674103 | -0.06674103 | -0.1142516 | -0.1058819 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06622337 | -0.04714045 | -0.1151256 | -0.08227817 | -0.06543935 | -0.08183212 | -0.04714045 | -0.04714045 | -0.08180999 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1007641 | -0.04714045 | -0.04714045 | -0.1086785 | -0.06674103 | -0.1056379 | -0.04714045 | -0.04714045 | -0.1058819 | -0.09410592 | -0.04714045 | -0.04714045 | -0.05856169 | -0.1167537 | -0.04714045 | -0.2440958 | -0.04714045 | -0.06556575 | -0.04714045 | -0.1044831 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07998879 | -0.04714045 | -0.124363 | -0.04714045 | -0.06674103 | -0.1503954 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.09169931 | -0.1460621 | -0.06670121 | -0.04714045 | -0.08183212 | -0.04714045 | -0.04714045 | -0.06662535 | -0.04714045 | -0.06514489 | -0.04714045 | -0.06674103 | -0.1161184 | -0.1204415 | -0.04714045 | -0.07137192 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1341687 | -0.04714045 | -0.04714045 | -0.09410592 | -0.06674103 | -0.06674103 | -0.08635 | -0.1351465 | -0.08934328 | -0.0656204 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1140338 | -0.09459746 | -0.04714045 | -0.0870768 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1890469 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1379494 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07361686 | -0.04714045 | -0.04714045 | -0.05627064 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08077688 | -0.04714045 | -0.09107652 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06671656 | -0.08991972 | -0.08141501 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08818622 | -0.04714045 | -0.06674103 | -0.04714045 | -0.06674103 | -0.04714045 | -0.1255637 | -0.06674103 | -0.08183212 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06416229 | -0.1500232 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1460621 | -0.1255637 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08358194 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.07944875 | -0.1054552 | -0.04714045 | -0.0817896 | -0.06674103 | -0.06674103 | -0.2529304 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.06671027 | -0.08112843 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.08036796 | -0.06622337 | -0.04714045 | -0.04714045 | -0.08175178 | -0.04714045 | -0.04714045 | -0.08183212 | -0.09180441 | -0.06674103 | -0.1156614 | -0.05940107 | -0.04714045 | -0.04714045 | -0.06260929 | -0.08171052 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1418956 | -0.1673911 | -0.1058819 | -0.04714045 | -0.06674103 | -0.1080531 | -0.08180999 | -0.06674103 | -0.08183212 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.134385 | -0.07964131 | -0.134385 | -0.09459746 | -0.04714045 | -0.1155152 | -0.04714045 | -0.08453476 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.1255637 | -0.04714045 | -0.07044155 | -0.1160197 | -0.04714045 | -0.04714045 | -0.09410592 | -0.04714045 | -0.10582 | -0.06674103 | -0.04714045 | -0.04714045 | -0.1105379 | -0.1039193 | -0.1241045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.0612029 | -0.04714045 | -0.08151339 | -0.05966836 | -0.09459746 | -0.1779864 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.09444883 | -0.04714045 | -0.07690057 | -0.1131106 | -0.1391449 | -0.06674103 | -0.06661048 | -0.1680313 | -0.06416229 | -0.04714045 | -0.04714045 | -0.06633102 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07872342 | -0.04714045 | -0.06674103 | -0.111536 | -0.06674103 | -0.05719618 | -0.06674103 | -0.0944808 | -0.09246799 | -0.04714045 | -0.04714045 | -0.08115966 | -0.1058819 | -0.08183212 | -0.06391453 | -0.04714045 | -0.04714045 | -0.09966922 | -0.07868789 | -0.04714045 | -0.06638519 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08839375 | -0.04714045 | -0.06662535 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06617796 | -0.08262232 | -0.06356299 | -0.06674103 | -0.06674103 | -0.08373561 | -0.0807445 | -0.1783251 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.09750765 | -0.0577271 | -0.04714045 | -0.5042883 | -0.1319252 | -0.1255637 | -0.04714045 | -0.06674103 | -0.08175178 | -0.06674103 | -0.06674103 | -0.1215546 | -0.1357185 | -0.04714045 | -0.06416229 | -0.04714045 | -0.06447796 | -0.08183212 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.09459746 | -0.1023163 | -0.11911 | -0.04714045 | -0.04714045 | -0.06377736 | -0.08183212 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06659255 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1030436 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06132345 | -0.04714045 | -0.104031 | -0.04714045 | -0.1424384 | -0.08175178 | -0.04714045 | -0.1643958 | -0.04714045 | -0.08457259 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1255637 | -0.0809096 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08112843 | -0.04714045 | -0.09107652 | -0.04714045 | -0.04714045 | -0.04714045 | -0.0932938 | -0.1255637 | -0.1141694 | -0.04714045 | -0.04714045 | -0.06576639 | -0.08183212 | -0.04714045 | -0.08112843 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06670618 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1505881 | -0.1505881 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.06674103 | -0.04714045 | -0.06674103 | -0.04714045 | -0.08183212 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.06596154 | -0.04714045 | -0.06674103 | -0.1187755 | -0.04714045 | -0.04714045 | -0.09459746 | -0.08183212 | -0.08183212 | -0.04714045 | -0.06654357 | -0.04714045 | -0.1054963 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.05791563 | -0.04714045 | -0.05615139 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06502453 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.1069175 | -0.04714045 | -0.04714045 | -0.1153898 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07317727 | -0.04714045 | -0.06674103 | -0.09452013 | -0.04714045 | -0.04714045 | -0.1503501 | -0.04714045 | -0.08102054 | -0.04714045 | -0.04714045 | -0.1705609 | -0.04714045 | -0.04714045 | -0.04714045 | -0.0964032 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.1007641 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.06391453 | -0.08584293 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | 21.16606298 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07908111 | -0.04714045 | -0.06657067 | -0.09459746 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07932692 | -0.06662535 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07932692 | -0.08183212 | -0.1058516 | -0.06073559 | -0.06674103 | -0.04714045 | -0.06674103 | -0.08099862 | -0.06502453 | -0.04714045 | -0.06674103 | -0.1469904 | -0.04714045 | -0.04714045 | -0.08180999 | -0.1088952 | -0.05387103 | -0.04714045 | -0.04714045 | -0.1426983 | -0.07744647 | -0.06674103 | -0.1153898 | -0.04714045 | -0.04714045 | -0.06670121 | -0.04714045 | -0.06701863 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06437938 | -0.1056668 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08180999 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06330197 | -0.04714045 | -0.04714045 | -0.05504269 | -0.04714045 | -0.06674103 | -0.04714045 | -0.06674103 | -0.06674103 | -0.06674103 | -0.1058819 | -0.04714045 | -0.08167683 | -0.06659255 | -0.04714045 | -0.08039799 | -0.2180258 | 1.19961528 | -0.06674103 | -0.04714045 | -0.1203103 | -0.06674103 | -0.04714045 | -0.04714045 | -0.08085704 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.09380314 | -0.04714045 | -0.07906384 | -0.08183212 | -0.08183212 | -0.1077152 | -0.04714045 | -0.04714045 | -0.04714045 | -0.3635161 | -0.04714045 | -0.04714045 | -0.09459746 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.06674103 | -0.06132345 | -0.06674103 | -0.06674103 | -0.1270799 | -0.09310869 | -0.06674103 | -0.1036071 | -0.06674103 | -0.112243 | -0.06425878 | -0.09459746 | -0.11587 | -0.06073559 | -0.06674103 | -0.09429395 | -0.06491832 | -0.06674103 | -0.1255637 | -0.06502453 | -0.06885996 | -0.1239419 | -0.06674103 | -0.06588576 | -0.06654357 | -0.06525315 | -0.1051144 | -0.06674103 | -0.1156589 | -0.06387334 | -0.06633102 | -0.06640834 | 12.3073578 | -0.07966228 | -0.0936996 | -0.06674103 | -0.1409088 | -0.06473981 | -0.08487739 | -0.1008278 | -0.1418956 | -0.06674103 | -0.1055584 | -0.1661186 | -0.08116132 | -0.09459746 | -0.08183212 | -0.06674103 | -0.08183212 | -0.1583724 | -0.2049717 | -0.1255637 | -0.1792152 | -0.05233905 | -0.09180441 |
| -0.65270978 | 1.0966839 | 0.7962705 | 16 | 0.9015021 | -0.1492394 | -0.04714045 | -0.110236 | -0.08581185 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.1203383 | -0.1426983 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1223608 | -0.08026371 | -0.04714045 | -0.1172005 | -0.04714045 | -0.06674103 | -0.1781026 | -0.06674103 | -0.04714045 | -0.06525315 | -0.06674103 | -0.09174882 | -0.04714045 | -0.1505881 | -0.1420555 | -0.04714045 | -0.08049407 | 0.7556089 | -0.09824361 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1082732 | -0.04714045 | -0.06674103 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06615299 | -0.1044831 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.09420321 | -0.04714045 | -0.1783099 | -0.09337989 | -0.1708534 | -0.0660673 | 1.4495193 | -0.04714045 | -0.09256043 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1237127 | -0.04714045 | -0.1210515 | -0.06626352 | -0.04714045 | -0.06674103 | -0.1505881 | -0.1156064 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.05719618 | -0.09459746 | -0.04714045 | -0.04714045 | -0.07943828 | -0.04714045 | -0.09459746 | -0.04714045 | -0.04714045 | -0.08130992 | -0.1048871 | -0.07529404 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.06889929 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08146842 | -0.06674103 | -0.04714045 | -0.08121622 | -0.06674103 | -0.1016855 | -0.09750765 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.09240317 | -0.04714045 | -0.07354929 | -0.09848498 | -0.04714045 | -0.3409382 | -0.1057687 | -0.04714045 | -0.04714045 | -0.04714045 | -0.0964032 | -0.04714045 | -0.06674103 | -0.09410592 | -0.04714045 | -0.06617796 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1172967 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08183212 | -0.04714045 | -0.04714045 | -0.09857689 | -0.1295147 | -0.04714045 | -0.04714045 | -0.11587 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.1255637 | -0.04714045 | -0.04714045 | -0.06416229 | -0.04714045 | -0.06674103 | -0.1293958 | -0.06674103 | -0.08183212 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08171052 | -0.04714045 | -0.105491 | -0.08180999 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06416229 | -0.04714045 | -0.06330197 | -0.06674103 | -0.04714045 | -0.127022 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.09459746 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.08130992 | -0.04714045 | -0.1471225 | -0.08183212 | -0.08112843 | -0.06633102 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08183212 | -0.08934328 | -0.06659255 | -0.04714045 | -0.04714045 | -0.04714045 | -0.11587 | -0.04714045 | -0.06674103 | -0.04714045 | -0.08180999 | -0.04714045 | -0.06674103 | -0.06674103 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1237857 | -0.04714045 | -0.06227454 | -0.06674103 | -0.04714045 | -0.04714045 | -0.1130823 | -0.06525315 | -0.08107111 | -0.08183212 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08183212 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06670121 | -0.04714045 | -0.06674103 | -0.1418956 | -0.04714045 | -0.09316993 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.07872342 | -0.04714045 | -0.1003208 | -0.04714045 | -0.04714045 | -0.1315247 | -0.04714045 | -0.1056972 | -0.06674103 | -0.04714045 | -0.04714045 | -0.09459746 | -0.06491832 | -0.06674103 | -0.08282482 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.06674103 | -0.04714045 | -0.1058819 | -0.04714045 | -0.1044032 | -0.115415 | -0.04714045 | -0.04714045 | -0.07092784 | -0.04714045 | -0.2095443 | -0.08183212 | -0.1255637 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08183212 | -0.04714045 | -0.06674103 | -0.06642931 | -0.06674103 | -0.06674103 | -0.06674103 | -0.06674103 | -0.06674103 | -0.1142516 | -0.1058819 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06622337 | -0.04714045 | -0.1151256 | -0.08227817 | -0.06543935 | -0.08183212 | -0.04714045 | -0.04714045 | -0.08180999 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1007641 | -0.04714045 | -0.04714045 | -0.1086785 | -0.06674103 | -0.1056379 | -0.04714045 | -0.04714045 | -0.1058819 | -0.09410592 | -0.04714045 | -0.04714045 | -0.05856169 | -0.1167537 | -0.04714045 | -0.2440958 | -0.04714045 | -0.06556575 | -0.04714045 | -0.1044831 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07998879 | -0.04714045 | -0.124363 | -0.04714045 | -0.06674103 | -0.1503954 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.09169931 | -0.1460621 | -0.06670121 | -0.04714045 | -0.08183212 | -0.04714045 | -0.04714045 | -0.06662535 | -0.04714045 | -0.06514489 | -0.04714045 | -0.06674103 | -0.1161184 | -0.1204415 | -0.04714045 | -0.07137192 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1341687 | -0.04714045 | -0.04714045 | -0.09410592 | -0.06674103 | -0.06674103 | -0.08635 | -0.1351465 | -0.08934328 | -0.0656204 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1140338 | -0.09459746 | -0.04714045 | -0.0870768 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1890469 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1379494 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07361686 | -0.04714045 | -0.04714045 | -0.05627064 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08077688 | -0.04714045 | -0.09107652 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06671656 | -0.08991972 | -0.08141501 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08818622 | -0.04714045 | -0.06674103 | -0.04714045 | -0.06674103 | -0.04714045 | -0.1255637 | -0.06674103 | -0.08183212 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06416229 | -0.1500232 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1460621 | -0.1255637 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08358194 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.07944875 | 9.8104818 | -0.04714045 | -0.0817896 | -0.06674103 | -0.06674103 | -0.2529304 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.06671027 | -0.08112843 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.08036796 | -0.06622337 | -0.04714045 | -0.04714045 | -0.08175178 | -0.04714045 | -0.04714045 | -0.08183212 | -0.09180441 | -0.06674103 | -0.1156614 | -0.05940107 | -0.04714045 | -0.04714045 | -0.06260929 | -0.08171052 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1418956 | -0.1673911 | -0.1058819 | -0.04714045 | -0.06674103 | -0.1080531 | -0.08180999 | -0.06674103 | -0.08183212 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.134385 | -0.07964131 | -0.134385 | -0.09459746 | -0.04714045 | -0.1155152 | -0.04714045 | -0.08453476 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.1255637 | -0.04714045 | -0.07044155 | -0.1160197 | -0.04714045 | -0.04714045 | -0.09410592 | -0.04714045 | -0.10582 | -0.06674103 | -0.04714045 | -0.04714045 | -0.1105379 | -0.1039193 | -0.1241045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.0612029 | -0.04714045 | -0.08151339 | -0.05966836 | -0.09459746 | -0.1779864 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.09444883 | -0.04714045 | -0.07690057 | -0.1131106 | -0.1391449 | -0.06674103 | -0.06661048 | -0.1680313 | -0.06416229 | -0.04714045 | -0.04714045 | -0.06633102 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07872342 | -0.04714045 | -0.06674103 | -0.111536 | -0.06674103 | -0.05719618 | -0.06674103 | -0.0944808 | -0.09246799 | -0.04714045 | -0.04714045 | -0.08115966 | -0.1058819 | -0.08183212 | -0.06391453 | -0.04714045 | -0.04714045 | -0.09966922 | -0.07868789 | -0.04714045 | -0.06638519 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08839375 | -0.04714045 | -0.06662535 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06617796 | -0.08262232 | -0.06356299 | -0.06674103 | -0.06674103 | -0.08373561 | -0.0807445 | -0.1783251 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.09750765 | -0.0577271 | -0.04714045 | 1.1186858 | -0.1319252 | -0.1255637 | -0.04714045 | -0.06674103 | -0.08175178 | -0.06674103 | -0.06674103 | -0.1215546 | -0.1357185 | -0.04714045 | -0.06416229 | -0.04714045 | -0.06447796 | -0.08183212 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.09459746 | -0.1023163 | -0.11911 | -0.04714045 | -0.04714045 | -0.06377736 | -0.08183212 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06659255 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1030436 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06132345 | -0.04714045 | -0.104031 | -0.04714045 | -0.1424384 | -0.08175178 | -0.04714045 | -0.1643958 | -0.04714045 | -0.08457259 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1255637 | -0.0809096 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08112843 | -0.04714045 | -0.09107652 | -0.04714045 | -0.04714045 | -0.04714045 | -0.0932938 | -0.1255637 | -0.1141694 | -0.04714045 | -0.04714045 | -0.06576639 | -0.08183212 | -0.04714045 | -0.08112843 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06670618 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.1505881 | -0.1505881 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.06674103 | -0.04714045 | -0.06674103 | -0.04714045 | -0.08183212 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.06596154 | -0.04714045 | -0.06674103 | -0.1187755 | -0.04714045 | -0.04714045 | 10.54761690 | -0.08183212 | -0.08183212 | -0.04714045 | -0.06654357 | -0.04714045 | 8.9851421 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.05791563 | -0.04714045 | -0.05615139 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06502453 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.1069175 | -0.04714045 | -0.04714045 | -0.1153898 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07317727 | -0.04714045 | -0.06674103 | -0.09452013 | -0.04714045 | -0.04714045 | -0.1503501 | -0.04714045 | -0.08102054 | -0.04714045 | -0.04714045 | -0.1705609 | -0.04714045 | -0.04714045 | -0.04714045 | -0.0964032 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.1007641 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.06391453 | -0.08584293 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07908111 | -0.04714045 | -0.06657067 | -0.09459746 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07932692 | -0.06662535 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.07932692 | -0.08183212 | -0.1058516 | -0.06073559 | -0.06674103 | -0.04714045 | -0.06674103 | -0.08099862 | -0.06502453 | -0.04714045 | -0.06674103 | -0.1469904 | -0.04714045 | -0.04714045 | -0.08180999 | 4.1752821 | -0.05387103 | -0.04714045 | -0.04714045 | -0.1426983 | -0.07744647 | -0.06674103 | -0.1153898 | -0.04714045 | -0.04714045 | -0.06670121 | -0.04714045 | -0.06701863 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06437938 | 9.7062491 | -0.04714045 | -0.04714045 | -0.04714045 | -0.08180999 | -0.04714045 | -0.04714045 | -0.04714045 | -0.04714045 | -0.06330197 | -0.04714045 | -0.04714045 | -0.05504269 | -0.04714045 | -0.06674103 | -0.04714045 | -0.06674103 | -0.06674103 | -0.06674103 | -0.1058819 | -0.04714045 | -0.08167683 | -0.06659255 | -0.04714045 | -0.08039799 | -0.2180258 | -0.85809913 | -0.06674103 | -0.04714045 | -0.1203103 | -0.06674103 | -0.04714045 | -0.04714045 | -0.08085704 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.09380314 | -0.04714045 | -0.07906384 | -0.08183212 | -0.08183212 | -0.1077152 | -0.04714045 | -0.04714045 | -0.04714045 | -0.3635161 | -0.04714045 | -0.04714045 | -0.09459746 | -0.04714045 | -0.04714045 | -0.06674103 | -0.04714045 | -0.04714045 | -0.06674103 | -0.06132345 | -0.06674103 | -0.06674103 | -0.1270799 | -0.09310869 | -0.06674103 | -0.1036071 | -0.06674103 | -0.112243 | -0.06425878 | 10.54761690 | -0.11587 | -0.06073559 | -0.06674103 | -0.09429395 | -0.06491832 | -0.06674103 | -0.1255637 | -0.06502453 | -0.06885996 | 8.9292060 | -0.06674103 | -0.06588576 | -0.06654357 | -0.06525315 | -0.1051144 | -0.06674103 | -0.1156589 | -0.06387334 | -0.06633102 | -0.06640834 | -0.1171896 | -0.07966228 | -0.0936996 | -0.06674103 | -0.1409088 | -0.06473981 | -0.08487739 | -0.1008278 | -0.1418956 | -0.06674103 | -0.1055584 | -0.1661186 | -0.08116132 | -0.09459746 | -0.08183212 | -0.06674103 | -0.08183212 | 4.7022924 | -0.2049717 | -0.1255637 | -0.1792152 | -0.05233905 | -0.09180441 |
Доработаем наш рецепт.
books_rec <- recipe(price ~ year + genre + name + reviews + rating,
data = books_train) |>
step_mutate(name = str_replace_all(name, "\\d+([\\.,]\\d+)?", "0")) |>
step_dummy(genre) |>
step_tokenize(name) |>
step_tokenfilter(name, max_tokens = 1000) |>
step_tfidf(name) |>
step_normalize(all_predictors())Добавляем препроцессор в воркфлоу.
svm_wflow <- svm_wflow |>
add_recipe(books_rec) # update_recipe(), если надо заменить
svm_wflow══ Workflow ════════════════════════════════════════════════════════════════════
Preprocessor: Recipe
Model: svm_linear()
── Preprocessor ────────────────────────────────────────────────────────────────
6 Recipe Steps
• step_mutate()
• step_dummy()
• step_tokenize()
• step_tokenfilter()
• step_tfidf()
• step_normalize()
── Model ───────────────────────────────────────────────────────────────────────
Linear Support Vector Machine Model Specification (regression)
Computational engine: LiblineaR 24.9 Подгонка модели
Подгоним модель на обучающих данных.
svm_fit <- svm_wflow |>
fit(data = books_train)Пакет {broom} позволяет тайдифицировать модель. Посмотрим на переменные, которые приводят к “удорожанию” книг. Видно, что в начале списка – слова, связанные с научными публикациями, что не лишено смысла.
svm_fit |>
tidy() |>
arrange(-estimate) |>
head(6) |>
gt::gt()| term | estimate |
|---|---|
| Bias | 13.227513 |
| tfidf_name_collection | 3.460221 |
| tfidf_name_alchemist | 1.448187 |
| tfidf_name_edition | 1.347852 |
| tfidf_name_watchmen | 1.269329 |
| tfidf_name_dragons | 1.021878 |
Оценим модель на контрольных данных. Для оценки используем корень из среднеквадратичной ошибки, коэффициент детерминации и среднюю абсолютную ошибку.
24.10 Контрольные данные
pred_data <- tibble(truth = books_test$price,
estimate = predict(svm_fit, books_test)$.pred)
books_metrics <- metric_set(rmse, rsq, mae)
books_metrics(pred_data, truth = truth, estimate = estimate) |>
gt::gt()| .metric | .estimator | .estimate |
|---|---|---|
| rmse | standard | 9.87292855 |
| rsq | standard | 0.07380427 |
| mae | standard | 4.95101282 |
Можно заметить, что \(R^2\) лишь немного отличается от простой линейной модели. При использовании линейного ядра в методе опорных векторов (svm_linear()) итоговые метрики качества часто оказываются сопоставимы с результатами классической линейной регрессии. Это объясняется тем, что оба алгоритма нацелены на поиск линейных закономерностей в пространстве признаков.
На заметку
Средняя абсолютная ошибка (MAE) представляет собой среднее арифметическое модулей разностей между предсказанными и фактическими значениями целевой переменной. В отличие от среднеквадратичной ошибки (MSE), MAE измеряется в тех же единицах, что и сами данные, что делает её интуитивно понятной для интерпретации: она показывает, на сколько единиц в среднем ошибается модель. Важной особенностью этой метрики является её устойчивость к выбросам, поскольку при расчёте все ошибки учитываются линейно, а не возводятся в квадрат.
24.11 Нелинейная SVR
Нелинейные модели опорных векторов (SVR) используют специальный математический прием, называемый «ядерным переходом» (kernel trick), для проецирования исходных данных в пространство более высокой размерности. В этом новом пространстве алгоритм строит линейную гиперплоскость, которая при обратном проецировании в исходные координаты превращается в сложную нелинейную кривую или поверхность.
Наиболее популярное радиально-базисное ядро (RBF) позволяет модели учитывать локальные особенности данных: оно придает больший вес точкам, находящимся вблизи предсказываемого значения, и плавно снижает влияние удаленных наблюдений. Простыми словами: при оценке стоимости конкретной книги из контрольных данных модель в первую очередь смотрит на её ближайших соседей из тренировочного набора. Те книги, которые максимально похожи на оцениваемую (по году, жанру или словам в названии), имеют решающий “вес”, в то время как непохожие издания почти не учитываются. Таким образом, модель не просто выводит общую формулу для всего набора, а ищет уникальные локальные закономерности для каждого наблюдения.
Другое решение - полиномиальное ядро, когда пространство предикторов расширяется за счет полиномов 2-й, 3-й и т.д. степеней. Такие модели, однако, легко переобучить: они идеально описывают случайные совпадения в тренировочном наборе, но пасуют перед новыми данными.
Сначала ставим пакет {kernlab}, так как он является основным движком для RBF-ядра в R.
# Определение нелинейной модели SVR с RBF-ядром
svm_rbf_spec <- svm_rbf(
cost = 1, # Штраф за ошибки (можно подбирать через tune())
rbf_sigma = 0.01 # Параметр "ширины" влияния каждой точки (gamma)
) |>
set_engine("kernlab") |>
set_mode("regression")
# Создание нового workflow
svm_rbf_wflow <- workflow() |>
add_recipe(books_rec) |>
add_model(svm_rbf_spec)
# Обучение
svm_rbf_fit <- fit(svm_rbf_wflow, data = books_train)
# Оценка
pred_data <- tibble(truth = books_test$price,
estimate = predict(svm_rbf_fit, books_test)$.pred)
books_metrics <- metric_set(rmse, rsq, mae)
books_metrics(pred_data, truth = truth, estimate = estimate) |>
gt::gt()| .metric | .estimator | .estimate |
|---|---|---|
| rmse | standard | 6.6614073 |
| rsq | standard | 0.2009881 |
| mae | standard | 3.7919709 |
24.12 Повторные выборки
Чтобы не распечатывать каждый раз тестовые данные (в идеале мы их используем один, максимум два раза!), задействуется ряд методов, позволяющих оценить ошибку путем исключения части обучающих наблюдений из процесса подгонки модели и последующего применения этой модели к исключенным наблюдениям.

В пакете {rsample} из библиотеки {tidymodels} реализованы, среди прочего, следующие методы повторных выборок для оценки производительности моделей машинного обучения:
Метод проверочной выборки – набор наблюдений делится на обучающую и проверочную, или удержанную, выборку (validation set): для этого используется
initial_validation_split().K-кратная перекрестная проверка – наблюдения разбиваются на k групп примерно одинакового размера, первый блок служит в качестве проверочной выборки, а модель подгоняется по остальным k-1 блокам; процедура повторяется k раз: функция
vfold_cv().Перекрестная проверка Монте-Карло – в отличие от предыдущего метода, создается множество случайных разбиений данных на обучающую и тестовую выборки: функция
mc_cv().Бутстреп – отбор наблюдений выполняется с возвращением, т.е. одно и то же наблюдение может встречаться несколько раз: функция
bootstraps().Перекрестная проверка по отдельным наблюдениям (leave-one-out сross-validation): одно наблюдение используется в качестве контрольного, а остальные составляют обучающую выборку; модель подгоняется по n-1 наблюдениям, что повторяется n раз: функция
loo_cv().
Эти методы повторных выборок позволяют получить надежные оценки производительности моделей машинного обучения, избегая переобучения и обеспечивая репрезентативность тестовых выборок.
set.seed(05102024)
books_folds <- vfold_cv(books_train, v = 10)
svm_rbf_rs <- fit_resamples(
svm_rbf_wflow,
books_folds,
control = control_resamples(save_pred = TRUE)
)В vfold_cv() модель обучается и тестируется 10 раз на разных частях данных. Итоговый — это среднее арифметическое результатов всех 10 попыток. Среднее значение обычно выглядит “оптимистичнее” и стабильнее, так как оно сглаживает случайные провалы:
collect_metrics(svm_rbf_rs) |>
gt::gt()| .metric | .estimator | mean | n | std_err | .config |
|---|---|---|---|---|---|
| rmse | standard | 7.5597222 | 10 | 1.5046226 | Preprocessor1_Model1 |
| rsq | standard | 0.5224215 | 10 | 0.0670075 | Preprocessor1_Model1 |
svm_rbf_rs |>
collect_predictions() |>
ggplot(aes(price, .pred, color = id)) +
geom_jitter(alpha = 0.3) +
geom_abline(lty = 2, color = "grey80") +
theme_minimal() +
coord_cartesian(xlim = c(0,50), ylim = c(0,50))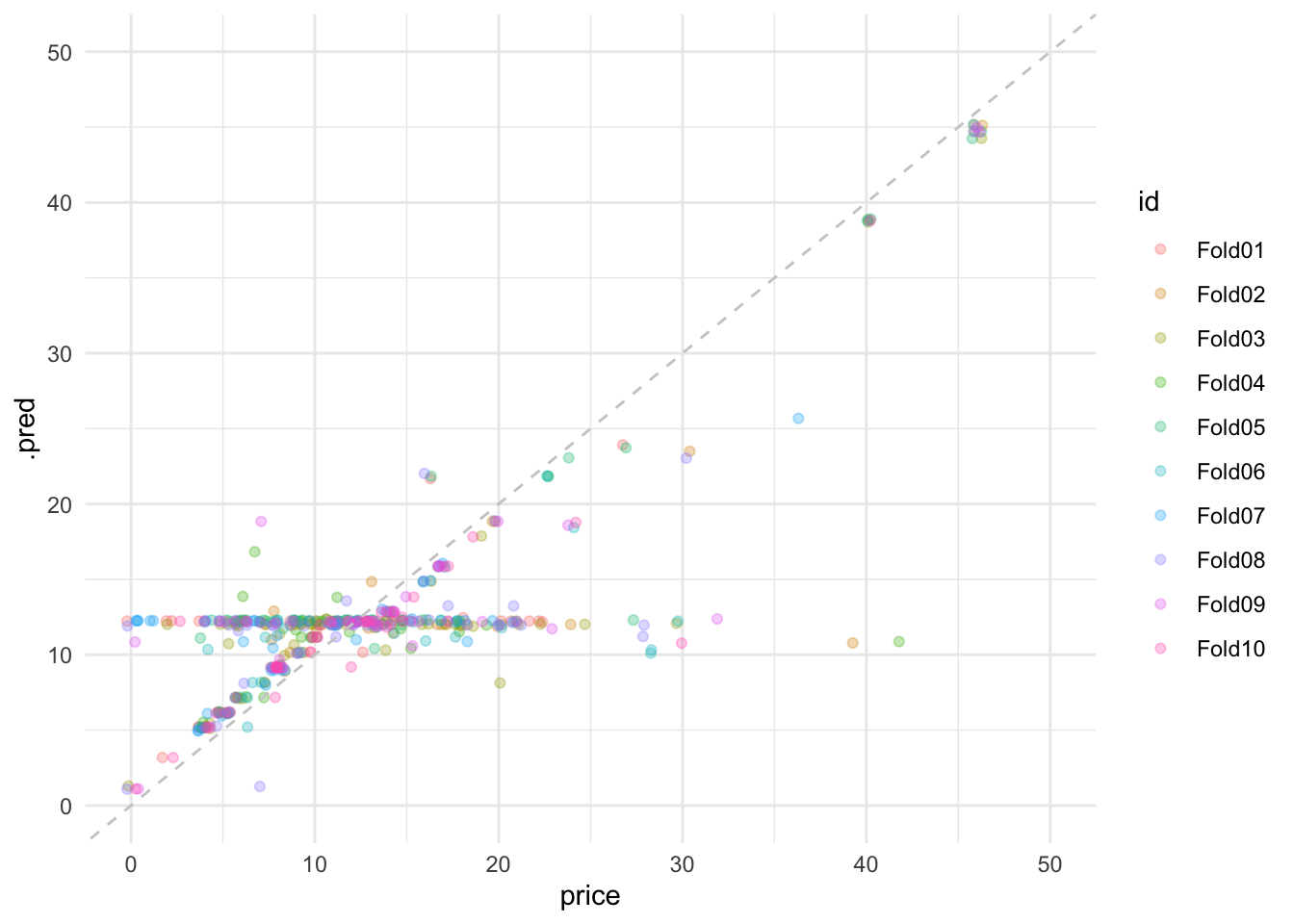
Что значит крест: для огромного количества книг модель просто выдает среднее значение цены (или близкое к нему). Когда SVR (или любая другая модель) не находит в признаках (словах, рейтинге) четкого сигнала для конкретной книги, она «минимизирует риски» и предсказывает среднее по выборке. Это плохо.
24.13 Нулевая модель
Кстати, проверим, какой результат даст нулевая модель.
null_reg <- null_model() |>
set_engine("parsnip") |>
set_mode("regression")
null_wflow <- workflow() |>
add_model(null_reg) |>
add_recipe(books_rec)
null_rs <- fit_resamples(
null_wflow,
books_folds,
control = control_resamples(save_pred = TRUE)
)
collect_metrics(null_rs) |>
gt::gt()| .metric | .estimator | mean | n | std_err | .config |
|---|---|---|---|---|---|
| rmse | standard | 10.65831 | 10 | 1.281173 | Preprocessor1_Model1 |
| rsq | standard | NaN | 0 | NA | Preprocessor1_Model1 |
\(R^2\) в таком случае должен быть NaN.
24.14 Удаление стопслов
Изменим рецепт приготовления данных.
stopwords_rec <- function(stopwords_name) {
recipe(price ~ year + genre + name + reviews + rating,
data = books_train) |>
step_mutate(name = str_replace_all(name, "\\d+([\\.,]\\d+)?", "0")) |>
step_dummy(genre) |>
step_tokenize(name) |>
step_stopwords(name, stopword_source = stopwords_name) |>
step_tokenfilter(name, max_tokens = 1000) |>
step_tfidf(name) |>
step_normalize(all_predictors())
}Создадим новый воркфлоу.
svm_rbf_wflow <- workflow() |>
add_model(svm_rbf_spec)И снова проведем перекрестную проверку, на этот раз с разными списками стоп-слов.
set.seed(123)
snowball_rs <- fit_resamples(
svm_rbf_wflow |>
add_recipe(stopwords_rec("snowball")),
books_folds
)
set.seed(234)
smart_rs <- fit_resamples(
svm_rbf_wflow |>
add_recipe(stopwords_rec("smart")),
books_folds
)
set.seed(345)
stopwords_iso_rs <- fit_resamples(
svm_rbf_wflow |>
add_recipe(stopwords_rec("stopwords-iso")),
books_folds
)collect_metrics(smart_rs) |>
gt::gt()| .metric | .estimator | mean | n | std_err | .config |
|---|---|---|---|---|---|
| rmse | standard | 7.7466013 | 10 | 1.48713642 | Preprocessor1_Model1 |
| rsq | standard | 0.4913497 | 10 | 0.07223065 | Preprocessor1_Model1 |
collect_metrics(snowball_rs) |>
gt::gt()| .metric | .estimator | mean | n | std_err | .config |
|---|---|---|---|---|---|
| rmse | standard | 7.651848 | 10 | 1.51263320 | Preprocessor1_Model1 |
| rsq | standard | 0.507731 | 10 | 0.06971969 | Preprocessor1_Model1 |
collect_metrics((stopwords_iso_rs)) |>
gt::gt()| .metric | .estimator | mean | n | std_err | .config |
|---|---|---|---|---|---|
| rmse | standard | 7.6764663 | 10 | 1.48085099 | Preprocessor1_Model1 |
| rsq | standard | 0.5005151 | 10 | 0.07010337 | Preprocessor1_Model1 |
В нашем случае удаление стоп-слов заметного положительного эффекта не имело.
word_counts <- tibble(name = c("snowball", "smart", "stopwords-iso")) %>%
mutate(words = map_int(name, ~length(stopwords::stopwords(source = .))))
list(snowball = snowball_rs,
smart = smart_rs,
`stopwords-iso` = stopwords_iso_rs) |>
map_dfr(show_best, metric = "rmse", .id = "name") |>
left_join(word_counts, by = "name") |>
mutate(name = paste0(name, " (", words, " words)"),
name = fct_reorder(name, words)) |>
ggplot(aes(name, mean, color = name)) +
geom_crossbar(aes(ymin = mean - std_err, ymax = mean + std_err), alpha = 0.6) +
geom_point(size = 3, alpha = 0.8) +
theme(legend.position = "none") +
theme_minimal()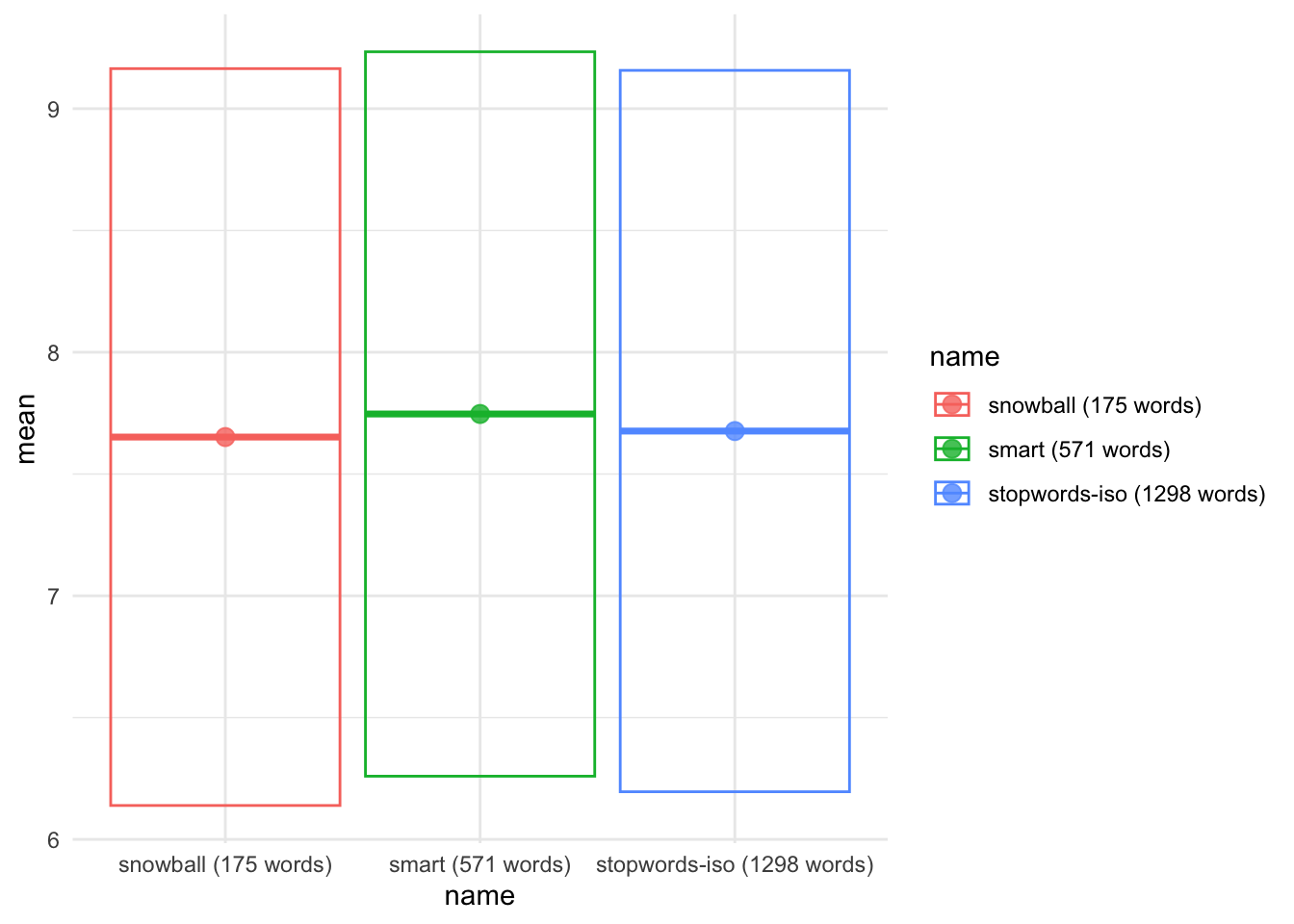
24.15 Настройки числа n-grams
ngram_rec <- function(ngram_options) {
recipe(price ~ year + genre + name + reviews + rating, data = books_train) |>
step_mutate(name = str_replace_all(name, "\\d+([\\.,]\\d+)?", "0")) |>
step_dummy(genre) |>
step_tokenize(name, token = "ngrams", options = ngram_options) |>
step_tokenfilter(name, max_tokens = 1000) |>
step_tfidf(name) |>
step_normalize(all_predictors())
}fit_ngram <- function(ngram_options) {
fit_resamples(
svm_rbf_wflow |>
add_recipe(ngram_rec(ngram_options)),
books_folds
)
}set.seed(123)
unigram_rs <- fit_ngram(list(n = 1))
set.seed(234)
bigram_rs <- fit_ngram(list(n = 2, n_min = 1))
set.seed(345)
trigram_rs <- fit_ngram(list(n = 3, n_min = 1))collect_metrics(unigram_rs) |>
gt::gt()| .metric | .estimator | mean | n | std_err | .config |
|---|---|---|---|---|---|
| rmse | standard | 7.5597222 | 10 | 1.5046226 | Preprocessor1_Model1 |
| rsq | standard | 0.5224215 | 10 | 0.0670075 | Preprocessor1_Model1 |
collect_metrics(bigram_rs) |>
gt::gt()| .metric | .estimator | mean | n | std_err | .config |
|---|---|---|---|---|---|
| rmse | standard | 7.5147223 | 10 | 1.61280063 | Preprocessor1_Model1 |
| rsq | standard | 0.5181945 | 10 | 0.08163889 | Preprocessor1_Model1 |
collect_metrics(trigram_rs) |>
gt::gt()| .metric | .estimator | mean | n | std_err | .config |
|---|---|---|---|---|---|
| rmse | standard | 7.5709675 | 10 | 1.61781943 | Preprocessor1_Model1 |
| rsq | standard | 0.5113992 | 10 | 0.08112386 | Preprocessor1_Model1 |
Визуализируем результат:
list(`1` = unigram_rs,
`1 and 2` = bigram_rs,
`1, 2, and 3` = trigram_rs) |>
map_dfr(collect_metrics, .id = "name") |>
filter(.metric == "rmse") |>
ggplot(aes(name, mean, color = name)) +
geom_crossbar(aes(ymin = mean - std_err, ymax = mean + std_err),
alpha = 0.6) +
geom_point(size = 3, alpha = 0.8) +
theme(legend.position = "none") +
labs(
y = "RMSE"
) +
theme_minimal()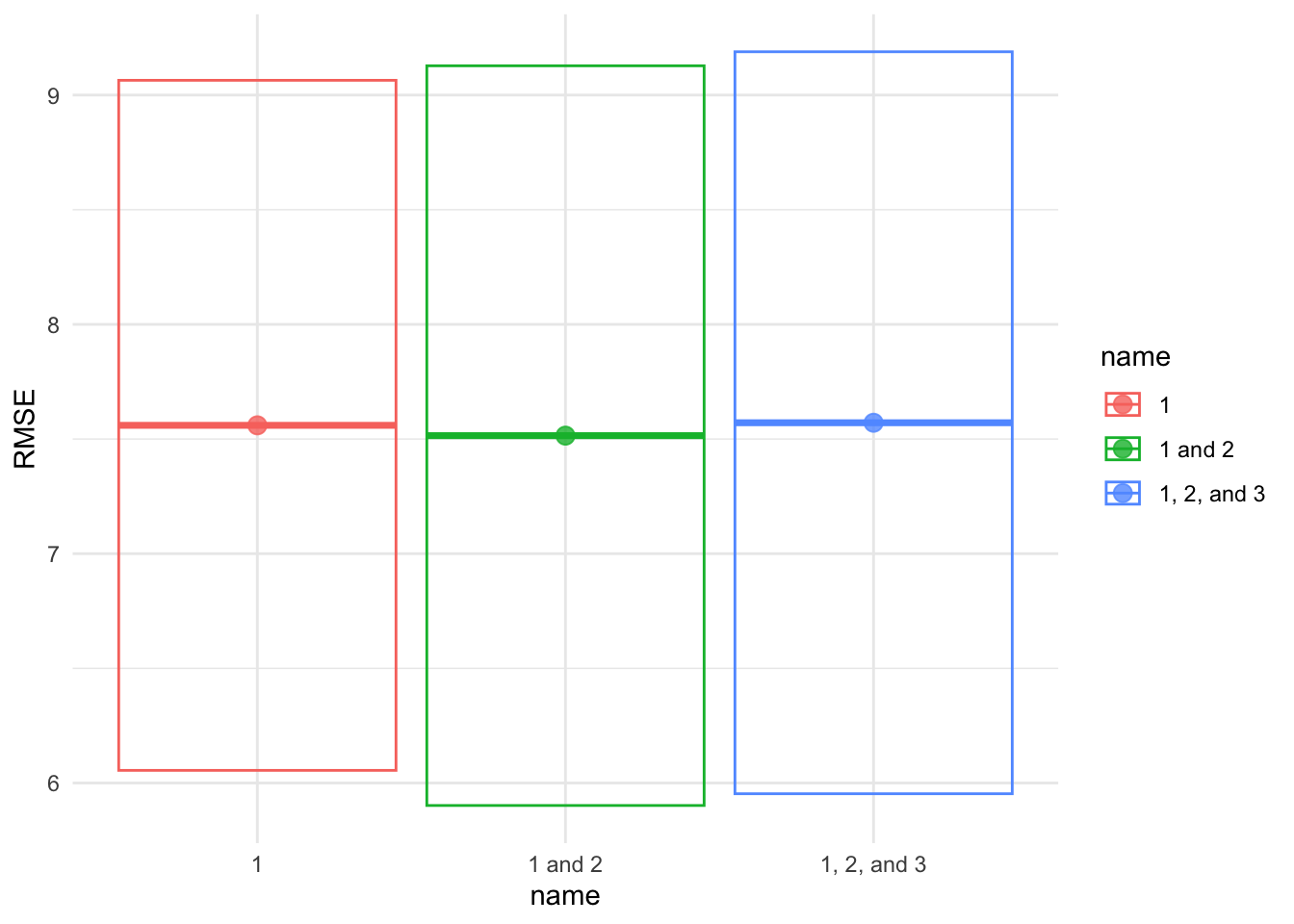
24.16 Финализация и оценка
# books_split — это объект, который вы получили в самом начале через initial_split()
final_res <- last_fit(svm_rbf_wflow |>
add_recipe(books_rec),
books_split)# 1. Посмотреть метрики на контрольных данных (RMSE, RSQ)
collect_metrics(final_res) |>
gt::gt()| .metric | .estimator | .estimate | .config |
|---|---|---|---|
| rmse | standard | 6.6614073 | Preprocessor1_Model1 |
| rsq | standard | 0.2009881 | Preprocessor1_Model1 |
# 2. Посмотреть предсказания для тестовой выборки
final_preds <- collect_predictions(final_res)
# 3. Визуализировать результат (тот самый график Predicted vs Actual)
final_preds |>
ggplot(aes(price, .pred)) +
geom_point(alpha = 0.4, color = "midnightblue") +
geom_abline(lty = 2, color = "gray") +
theme_minimal() +
labs(title = "Результат на контрольных данных")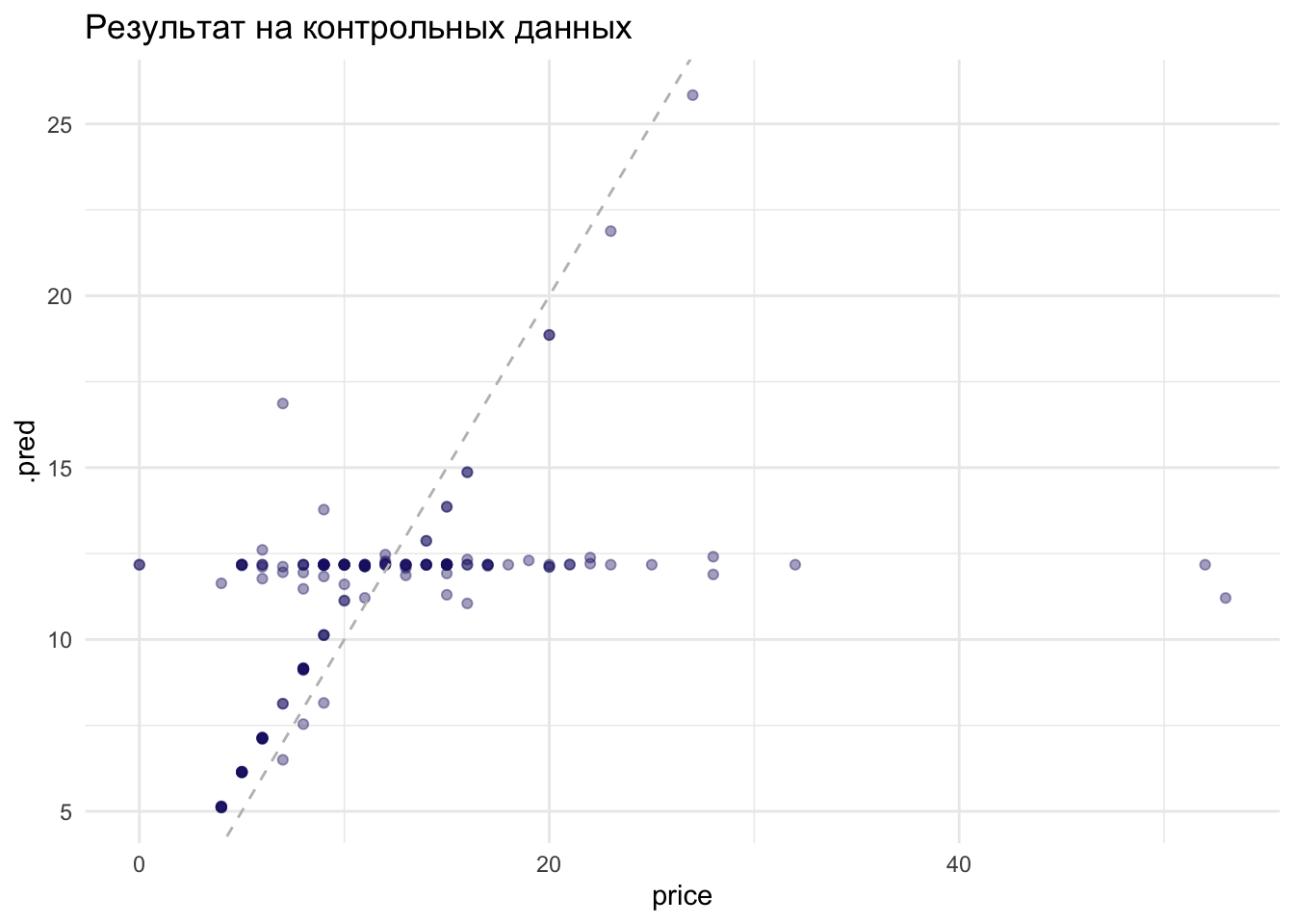
Также посмотрим, какие предикторы больше всего влияют на цену. Проще всего это сделать через линейную аппроксимацию.
lm_fit <- workflow() |>
add_recipe(books_rec) |>
add_model(svm_spec) |>
fit(data = training(books_split))lm_fit |>
tidy() |>
filter(term != "year") |>
filter(term != "Bias") |>
filter(!str_detect(term, "genre")) |>
mutate(sign = case_when(estimate > 0 ~ "дороже",
.default = "дешевле"),
estimate = abs(estimate),
term = str_remove_all(term, "tfidf_name_")) |>
group_by(sign) |>
top_n(20, estimate) |>
ungroup() |>
ggplot(aes(x = estimate, y = fct_reorder(term, estimate),
fill = sign)) +
geom_col(show.legend = FALSE) +
scale_x_continuous(expand = c(0,0)) +
facet_wrap(~sign, scales = "free") +
labs(y = NULL,
title = "Связь слов с ценой книг") +
theme_minimal()
24.17 Видео
Г. Джеймс, Д. Уиттон, Т. Хасти, Р. Тибришани. 2017. Введение в статистическое обучение с примерами на языке R. ДМК.