library(tidyverse)
library(tidytext)
library(udpipe)6 Лемматизация и тематическое моделирование
Основные этапы NLP включают в себя токенизацию, морфологический и синтаксический анализ, а также анализ семантики и прагматики. В этом уроке речь пойдет про первые три этапа. Мы научимся разбивать текст на токены (слова), определять морфологические характеристики слов и находить их начальные формы (леммы), а также анализировать структуру предложения с использованием синтаксических парсеров.
6.1 Данные
За основу для всех эти вычислений мы возьмем три философских трактата, написанных на английском языке. Это хронологически и тематически близкие тексты:
- “Опыт о человеческом разумении” Джона Локка (1690), первые две книги;
- “Трактат о принципах человеческого знания” Джорджа Беркли (1710);
- “Исследование о человеческом разумении” Дэвида Юма (1748).
Данные были извлечены из открытой библиотеки Gutengerg при помощи пакета {gutenbergr}и приведены к опрятному виду. Скачать подготовленный таким образом корпус можно здесь.
load("../data/emp_corpus.Rdata")Делим корпус на слова уже известным вам способом.
corpus_words <- emp_corpus |>
unnest_tokens(word, text)
corpus_wordsБольшая часть слов, которые мы сейчас видим в корпусе – это шумовые слова, или стоп-слова, не несущие смысловой нагрузки.
author_word_counts <- corpus_words |>
count(author, word, sort = T)
author_word_counts |>
slice_head(n = 15) |>
ggplot(aes(reorder(word, n), n, fill = word)) +
geom_col(show.legend = F) +
facet_wrap(~author, scales = "free") +
coord_flip() +
theme_light()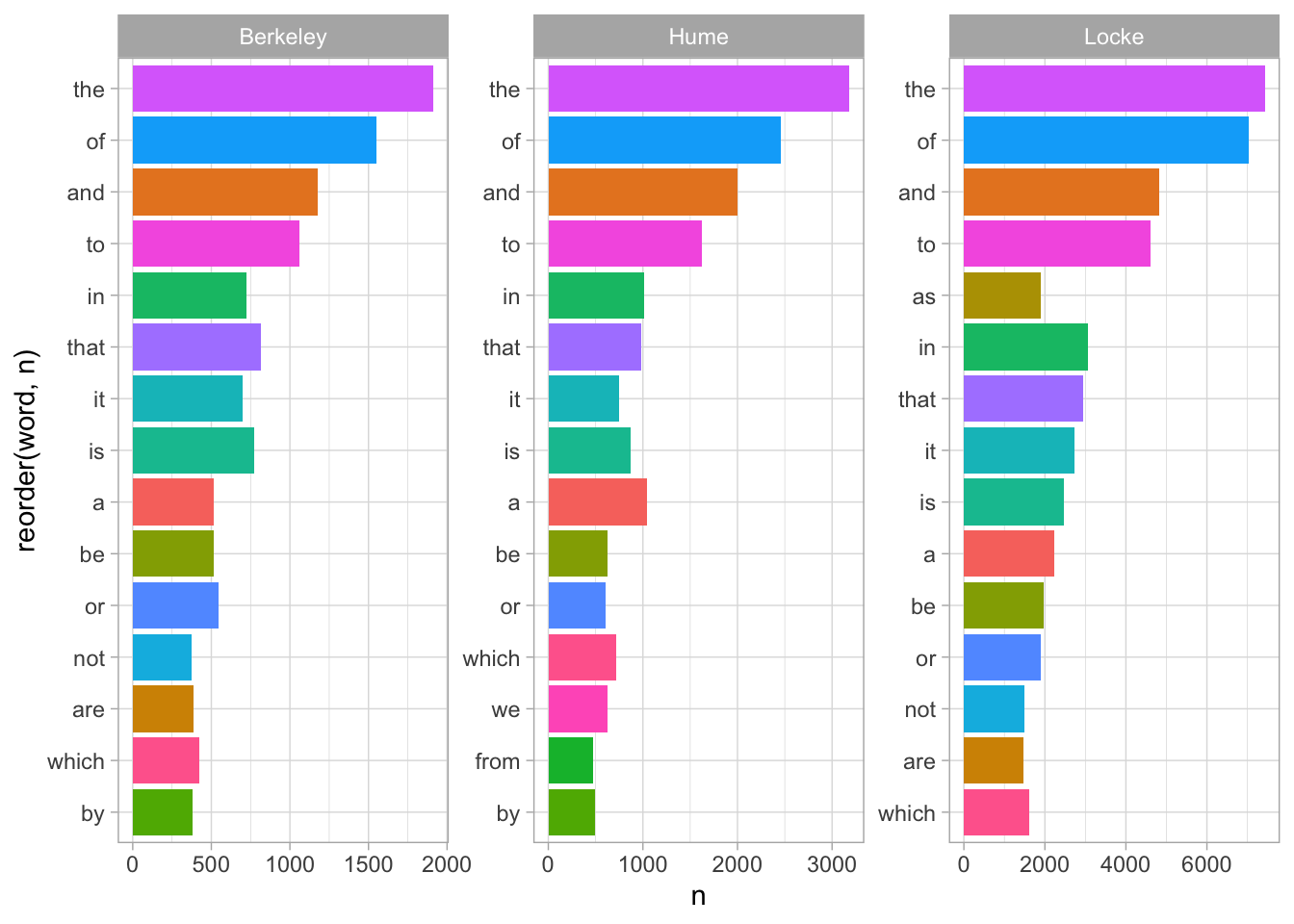
Обратите внимание: абсолютная частотность – плохой показатель для текстов разной длины. Чтобы тексты было проще сравнивать, следует разделить показатели частотности на общее число токенов в тексте.
6.2 Наиболее характерные слова
Наиболее частотные слова наименее подвержены влиянию тематики, поэтому их используют для стилометрического анализа. Если отобрать наиболее частотные после удаления стоп-слов, то мы получим достаточно адекватное отражение тематики документов.
Если же мы необходимо найти наиболее характерные для документов токены, то применяется другая мера, которая называется tf-idf (term frequency - inverse document frequency).
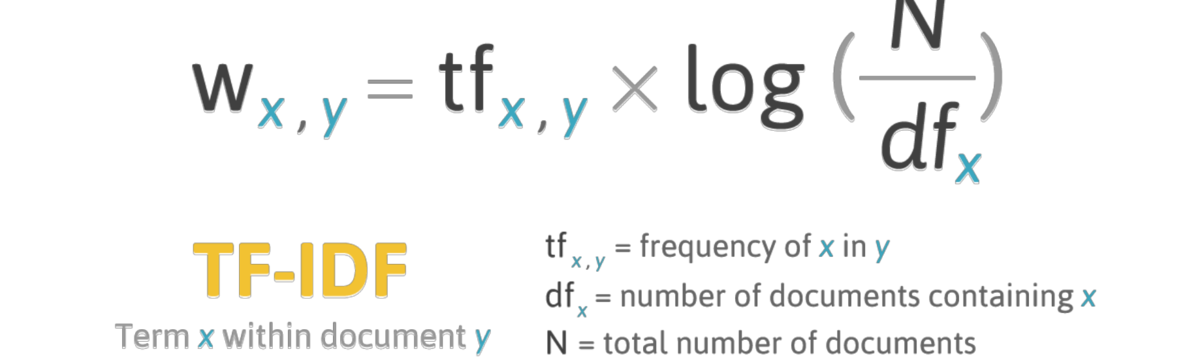
Логарифм единицы равен нулю, поэтому если слово встречается во всех документах, его tf-idf равно нулю. Чем выше tf-idf, тем более характерно некое слово для документа. При этом относительная частотность тоже учитывается! Например, Беркли один раз упоминает “сахарные бобы”, а Локк – “миндаль”, но из-за редкой частотности tf-idf для подобных слов будет низкой.
Функция bind_tf_idf() принимает на входе тиббл с абсолютной частотностью для каждого слова.
author_word_tfidf <- author_word_counts |>
bind_tf_idf(word, author, n)
author_word_tfidfВот так выглядят наиболее характерные слова для каждого автора
author_word_tfidf |>
group_by(author) |>
arrange(-tf_idf) |>
top_n(15) |>
ungroup() |>
ggplot(aes(reorder_within(word, tf_idf, author), tf_idf, fill = author)) +
geom_col(show.legend = F) +
labs(x = NULL, y = "tf-idf") +
facet_wrap(~author, scales = "free") +
scale_x_reordered() +
coord_flip()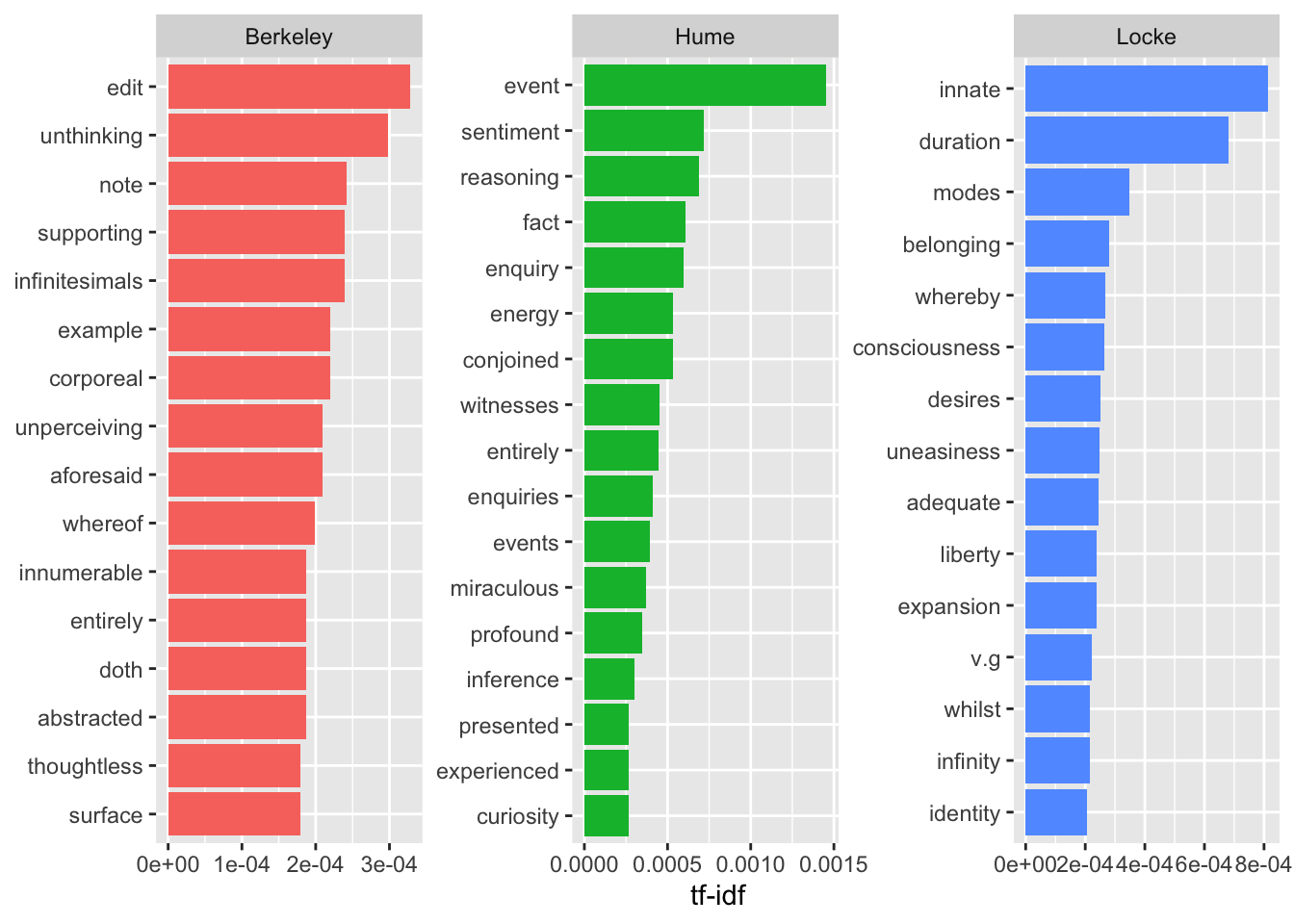
На такой диаграмме авторы совсем не похожи друг на друга, но будьте осторожны: все то, что их сближает (а это не только служебные части речи!), сюда просто не попало. Можно также заметить, что ряд характерных слов связаны не столько с тематикой, сколько со стилем: чтобы этого избежать, можно использовать лемматизацию или задать правило для замены вручную.
6.3 Лемматизация и POS-тэггинг
Лемматизация – приведение слов к начальной форме (лемме). Как правило, она проводится одновременно с частеречной разметкой (POS-tagging). Все это умеет делать UDPipe – обучаемый конвейер (trainable pipeline), для которого существует одноименный пакет в R.
Основным форматом файла для него является CoNLL-U. Файлы в таком формате хранятся в так называемых трибанках, то есть коллекциях уже размеченных текстов (название объясняется тем, что синтаксическая структура предложений представлена в них в виде древовидных графов). Файлы CoNLL-U используются для обучения нейросетей, но для большинства языков доступны хорошие предобученные модели, работать с которыми достаточно просто.
Пакет udpipe позволяет работать со множеством языков (всего 65), для многих из которых представлено несколько моделей, обученных на разных трибанках. Прежде всего нужно выбрать и загрузить модель (список). Описания моделей доступны на сайте https://universaldependencies.org/.
# скачиваем модель в рабочую директорию
#udpipe_download_model(language = "english-gum")
# загружаем модель
english_gum <- udpipe_load_model(file = "english-gum-ud-2.5-191206.udpipe")
# аннотируем (это займет несколько минут)
emp_ann <- udpipe_annotate(english_gum, emp_corpus$text, doc_id = emp_corpus$author)Результат возвращается в формате CoNLL-U; это широко применяемый формат представления результат морфологического и синтаксического анализа текстов.
Вот пример разбора предложения:
Cтроки слов содержат следующие поля:
ID: индекс слова, целое число, начиная с 1 для каждого нового предложения; может быть диапазоном токенов с несколькими словами.FORM: словоформа или знак препинания.LEMMA: Лемма или основа словоформы.UPOSTAG: тег части речи из универсального набора проекта UD, который создавался для того, чтобы аннотации разных языков были сравнимы между собой.XPOSTAG: тег части речи, который выбрали исследователи под конкретные нужды языкаFEATS: список морфологических характеристик.HEAD: идентификатор (номер) синтаксической вершины текущего токена. Если такой вершины нет, то ставят ноль (0).DEPREL: характер синтаксической зависимости.DEPS: Список вторичных зависимостей.MISC: любая другая аннотация.
Для работы данные удобнее трансформировать в прямоугольный формат.
emp_pos <- as_tibble(emp_ann) |>
select(-paragraph_id)
emp_pos 6.3.1 Поля UPOS и XPOS
Морфологическая аннотация, которую мы получили, дает возможность выбирать и группировать различные части речи. Например, существительные.
emp_pos |>
filter(upos == "NOUN") |>
select(doc_id, token, lemma, upos, xpos)Посчитать части речи можно так:
upos_counts <- emp_pos |>
count(doc_id, upos, sort = TRUE)
upos_countsОтносительные значения:
total_counts <- upos_counts |>
count(doc_id, wt = n, name = "sum_n")
pos_share <- upos_counts |>
left_join(total_counts) |>
mutate(share = round( (n/sum_n), 2))
pos_share |>
ggplot(aes(reorder(upos, share), share, fill = upos)) +
geom_col(show.legend = FALSE) +
coord_flip() +
theme_light() +
facet_wrap(~doc_id, scales = "free")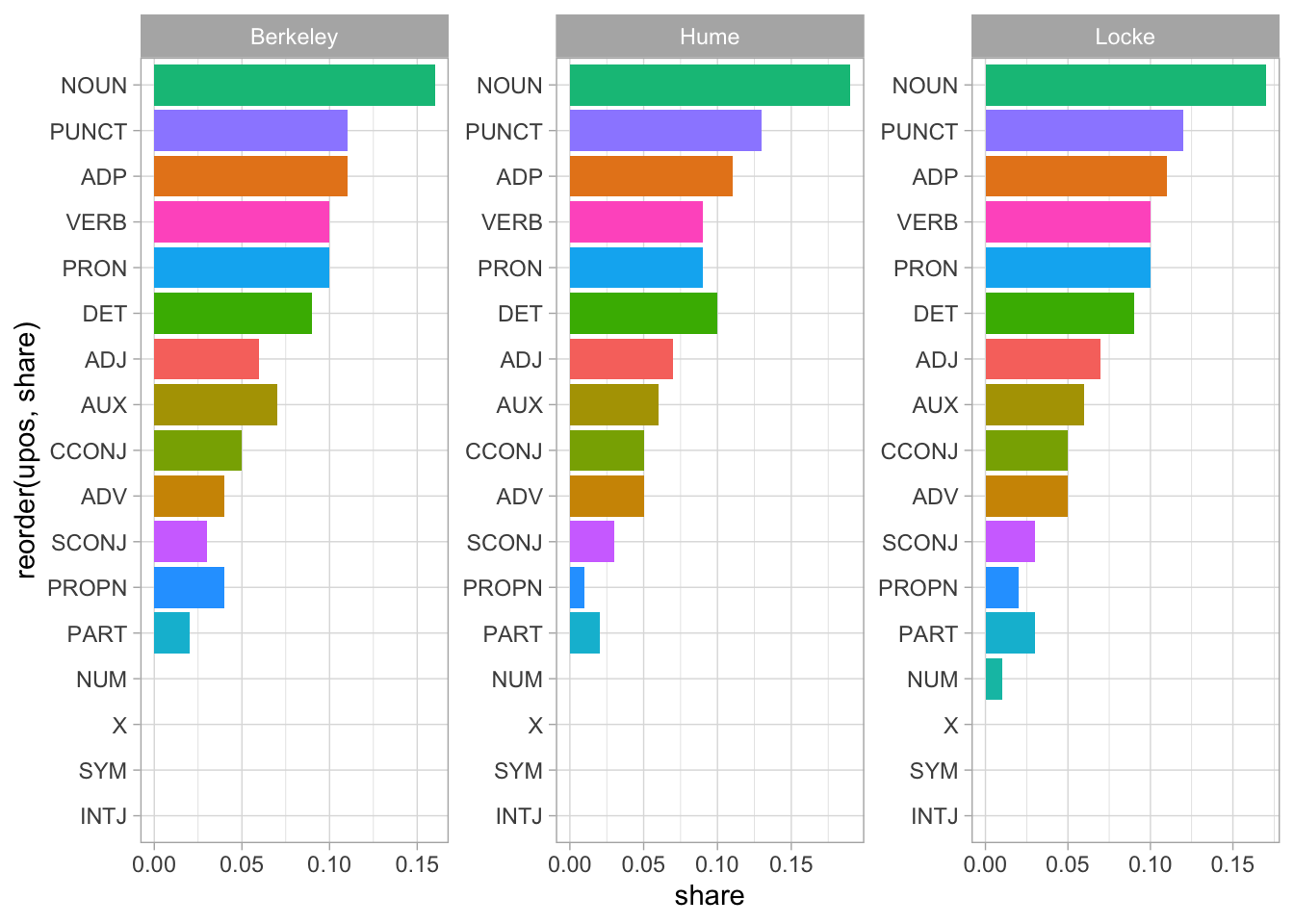
Отберем наиболее частотные имена существительные и имена собственные.
nouns <- emp_pos |>
filter(upos %in% c("NOUN", "PROPN")) |>
count(doc_id, lemma, sort = TRUE)
nounsnouns |>
group_by(doc_id) |>
slice_head(n = 10) |>
ggplot(aes(reorder_within(lemma, n, doc_id), n, fill = lemma)) +
geom_col(show.legend = FALSE) +
theme_light() +
coord_flip() +
scale_x_reordered() +
facet_wrap(~ doc_id, scales = "free") +
xlab(NULL)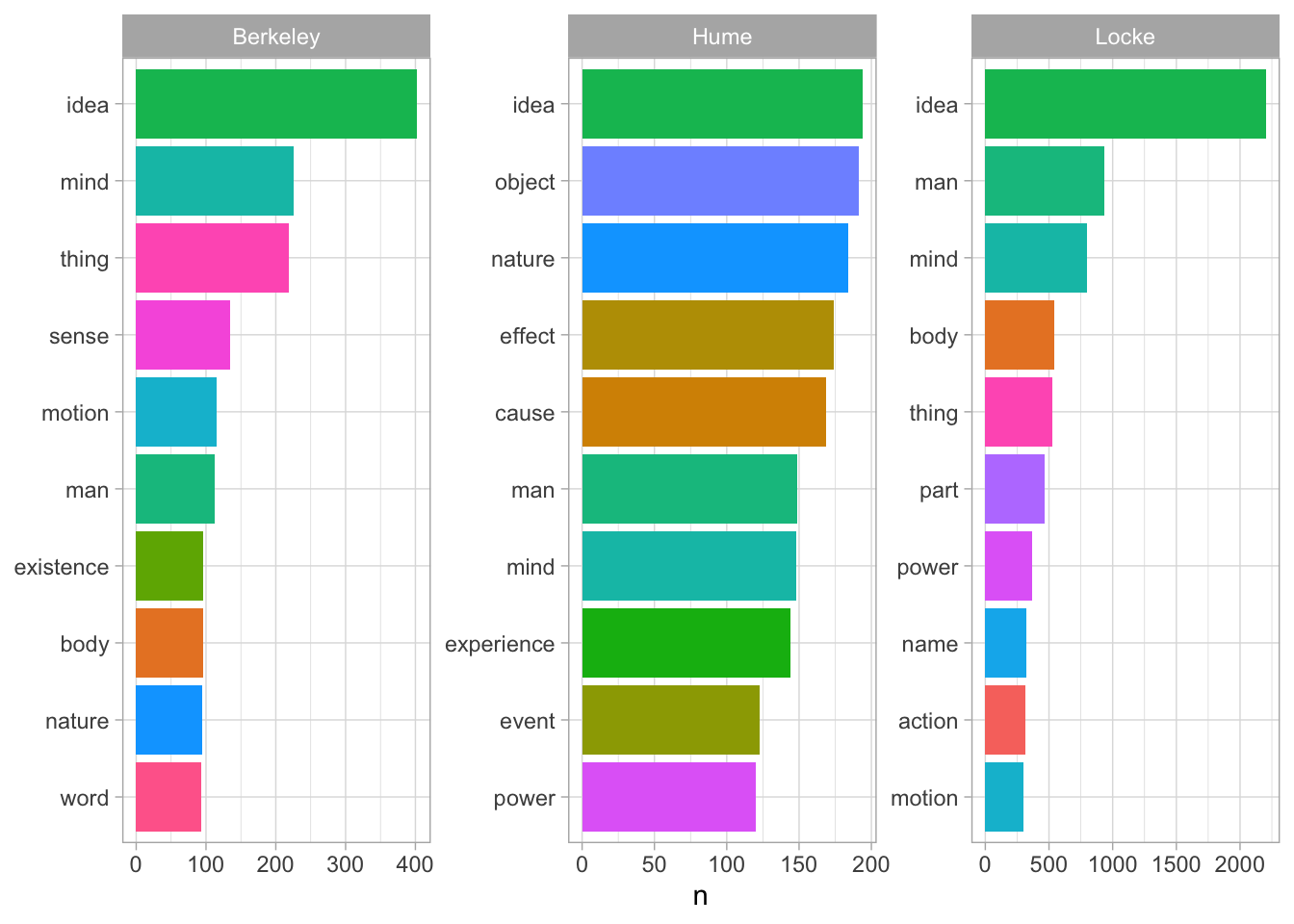
Сравните с результатом, который вы получили, считая TF-IDF.
В отличие от UPOS (Universal Part-Of-Speech), XPOS (Language-specific Part-Of-Speech) – это теги частей речи, используемые в национальных корпусах. Форматы тегов и их детализация могут значительно меняться от языка к языку.
6.3.2 Поля FEATS и DEP_REL
Допустим, нам нужны лишь определенные формы: например, прилагательные в превосходной степени.
superlatives <- emp_pos |>
filter(str_detect(feats, "Degree=Sup") & upos == "ADJ") |>
select(doc_id, token)
superlatives_counts <- superlatives |>
count(doc_id, token, sort = TRUE) |>
group_by(doc_id) |>
slice_head(n = 15)superlatives_counts |>
ggplot(aes(reorder_within(token, n, doc_id), n, fill = doc_id)) +
geom_col(show.legend = FALSE) +
coord_flip() +
theme_light() +
facet_wrap(~ doc_id, scales = "free") +
scale_x_reordered() +
xlab(NULL)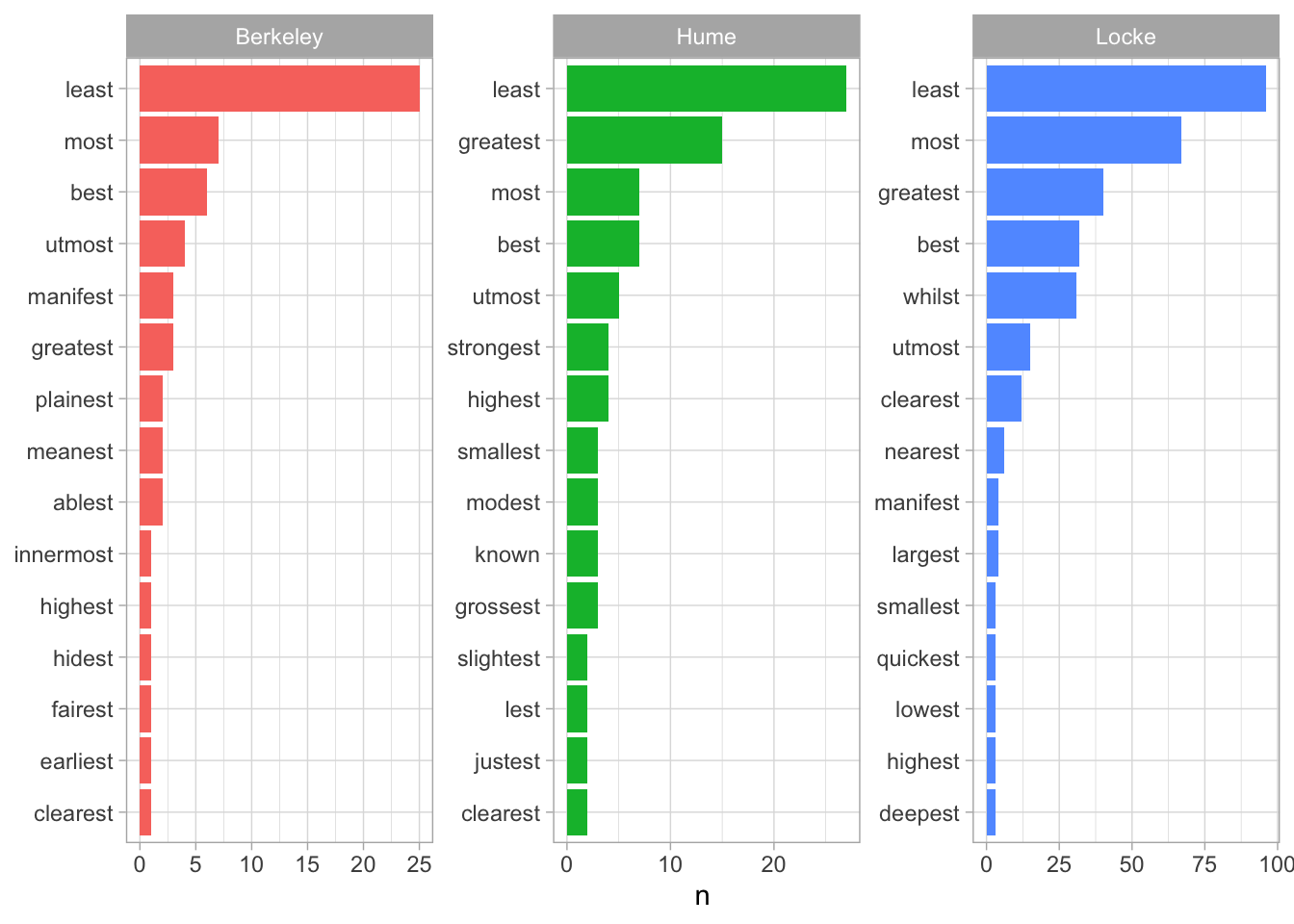
Аналогичным образом можно отбирать синтаксические признаки (DEP_REL) и их комбинации, а также визуализировать деревья зависимостей для отдельных предложений при помощи пакета {textplot}.
6.4 Совместная встречаемость слов
Функция cooccurence() из пакета udpipe позволяет выяснить, сколько раз некий термин встречается совместно с другим термином, например:
- слова встречаются в одном и том же документе/предложении/параграфе;
- слова следуют за другим словом;
- слова находятся по соседству с другим словом на расстоянии n слов.
Выясним, какие существительные чаще встречаются в одном предложении у Локка:
locke_nouns <- emp_pos |>
filter(doc_id == "Locke") |>
filter(upos == "NOUN")
locke_nounscooc <- cooccurrence(locke_nouns, term = "lemma",
group = "sentence_id") |>
as_tibble() |>
filter(cooc > 70) |>
filter(term1 != "idea", term2 != "idea")
coocЭтот результат легко визуализировать, используя пакет ggraph:
library(igraph)
library(ggraph)
wordnetwork <- graph_from_data_frame(cooc)ggraph(wordnetwork, layout = "fr") +
geom_edge_arc(aes(width = cooc), alpha = 0.8, edge_colour = "grey90", show.legend=FALSE) +
geom_node_label(aes(label = name), col = "#1f78b4", size = 4) +
theme_void() +
labs(title = "Совместная встречаемость существительных в предложении")Warning in geom_node_label(aes(label = name), col = "#1f78b4", size = 4):
Ignoring unknown parameters: `label.size`Warning: The `trans` argument of `continuous_scale()` is deprecated as of ggplot2 3.5.0.
ℹ Please use the `transform` argument instead.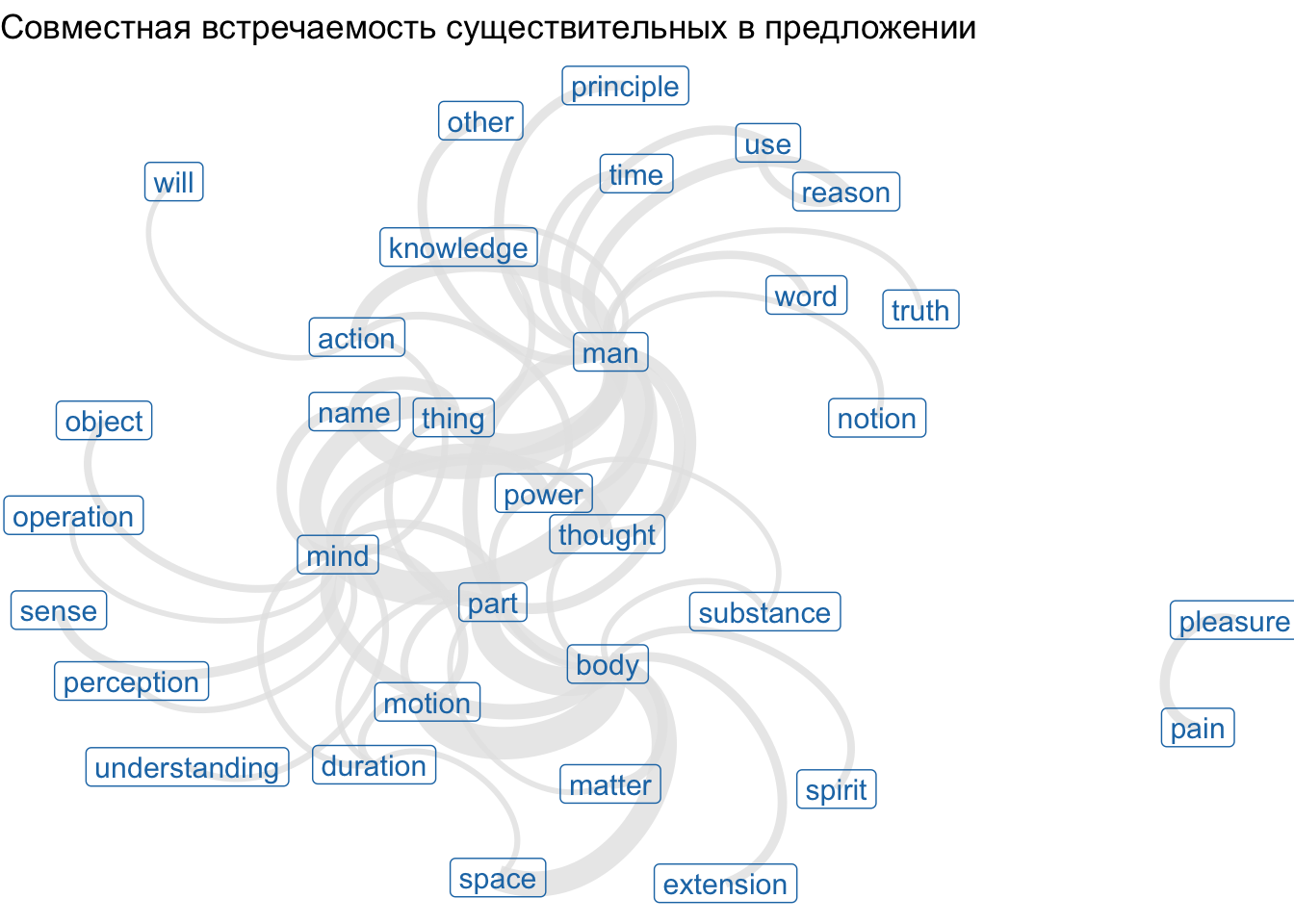
Чтобы узнать, какие слова чаще стоят рядом, используем ту же функцию, но с другими аргументами:
cooc2 <- cooccurrence(locke_nouns$lemma,
relevant = locke_nouns$upos %in% "NOUN",
skipgram = 1) |>
as_tibble() |>
filter(cooc > 10)
cooc2wordnetwork <- graph_from_data_frame(cooc2)
ggraph(wordnetwork, layout = "fr") +
geom_edge_link(aes(width = cooc), edge_colour = "grey90", edge_alpha=0.8, show.legend = F) +
geom_node_label(aes(label = name), col = "#1f78b4") +
labs(title = "Слова, стоящие рядом в тексте") +
theme_void()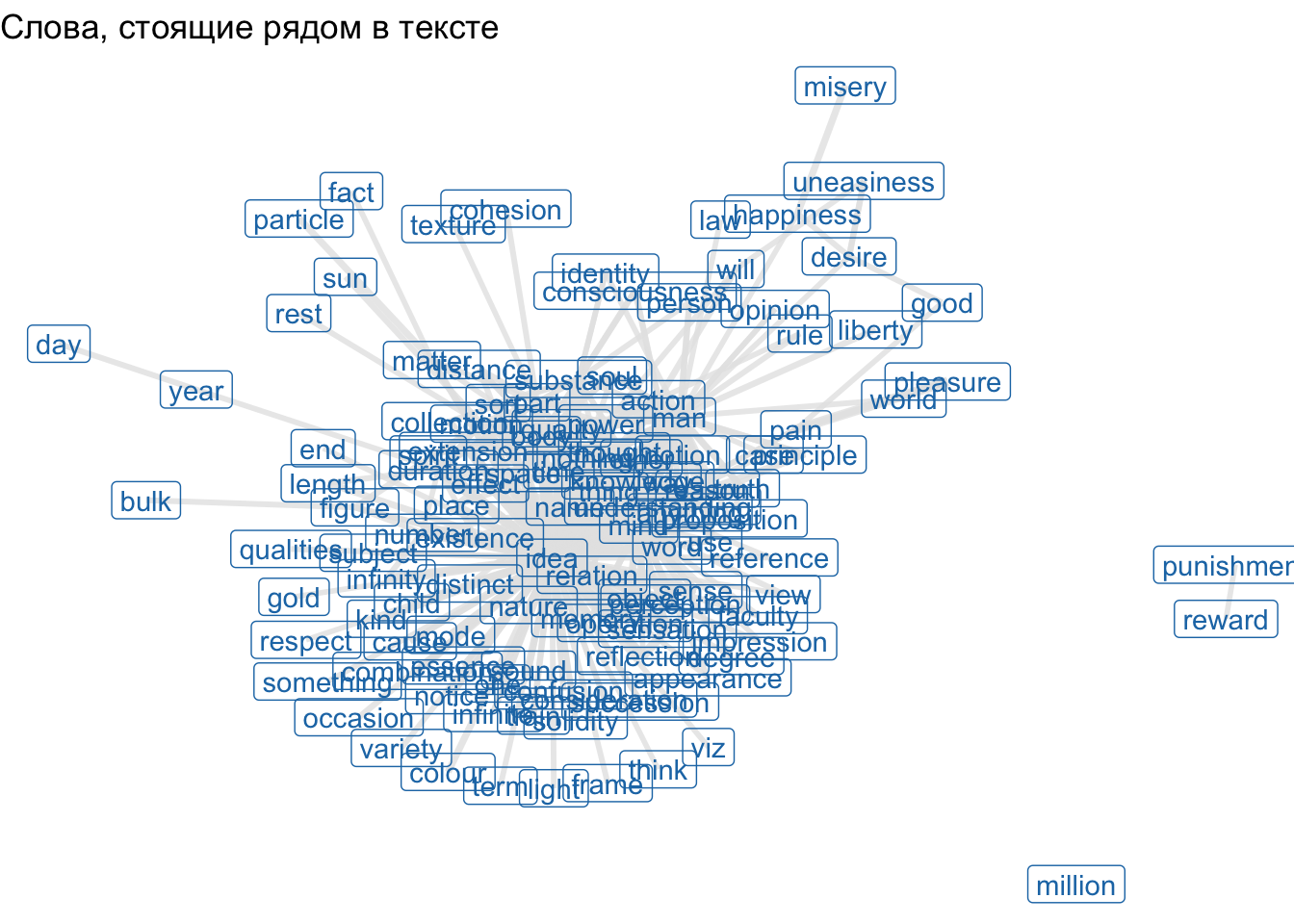
6.5 Тематическое моделирование
Вы можете легко преобразовать аннотированный тибл в матрицу “документ-термин” (document-term-matrix), которая используется во многих других пакетах для анализа текста. В данном случае мы будем выделять темы (topics) на уровне предложений.
Преимущество {udpipe} по сравнению с другими пакетами заключается в следующем:
- тематическое моделирование (topic modelling) можно проводить непосредственно по нужным словам, так как их легко определить с помощью тегов частей речи: чаще всего интересуют только существительные и глаголы или, например, только прилагательные, если вы хотите кластеризовать текст по тональности (sentiment clustering);
- больше не нужно создавать длинные списки стоп-слов;
- кроме того, можно работать с леммами, а не с исходными формами слов, что позволяет схожим словам лучше группироваться друг с другом;
- вы легко можете включать составные ключевые слова.
Отбираем только существительные.
emp_pos$topic_level_id <- unique_identifier(emp_pos, fields = c("doc_id", "sentence_id"))
dtf <- emp_pos |>
filter(upos == "NOUN")dtf <- document_term_frequencies(dtf, document = "topic_level_id", term = "lemma")
head(dtf)dtm <- document_term_matrix(x = dtf)dtm_clean <- dtm_remove_lowfreq(dtm, minfreq = 5)
sample(dtm_colsums(dtm_clean), 10) generality acknowledge farther patron note praise
14 8 8 7 33 6
probity cure uniform spectator
5 9 9 5 library(topicmodels)
m <- LDA(dtm_clean, k = 4, method = "Gibbs",
control = list(nstart = 5, burnin = 2000, best = TRUE, seed = 1:5))Чтобы интерпретировать тематическую модель и подобрать подходящие названия темам, вы можете получить наиболее часто встречающиеся термины для каждой темы, указав минимальную вероятность появления термина и минимальное количество отображаемых терминов.
topicterminology <- predict(m, type = "terms",
min_posterior = 0.005,
min_terms = 3)
topicterminology$topic_001
term prob
1 body 0.063299870
2 part 0.055656535
3 motion 0.042793360
4 thought 0.032819738
5 time 0.026481362
6 existence 0.022380060
7 number 0.021727580
8 space 0.020981889
9 matter 0.020049775
10 place 0.019490506
11 duration 0.019210872
12 nothing 0.019024449
13 extension 0.017719490
14 world 0.013338553
15 anything 0.012965708
16 distance 0.012313228
17 figure 0.011940382
18 person 0.011940382
19 something 0.010635422
20 end 0.010355788
21 consciousness 0.009144040
22 light 0.009050828
23 appearance 0.008864405
24 side 0.008025503
25 measure 0.007745868
26 rest 0.007745868
27 be 0.007652657
28 hand 0.007652657
29 year 0.007466234
30 difficulty 0.007186600
31 sun 0.007186600
32 eye 0.007000177
33 length 0.007000177
34 succession 0.006813754
35 think 0.006720543
36 infinity 0.006254486
37 moment 0.005974852
38 particle 0.005695217
39 animal 0.005602006
40 identity 0.005602006
41 supposition 0.005602006
42 change 0.005508794
43 line 0.005508794
44 mark 0.005508794
45 sight 0.005135949
46 solidity 0.005042737
$topic_002
term prob
1 idea 0.245654014
2 mind 0.109205398
3 thing 0.069582283
4 name 0.034144708
5 sense 0.030796276
6 substance 0.030145192
7 word 0.027261820
8 quality 0.018518691
9 relation 0.017960619
10 sensation 0.016100379
11 spirit 0.013775078
12 perception 0.013217006
13 colour 0.013123994
14 sort 0.011914838
15 memory 0.010519658
16 distinct 0.010426646
17 reflection 0.010240622
18 mode 0.007915322
19 one 0.007915322
20 sound 0.007729298
21 essence 0.006520142
22 notice 0.006520142
23 occasion 0.006055082
24 language 0.005869058
$topic_003
term prob
1 power 0.050329463
2 action 0.040791100
3 object 0.037384542
4 nature 0.035632598
5 effect 0.025996905
6 cause 0.025802244
7 understanding 0.018891798
8 operation 0.018599807
9 experience 0.018113156
10 pain 0.017918496
11 life 0.015874561
12 will 0.015095919
13 manner 0.013149314
14 pleasure 0.012857324
15 instance 0.012759993
16 event 0.012176012
17 degree 0.011786691
18 nothing 0.011494700
19 kind 0.011397370
20 happiness 0.010910719
21 philosopher 0.010618728
22 case 0.010229407
23 subject 0.010132077
24 view 0.010034747
25 law 0.009742756
26 connexion 0.009353435
27 good 0.009256105
28 consideration 0.008964114
29 liberty 0.008964114
30 desire 0.008769454
31 force 0.008380133
32 circumstance 0.008185472
33 uneasiness 0.007990812
34 passion 0.007017510
35 regard 0.006530859
36 course 0.006433528
37 necessity 0.006433528
38 observation 0.006433528
39 state 0.006433528
40 respect 0.006044207
41 inference 0.005557556
42 occasion 0.005460226
43 attention 0.005265566
$topic_004
term prob
1 man 0.112073717
2 reason 0.037138741
3 principle 0.032014155
4 knowledge 0.025342525
5 other 0.022635197
6 use 0.022345126
7 truth 0.022055055
8 way 0.021184843
9 notion 0.018960966
10 proposition 0.014029761
11 argument 0.013062858
12 opinion 0.012482717
13 soul 0.012386026
14 rule 0.011419123
15 question 0.009968769
16 philosophy 0.009872079
17 child 0.009775388
18 fact 0.009775388
19 term 0.009775388
20 mankind 0.009582008
21 faculty 0.009291937
22 reasoning 0.008711795
23 impression 0.008228344
24 miracle 0.008131654
25 order 0.007454821
26 evidence 0.007068060
27 variety 0.006971370
28 consequence 0.006874680
29 age 0.006777989
30 viz 0.006681299
31 answer 0.006584609
32 conclusion 0.006391228
33 doubt 0.006391228
34 proof 0.006197848
35 maxim 0.006004467
36 testimony 0.006004467
37 purpose 0.005907777
38 difference 0.005811087
39 doctrine 0.005811087
40 character 0.005714396
41 foundation 0.005521016
42 sentiment 0.005230945
43 authority 0.005134254
44 discourse 0.005134254
45 judgment 0.005134254
46 people 0.005134254Кроме того, мы также можем легко использовать модель для предсказания, к какой теме принадлежит новый документ. Функция predict корректно возвращает значение NA для тех документов, в которых отсутствуют слова, использованные в модели, что обычно вызывает затруднения в других пакетах R. Также функция позволяет присваивать каждой теме метки и показывает разницу в вероятности между наиболее вероятной темой и следующей по вероятности, что полезно для оценки чёткости (разграниченности) ваших тем.
scores <- predict(m, newdata = dtm_clean, type = "topics",
labels = c("physics", "psychology", "ethics", "epistemology"))Аргумент labels присваивает пользовательские имена темам в итоговом результате предсказания.
Визуализируем топики.
emp_topics <- merge(emp_pos, scores, by.x="topic_level_id", by.y="doc_id")wordnetwork <- subset(emp_topics, topic %in% 1 & lemma %in% topicterminology[[1]]$term)wordnetwork <- cooccurrence(wordnetwork, group = c("topic_level_id"), term = "lemma")
wordnetwork <- graph_from_data_frame(wordnetwork)ggraph(wordnetwork, layout = "fr") +
geom_edge_link(aes(width = cooc, edge_alpha = cooc), edge_colour = "pink") +
geom_node_text(aes(label = name), col = "darkgreen", size = 4) +
theme_graph(base_family = "Arial Narrow") +
labs(title = "Words in topic Physics ", subtitle = "Nouns Cooccurrence")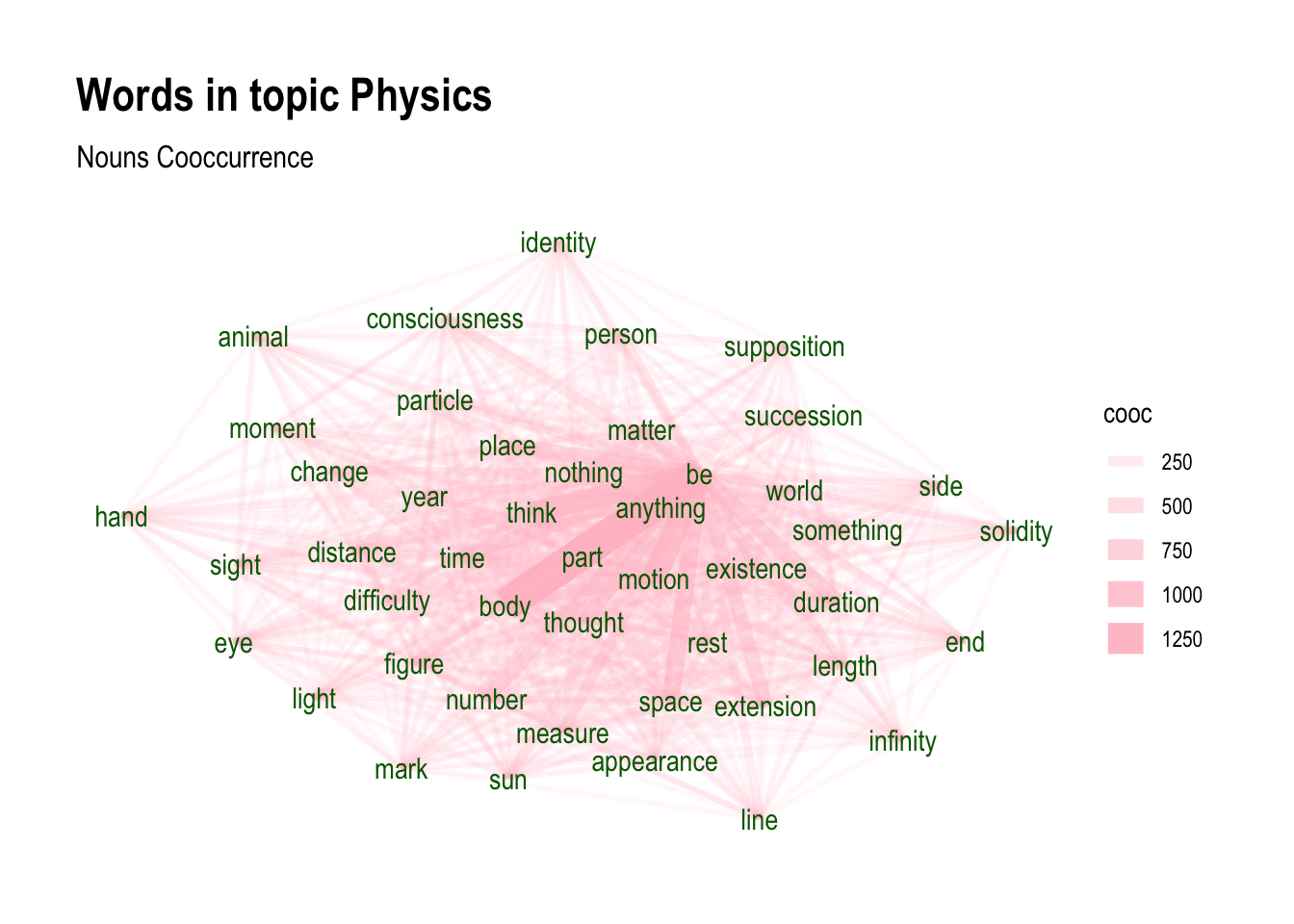
6.6 Видео
- Видео 2025 г.
6.7 Домашнее задание
По ссылке вы найдете датасет со сказками Салтыкова-Щедрина (в формате .Rdata). Вам необходимо аннотировать сказки, используя модель SynTagRus.
После этого ответьте на вопросы по ссылке. Задание считается выполненным, если верные ответы даны на 3 из 5 вопросов.
Ошибки лемматизации и морфологического анализа игнорируйте.
Дедлайн: 28 ноября, 21-00.