# install.packages("gutenbergr")
library(gutenbergr)
library(tidyverse)
library(stringr)
gutenberg_works(str_detect(author, "Hume"), languages = "en")11 Распределения слов и анализ частотностей
В этом уроке мы научимся считать наиболее частотные и наиболее характерные слова, удалять стоп-слова, познакомимся с алгоритмом стемминга, а также узнаем, как считать type-token ratio (и почему этого делать не стоит).
11.1 Подготовка данных
За основу для всех эти вычислений мы возьмем три философских трактата, написанных на английском языке. Это хронологически и тематически близкие тексты:
- “Опыт о человеческом разумении” Джона Локка (1690), первые две книги;
- “Трактат о принципах человеческого знания” Джорджа Беркли (1710);
- “Исследование о человеческом разумении” Дэвида Юма (1748).
Источники для этого урока доступны в библиотеке Gutengerg; чтобы их извлечь, следует выяснить gutenberg_id. Пример ниже; таким же образом можно найти id для трактатов Локка и Беркли.
Когда id найдены, gutenbergr позволяет загрузить сочинения; на этом этапе часто возникают ошибки – в таком случае надо воспользоваться одним из зеркал. Список зеркал доступен по ссылке: https://www.gutenberg.org/MIRRORS.ALL.
my_corpus <- gutenberg_download(meta_fields = c("author", "title"), c(9662, 4723, 10615), mirror = "https://www.gutenberg.org/dirs/")
my_corpusВ этом тиббле хранятся все три текста, которые нам нужны. Уточнить уникальные называния можно при помощи функции distinct() из tidyverse.
my_corpus |>
distinct(author)Прежде чем приступать к анализу, придется немного прибраться. Для этого используем инструменты tidyverse, о которых шла речь в главе про опрятные данные.
my_corpus <- my_corpus |>
select(-gutenberg_id) |>
select(-title) |>
relocate(text, .after = author) |>
mutate(author = str_remove(author, ",.+$")) |>
filter(text != "")
my_corpusВ случае с Юмом отрезаем предисловия, оглавление и индексы, а также номера разделов (везде прописными). Многие слова, которые в оригинале были выделены курсивом, окружены знаками подчеркивания (_), их тоже удаляем.
Hume <- my_corpus |>
filter(author == "Hume")|>
filter(!row_number() %in% c(1:25),
!row_number() %in% c(4814:nrow(my_corpus))) |>
mutate(text = str_replace_all(text, "[[:digit:]]", " ")) |>
mutate(text = str_replace_all(text, "_", " ")) |>
filter(!str_detect(text, "SECTION .{1,4}"))В случае с Беркли отрезаем метаданные и посвящение в самом начале, а также удаляем нумерацию параграфов. Кроме того, текст содержит примечания следующего вида: Note: Vide Hobbes’ Tripos, ch. v. sect. 6., от них тоже следует избавиться.
Berkeley <- my_corpus |>
filter(author == "Berkeley") |>
filter(!row_number() %in% c(1:38)) |>
mutate(text = str_replace_all(text, "[[:digit:]]+?\\.", " ")) |>
mutate(text = str_replace_all(text, "\\[.+?\\]", " ")) |>
mutate(text = str_replace_all(text, "[[:digit:]]+", " "))Что касается Локка, то здесь удаляем метаданные и оглавление в самом начале, а также посвящение и подчеркивания вокруг слов. “Письмо к читателю” уже содержит некоторые философские положения, и его можно оставить.
Locke <- my_corpus |>
filter(author == "Locke") |>
filter(!row_number() %in% c(1:135)) |>
mutate(text = str_replace_all(text, "_", " ")) |>
mutate(text = str_replace_all(text, "[[:digit:]]", " "))Соединив обратно все три текста, замечаем некоторые орфографические нерегулярности; исправляем.
corpus_clean <- bind_rows(Hume, Berkeley, Locke) |>
mutate(text = str_replace_all(text, c("[Mm]an’s" = "man's", "[mM]en’s" = "men's", "[hH]ath" = "has")))
corpus_cleanСкачать подготовленный таким образом корпус можно здесь.
После этого делим корпус на слова.
library(tidytext)
corpus_words <- corpus_clean |>
unnest_tokens(word, text)
corpus_words11.2 Cтоп-слова
Большая часть слов, которые мы сейчас видим в корпусе, нам пока не интересна – это шумовые слова, или стоп-слова, не несущие смысловой нагрузки. Функция anti_join() позволяет от них избавиться; в случае с английским языком список стоп-слов уже доступен в пакете tidytext; в других случаях их следует загружать отдельно.
Для многих языков стоп-слова доступны в пакете stopwords. Пример удаления стопслов на русском языке можно посмотреть здесь.
Функция anti_join() работает так:
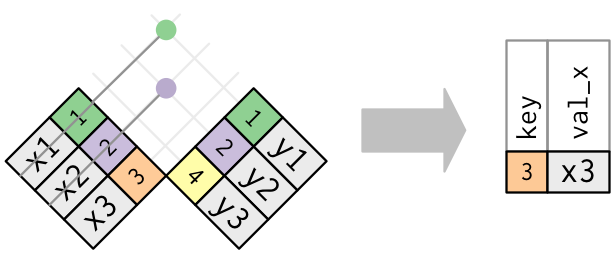
other <- c("section", "chapter", 0:40, "edit", 1710, "v.g", "v.g.a")
corpus_words_tidy <- corpus_words |>
anti_join(stop_words) |>
filter(!word %in% other)
corpus_words_tidyУборка закончена, мы готовы к подсчетам.
11.3 Абсолютная частотность
Для начала посмотрим на самые частотные слова во всем корпусе.
library(ggplot2)
corpus_words_tidy |>
count(word, sort = TRUE) |>
slice_head(n = 15) |>
ggplot(aes(reorder(word, n), n, fill = word)) +
geom_col(show.legend = F) +
coord_flip() 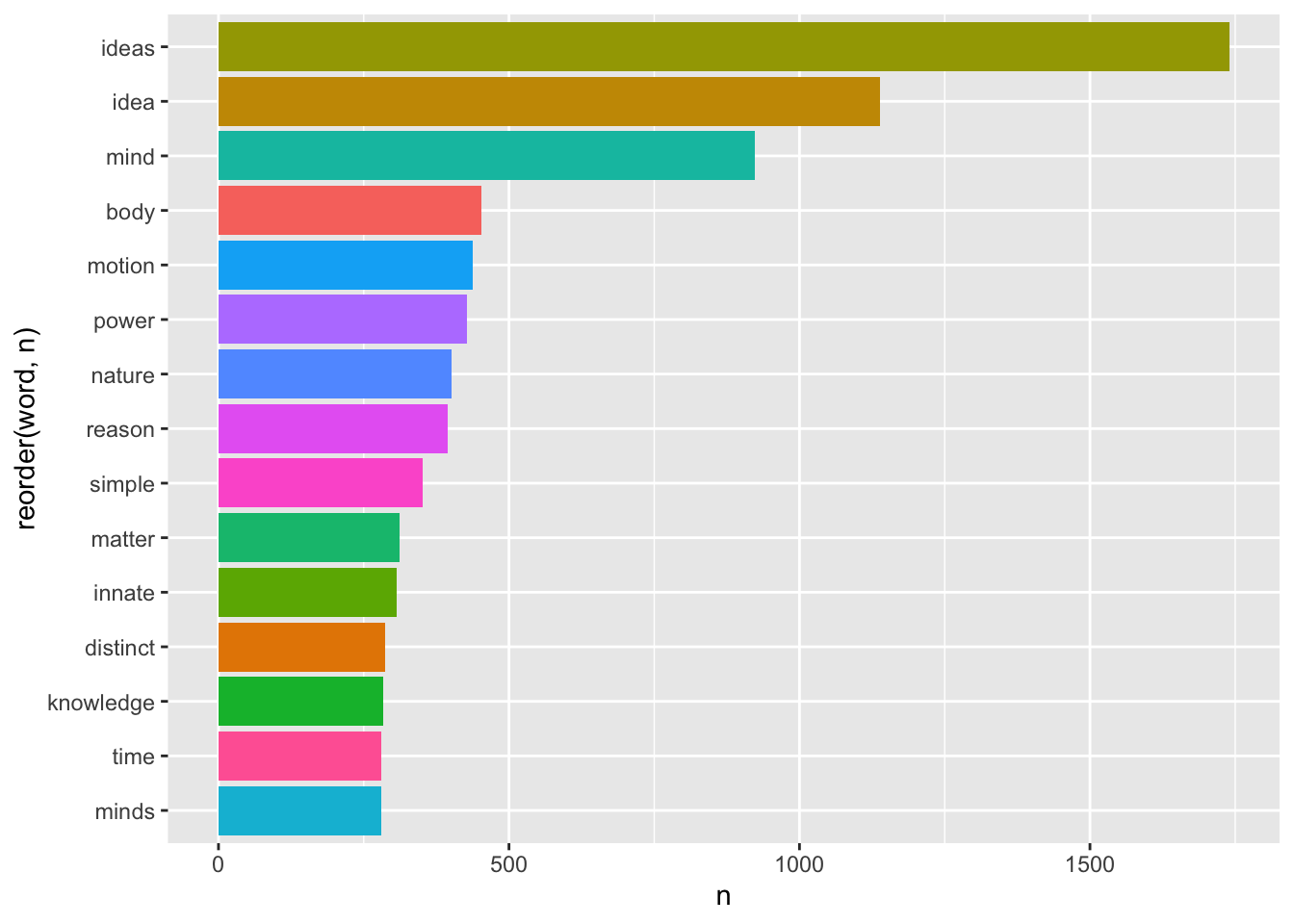
Этот график уже дает общее представление о тематике нашего корпуса: это теория познания, в центре которой для всех трех авторов стоит понятие “idea”.
Однако можно заподозрить, что высокие показатели для слов “simple”, “distinct” и “powers” – это заслуга прежде всего Локка, который вводит понятия “простой идеи” и “отчетливой идеи”, а также говорит о “силах” вещей, благодаря которым они воздействуют как друг на друга, так и на разум. Силы для Локка – это причины идей, и как таковые они часто упоминаются в его тексте. Понятие врожденности (“innate”) также занимает в первую очередь его: вся первая книга “Опыта” – это опровержение теории врожденных идей. Беркли о врожденности не говорит вообще, а Юм – очень кратко.
Кроме того, хотя мы взяли только две книги из “Опыта” Локка – это самый длинный текст в нашем корпусе, что создает значительный перекос:
corpus_words_tidy |>
group_by(author) |>
summarise(sum = n())Посмотрим статистику по отдельным авторам.
corpus_words_tidy |>
group_by(author) |>
count(word, sort = TRUE) |>
slice_head(n = 15) |>
ggplot(aes(reorder_within(word, n, author), n, fill = word)) +
geom_col(show.legend = F) +
facet_wrap(~author, scales = "free") +
scale_x_reordered() +
coord_flip() +
labs(x = NULL, y = NULL)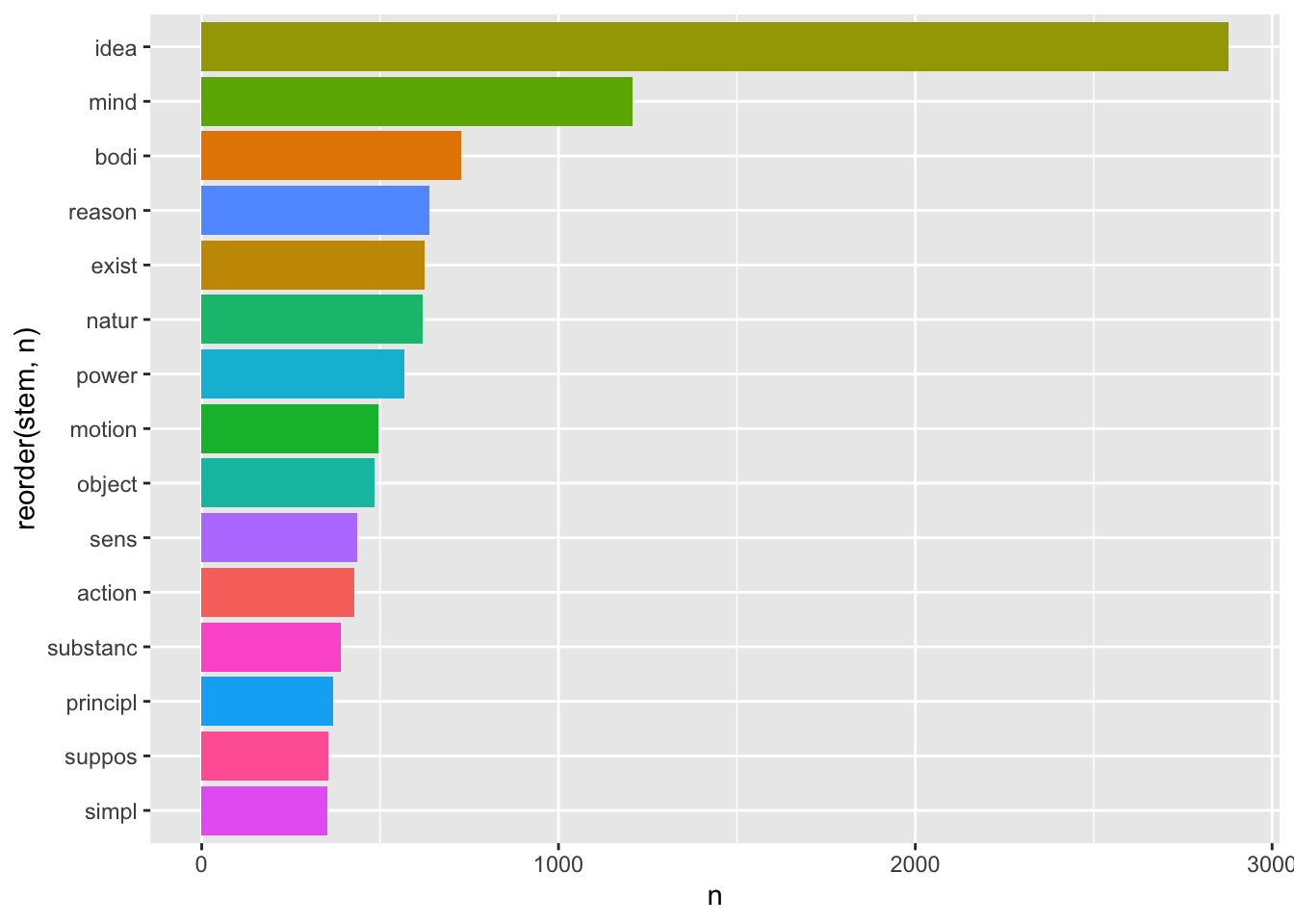
Наиболее частотные слова (при условии удаления стоп-слов) дают вполне адекватное представление о тематике каждого из трех трактатов.
Согласно Локку, объектом мышления является идея (желательно отчетливая, но тут уж как получится). Все идеи приобретены умом из опыта, направленного на либо на внешние предметы (ощущения, или чувства), либо на внутренние действия разума (рефлексия, или внутреннее чувство). Никаких врожденных идей у человека нет, изначально его душа похожа на чистый лист (антинативизм). Идеи могут быть простыми и сложными; они делятся на модусы, субстанции и отношения. К числу простых модусов относятся пространство, в котором находятся тела, а также продолжительность; измеренная продолжительность представляет собой время.
Беркли спорит с мнением, согласно котором ум способен образовывать абстрактные идеи. В том числе, утверждает он, невозможна абстрактная идея движения, отличная от движущегося тела. Он пытается устранить заблуждение Локка, согласно которому слова являются знаками абстрактных общих идей. В мыслящей душе (которую он также называет умом и духом) существуют не абстрактные идеи, а ощущения, и существование немыслящих вещей безотносительно к их воспринимаемости совершенно невозможно. Нет иной субстанции, кроме духа; немыслящие вещи ее совершенно лишены. По этой причине нельзя допустить, что существует невоспринимающая протяженная субстанция, то есть материя. Идеи ощущений возникают в нас согласно с некоторыми правилами, которые мы называем законами природы. Действительные вещи – это комбинации ощущений, запечатлеваемые в нас могущественным духом.
Согласно Юму, все объекты, доступные человеческому разуму, могут быть разделены на два вида, а именно: на отношения между идеями и факты. К суждениям об отношениях можно прийти благодаря одной только мыслительной деятельности, в то время как все заключения о фактах основаны на отношениях причины и действия. В свою очередь знание о причинности возникает всецело из опыта: только привычка заставляет нас ожидать наступления одного события при наступлении другого. Прояснение этого позволяет добиться большей ясности и точности в философии.
11.4 Стемминг
Поскольку мы не лемматизировали текст, то единственное и множественное число слова idea рассматриваются как разные токены. Один из способов справиться с этим - стемминг.
Стемминг (англ. stemming “поиск происхождения”) — это процесс нахождения основы слова для заданного исходного слова. Основа слова не обязательно совпадает с морфологическим корнем слова. Стемминг применяется в поисковых системах для расширения поискового запроса пользователя, является частью процесса нормализации текста. Один из наиболее популярных алгоритмов стемминга был написан Мартином Портером и опубликован в 1980 году.
В R стеммер Портера доступен в пакете snowball. К сожалению, он поддерживает не все языки, но русский, французский, немецкий и др. там есть. Не для всех языков, впрочем, и не для всех задач стемминг – это хорошая идея. Но попробуем применить его к нашему корпусу.
library(SnowballC)
corpus_stems <- corpus_words_tidy |>
mutate(stem = wordStem(word))
corpus_stems |>
count(stem, sort = TRUE) |>
slice_head(n = 15) |>
ggplot(aes(reorder(stem, n), n, fill = stem)) +
geom_col(show.legend = F) +
coord_flip() 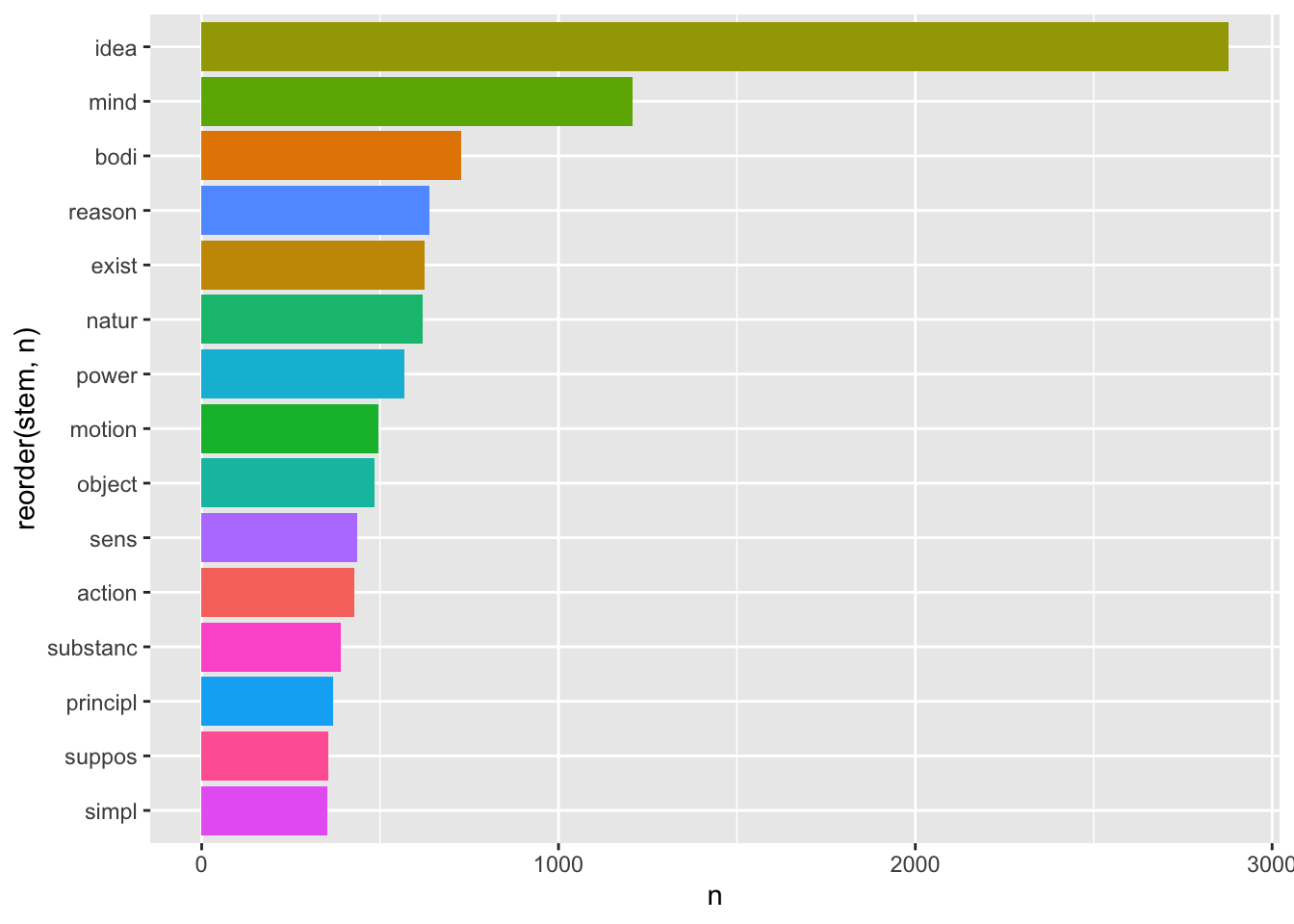
Все слова немного покромсаны, но вполне узнаваемы. При этом общее количество уникальных токенов стало значительно меньше:
# до стемминга
n_distinct(corpus_words_tidy$word)[1] 8132# после стемминга
n_distinct(corpus_stems$stem)[1] 5229Стемминг применяется в некоторых алгоритмах машинного обучения, но сегодня - все реже, потому что современные компьютеры прекрасно справляются с лемматизацией.
11.5 Относительная частотность
Абсолютная частотность – плохой показатель для текстов разной длины. Чтобы тексты было проще сравнивать, разделим показатели частотности на общее число токенов в тексте.
Cначала считаем частотность для всех токенов по авторам.
author_word_counts <- corpus_words |>
count(author, word, sort = T) |>
filter(!word %in% other) |>
ungroup()
author_word_countsЗатем - число токенов в каждой книге.
total_counts <- author_word_counts |>
group_by(author) |>
summarise(total = sum(n))
total_countsСоединяем два тиббла:
author_word_counts <- author_word_counts |>
left_join(total_counts)
author_word_countsСчитаем относительную частотность:
author_word_tf <- author_word_counts |>
mutate(tf = round((n / total), 5))
author_word_tfНаиболее частотные слова – это служебные части речи. На графике видно, что подавляющее большинство слов встречается очень редко, а слов с высокой частотностью - мало.
author_word_tf |>
ggplot(aes(tf, fill = author)) +
geom_histogram(show.legend = FALSE) +
facet_wrap(~author, scales = "free_y")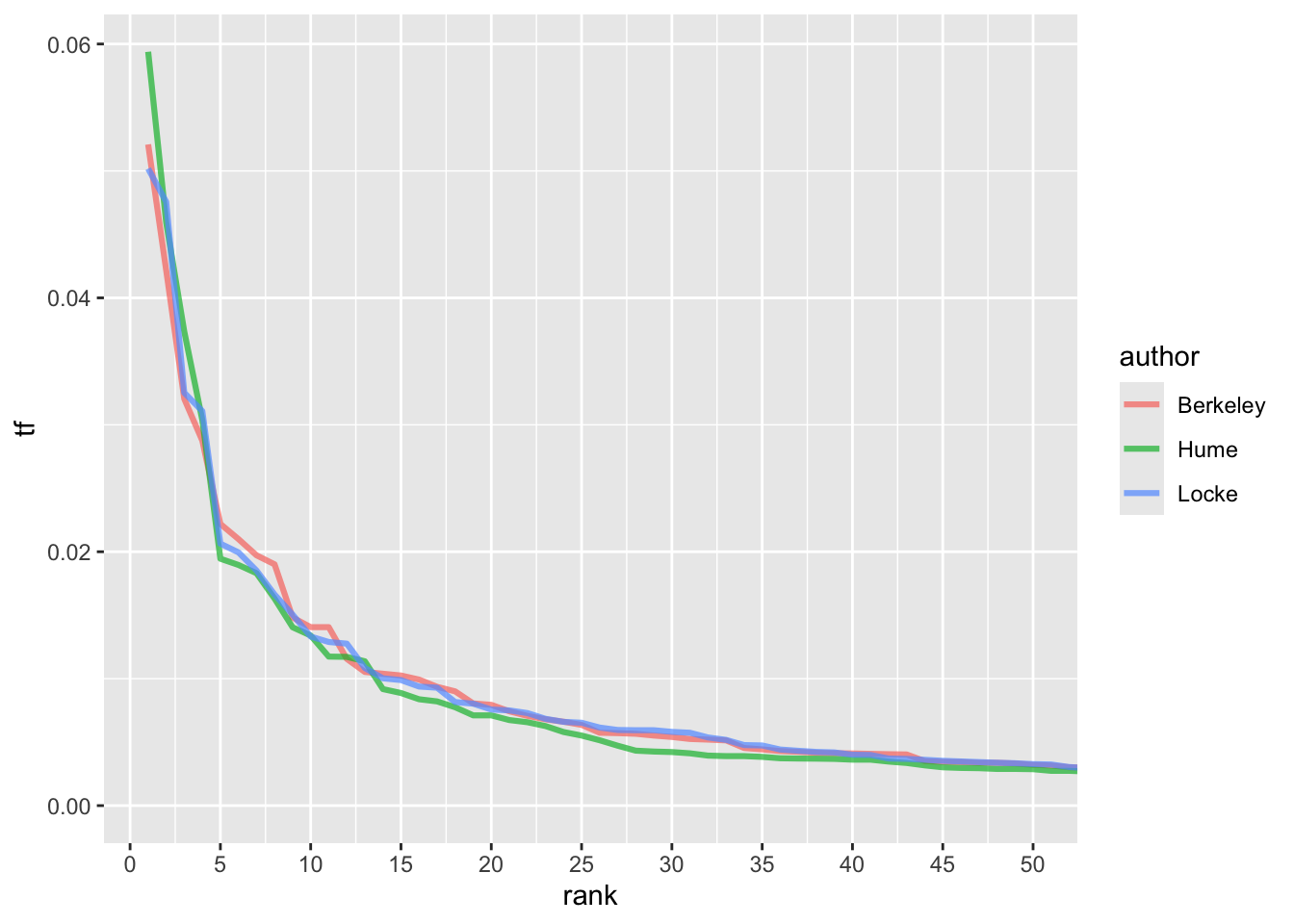
11.6 Закон Ципфа
Подобная картина характерна для естественных языков. Распределения слов в них подчиняются закону Ципфа. Этот закон носит имя американского лингвиста Джорджа Ципфа (George Zipf) и утверждает следующее: если все слова языка или длинного текста упорядочить по убыванию частоты использования, частота (tf) n-го слова в списке окажется обратно пропорциональной его рангу (r) в степени α. Это значит (в самом общем случае), что если ранг увеличится в n раз, то частотность во столько же раз должна упасть: второе слово в корпусе встречается примерно в два раза реже, чем первое (Savoy 2020, 24).
\[tf_{r_i} = \frac{c}{r^α_i}\]
Здесь c - это константа, которая оценивается для каждого случая отдельно, как и параметр α. Иначе говоря:
\[ tf_{r_i} \times r^α_i = c \] Посмотрим на ранги и частотность первых 50 слов.
author_word_tf_rank <- author_word_tf |>
group_by(author) |>
mutate(rank = row_number())
author_word_tf_rank |>
ggplot(aes(rank, tf, color = author)) +
geom_line(linewidth = 1.1, alpha = 0.7) +
coord_cartesian(xlim = c(NA, 50)) +
scale_x_continuous(breaks = seq(0,50,5))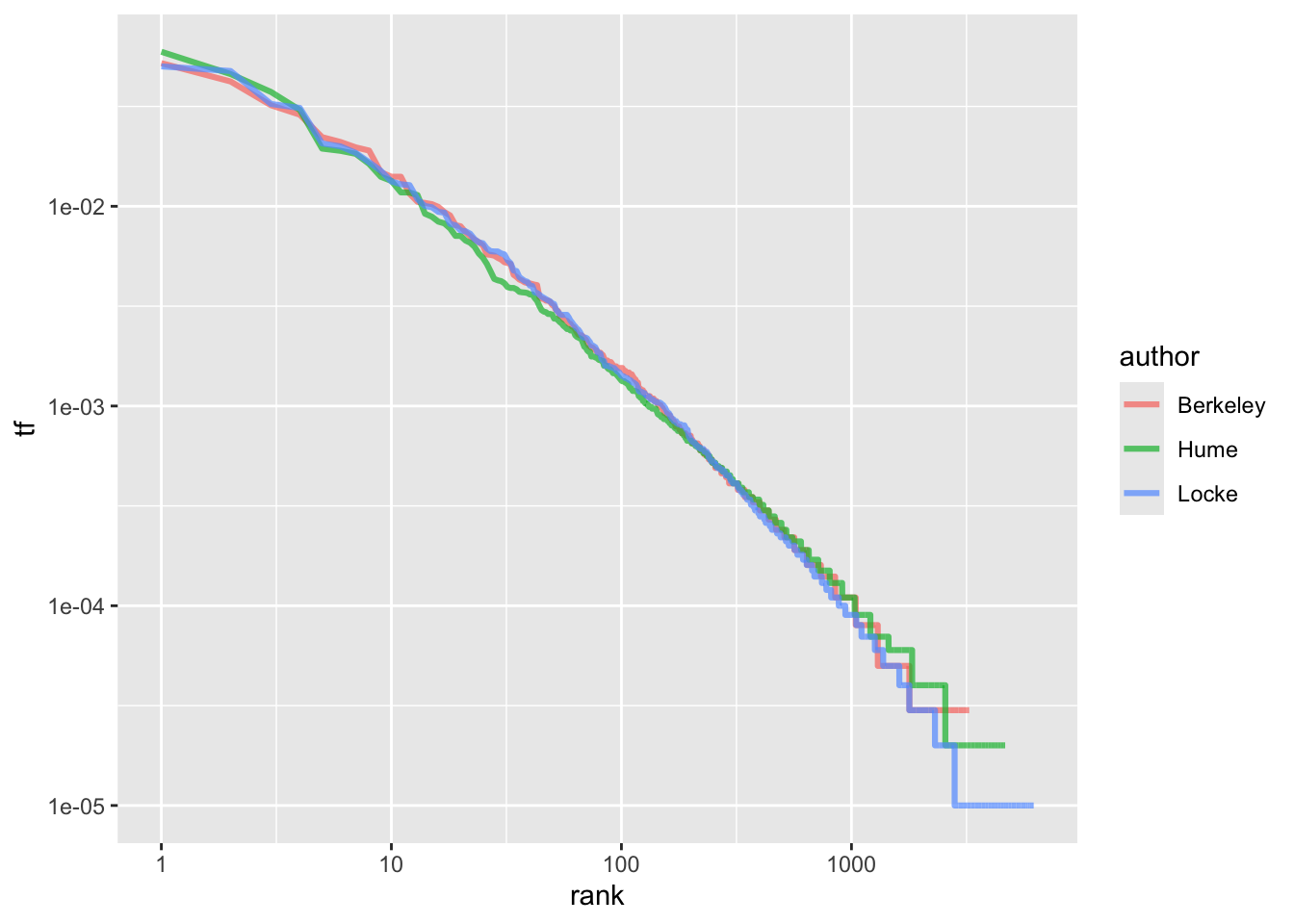
Вспомнив, что логарифм дроби равен разности логарифмов числителя и знаменателя, запишем:
\[log(tf_{r_i}) = c - α \times log(r_i) \] Таким образом, мы получаем близкую к линейность зависимость, где константа c определяет точку пересечения оси y, a коэффициентα - угол наклона прямой. Графически это выглядит так:
author_word_tf_rank |>
ggplot(aes(rank, tf, color = author)) +
geom_line(size = 1.1, alpha = 0.7) +
scale_x_log10() +
scale_y_log10()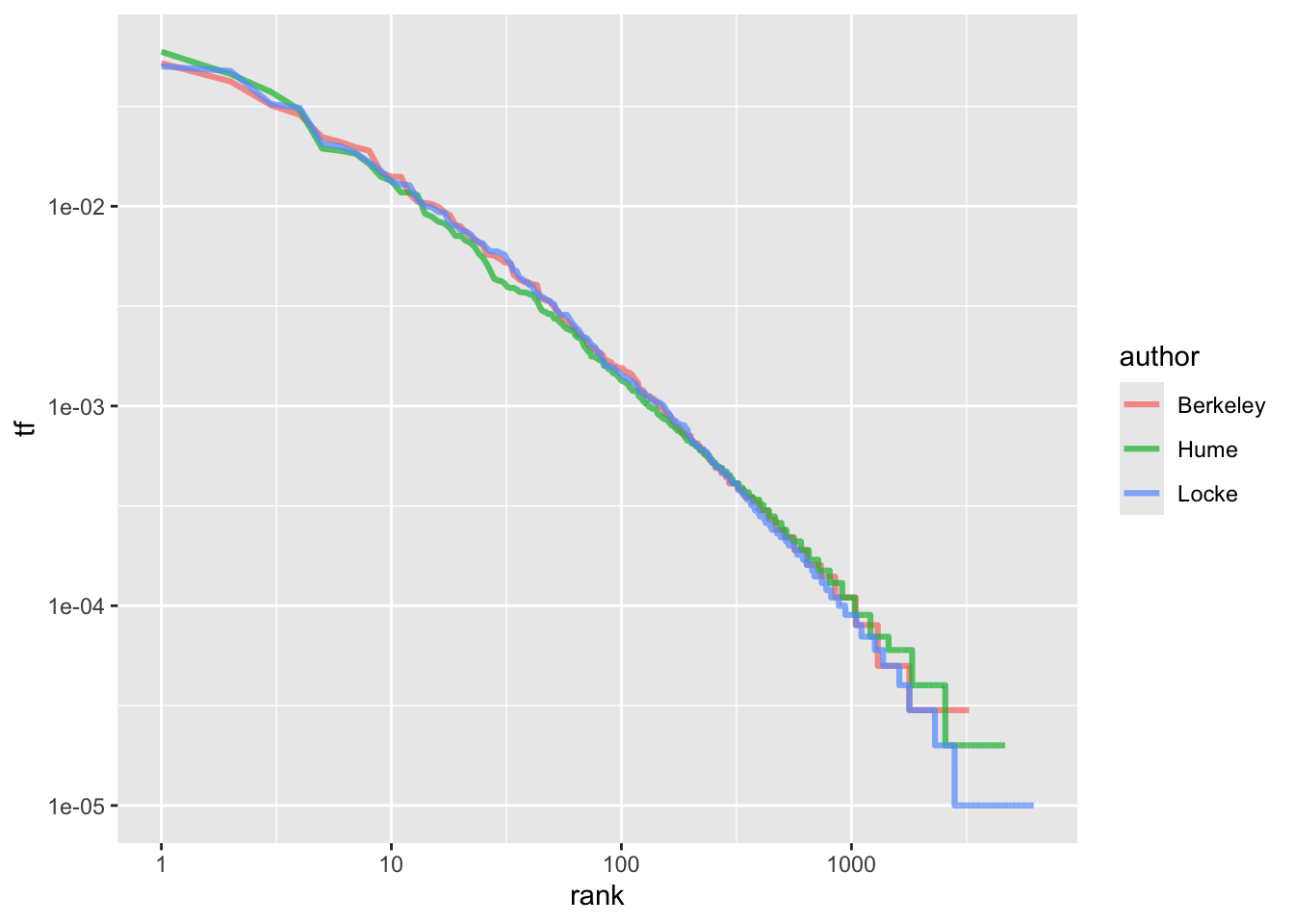
Чтобы узнать точные коэффициенты, придется подогнать линейную модель (об этом поговорим подробнее в следующих уроках):
lm_zipf <- lm(data = author_word_tf_rank,
formula = log10(tf) ~ log10(rank))
coefficients(lm_zipf)(Intercept) log10(rank)
-0.2501025 -1.2728170 Мы получили коэффициент наклона α чуть больше -1 (на практике точно -1 встречается редко). Добавим линию регрессии на график:
author_word_tf_rank |>
ggplot(aes(rank, tf, color = author)) +
geom_line(size = 1.1, alpha = 0.7) +
geom_abline(intercept = coefficients(lm_zipf)[1],
slope = coefficients(lm_zipf)[2],
linetype = 2,
color = "grey50") +
scale_x_log10() +
scale_y_log10()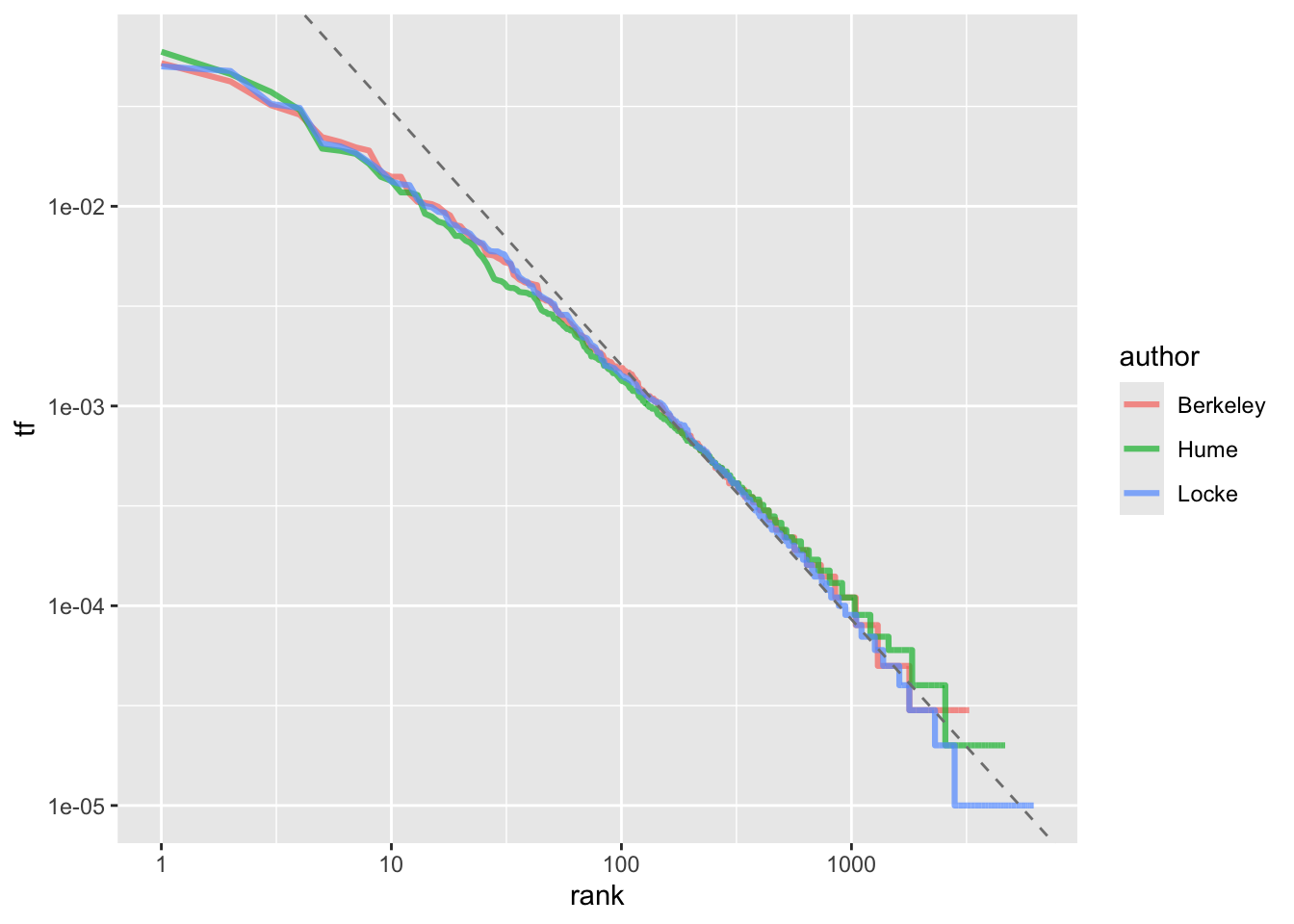
Здесь видно, что отклонения наиболее заметны в “хвостах” графика. Это характерно для многих корпусов: как очень редких, так и самых частотных слов не так много, как предсказывает закон Ципфа. Кроме того, внизу кривая почти всегда приобретает ступенчатый вид, потому что слова встречаются в корпусе дискретное число раз: ранг у них разный, а частотности одинаковые.
11.7 Меры лексического разнообразия
Коэффициент наклона α для кривой Ципфа колеблется в достаточно узком диапазоне между 0.7 и 2 и, как полагают, может быть связан с “когнитивным усилием” говорящего: например, для устной речи α чуть больше, для письменной - ниже. Однако рассматривать этот наклон как индивидуальную характеристику стиля не стоит: как и другие меры лексического разнообразия, он сильно коррелирует с длиной текста.
Дело в том, что редкие слова (события) встречаются очень часто; это явление известно под названием Large Number of Rare Events (LNRE). И чем длиннее текст, тем больше в нем будет редких слов, но скорость их прибавления постепенно уменьшается: чем дальше, тем сложнее встретить слово, которого еще не было.
Чтобы в этом убедиться, взглянем на наиболее известную мера лексического разнообразия под названием type-token ratio (TTR).
\[ TTR(T) = \frac{Voc(T)}{n} \] Здесь n - общее число токенов, а Voc (т.е. словарь) - число уникальных токенов (типов).
В пакете languageR, написанном лингвистом Гаральдом Баайеном, есть функция, позволяющая быстро производить такие вычисления. Она требует на входе вектор, а не тиббл, поэтому для эксперимента извлечем один из текстов.
locke_words <- corpus_words %>%
filter(author == "Locke") %>%
pull(word)
length(locke_words)[1] 148171Функция считает различные меры лексического разнообразия, из которых нас сейчас будет интересовать наклон Ципфа и TTR.
library(languageR)
locke.growth = growth.fnc(text = locke_words, size = 1000, nchunks = 40)........................................growth_df <- locke.growth@data$data
growth_dfБыстро визуализировать результат можно при помощи plot(locke.growth), но мы воспользуемся ggplot2.
library(gridExtra)
p1 <- growth_df |>
ggplot(aes(Tokens, Types)) +
geom_point(color = "steelblue")
p2 <- growth_df |>
ggplot(aes(Tokens, Zipf)) +
geom_point(color = "#B44682") +
ylab("Zipf Slope")
p3 <- growth_df |>
ggplot(aes(Tokens, TypeTokenRatio)) +
geom_point(color = "#81B446")
p4 <- growth_df |>
ggplot(aes(Tokens, HapaxLegomena / Tokens)) +
geom_point(color = "#B47846") +
ylab("Growth Rate")
grid.arrange(p1, p2, p3, p4, nrow=2)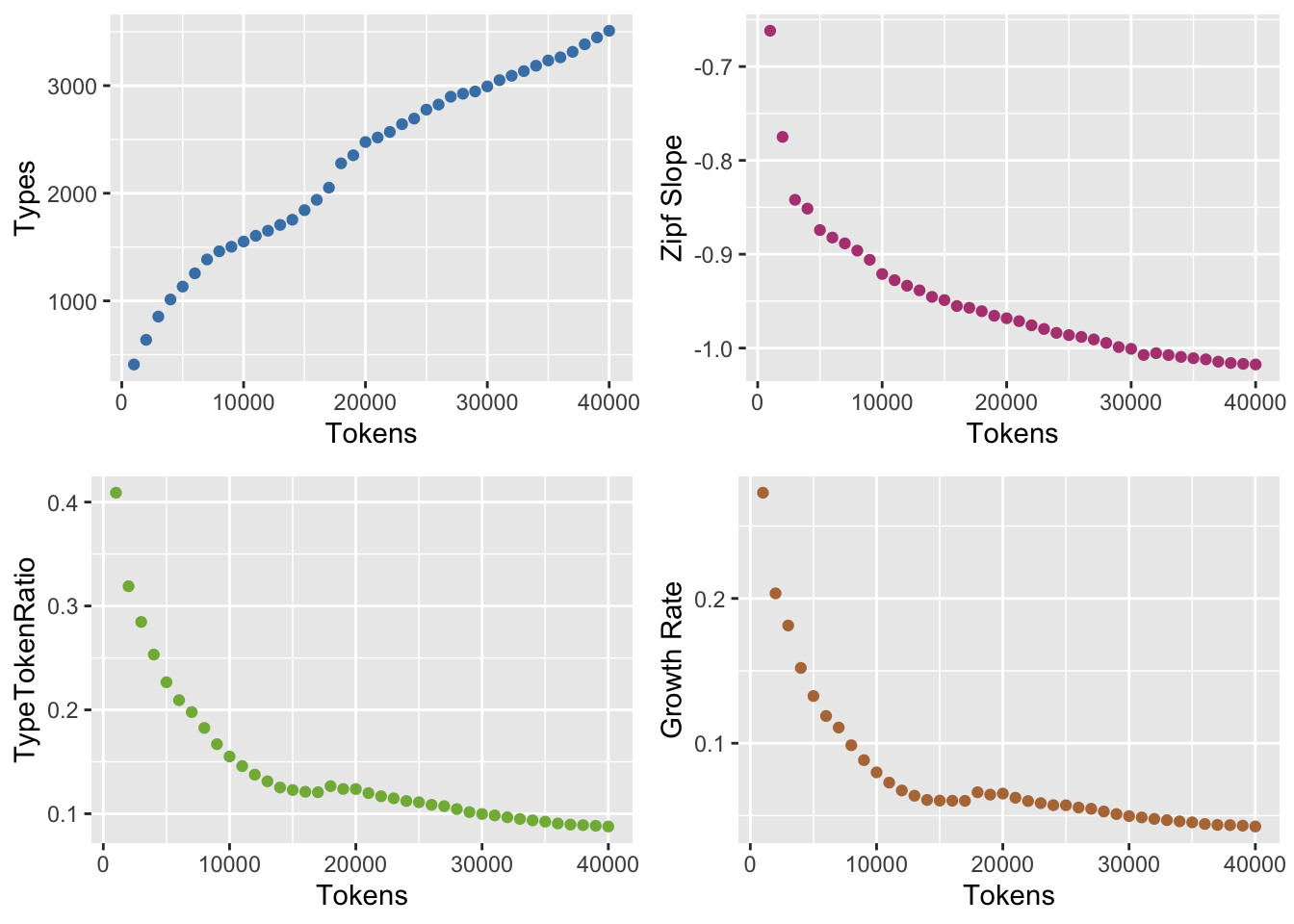
Подробнее о различных мерах лексического разнообразия см.: (Baayen 2008, 222–36) и (Savoy 2020).
11.8 TF-IDF
Наиболее частотные слова (с низким рангом) наименее подвержены влиянию тематики, поэтому их используют для стилометрического анализа. Если отобрать наиболее частотные после удаления стоп-слов, то мы получим достаточно адекватное отражение тематики документов. Если же мы необходимо найти наиболее характерные для документов токены, то применяется другая мера, которая называется tf-idf (term frequency - inverse document frequency).
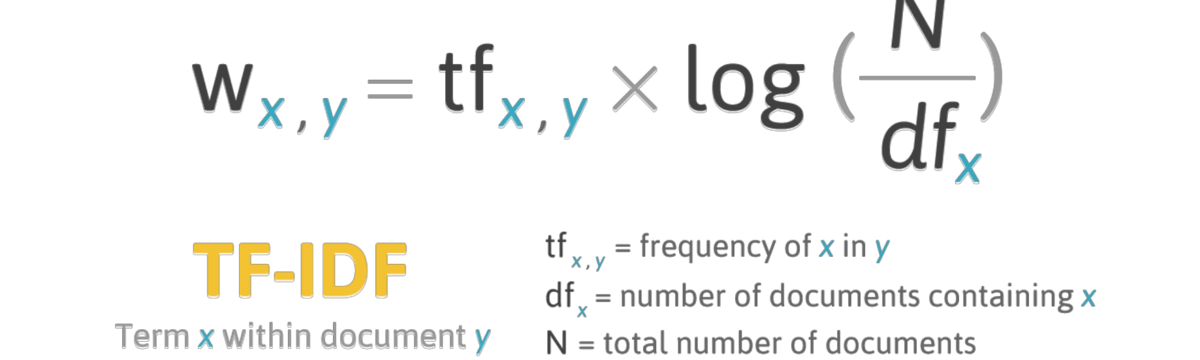
Логарифм единицы равен нулю, поэтому если слово встречается во всех документах, его tf-idf равно нулю. Чем выше tf-idf, тем более характерно некое слово для документа. При этом относительная частотность тоже учитывается! Например, Беркли один раз упоминает “сахарные бобы”, а Локк – “миндаль”, но из-за редкой частотности tf-idf для подобных слов будет низкой.
Функция bind_tf_idf() принимает на входе тиббл с абсолютной частотностью для каждого слова.
author_word_tfidf <- author_word_tf |>
bind_tf_idf(word, author, n)
author_word_tfidfПосмотрим на слова с высокой tf-idf:
author_word_tfidf |>
select(-total) |>
arrange(desc(tf_idf))Снова визуализируем.
author_word_tfidf |>
arrange(-tf_idf) |>
group_by(author) |>
top_n(15) |>
ungroup() |>
ggplot(aes(reorder_within(word, tf_idf, author), tf_idf, fill = author)) +
geom_col(show.legend = F) +
labs(x = NULL, y = "tf-idf") +
facet_wrap(~author, scales = "free") +
scale_x_reordered() +
coord_flip()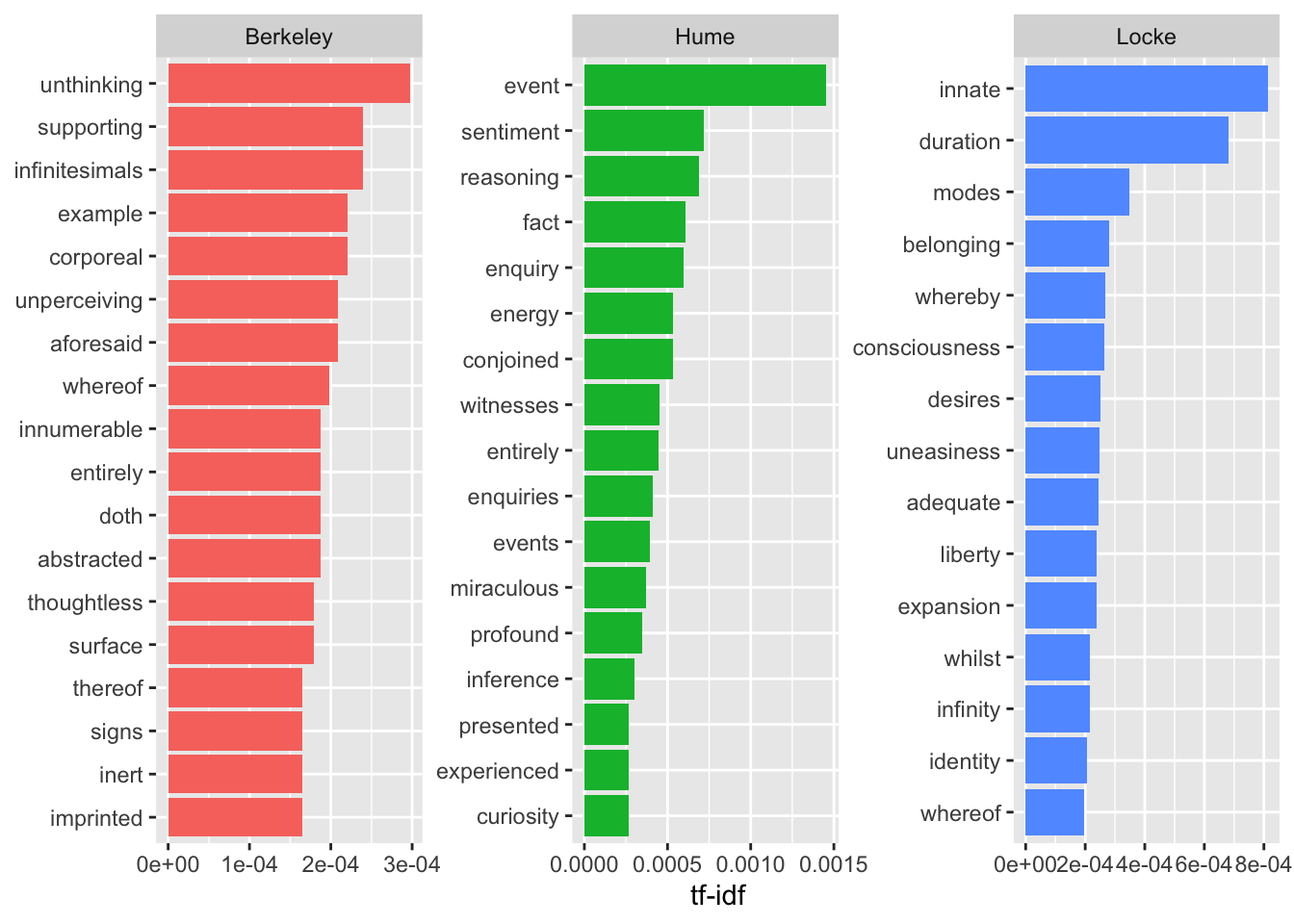
На такой диаграмме авторы совсем не похожи друг на друга, но будьте осторожны: все то, что их сближает (а это не только служебные части речи!), сюда просто не попало. Можно также заметить, что ряд характерных слов связаны не столько с тематикой, сколько со стилем: чтобы этого избежать, можно использовать лемматизацию или задать правило для замены вручную.
11.9 Сравнение при помощи диаграммы рассеяния
Столбиковая диаграмма – не единственный способ сравнить частотности слов. Еще один наглядный метод – это диаграмма рассеяния с относительными частотностями. Сначала “расширим” наш тиббл.
spread_freq <- author_word_tf |>
anti_join(stop_words) |>
filter(!word %in% other) |>
filter(tf > 0.0001) |>
select(-n, -total) |>
pivot_wider(names_from = author, values_from = tf, values_fill = 0)
spread_freqТеперь “удлиним”.
long_freq <- spread_freq |>
pivot_longer(c("Hume", "Locke"), names_to = "author", values_to = "tf")
long_freqМожно визуализировать. Обратите внимание, что частотности для Юма и Лока упаковываются в один столбец (ось X), по оси Y на обеих панелях даны частотности для Беркли (ось y).
library(scales)
long_freq |>
ggplot(aes(x = tf, y = Berkeley)) +
geom_abline(color = "grey40", lty = 2) +
geom_jitter(alpha = 0.1, size = 2.5, width = 0.3,
height = 0.3, color = "darkblue") +
geom_text(aes(label = word), check_overlap = TRUE,
vjust = 1.5, color = "grey30") +
scale_x_log10(labels = percent_format()) +
scale_y_log10(labels = percent_format()) +
facet_wrap(~author, ncol = 2) +
theme(legend.position = "none") +
theme_minimal() +
labs(y = "Berkeley", x = NULL)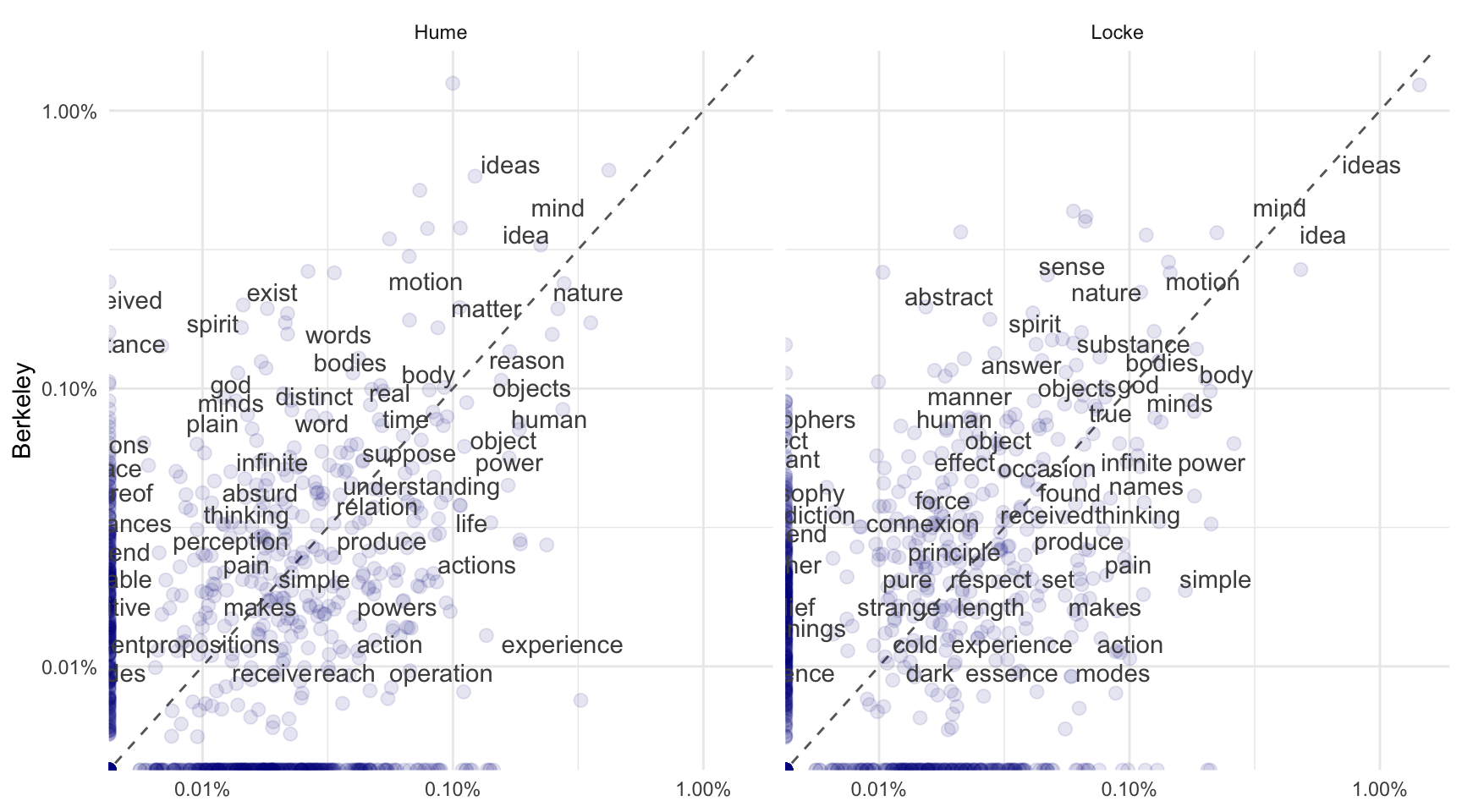
Слова, расположенные ближе к линии, примерно одинаково представлены в обоих текстах (например, “ум” и “душа” у Беркли и Локка); слова, которые находятся дальше от линии, более свойственны одному из двух авторов: например, у Беркли чаще встречается “абстрактный” по сравнению с первой книгой Локка, а у Локка чаще используется слово “простой”.
Baayen, R. H. 2008. Analyzing Linguistic Data: A Practical Introduction to Statistics using R. Cambridge University Press.
Savoy, Jacques. 2020. Machine Learning Methods for Stylometry. Springer.