В этом уроке мы научимся работать с “прямоугольными”, т.е. табличными, данными на примере корпуса русской элегии 1815—1835 гг., собранного и опубликованного Антониной Мартыненко в 2020 г.
Существуют два основных “диалекта” R, один из которых опирается главным образом на функции и структуры данных базового R, а другой пользуется синтаксисом tidyverse. Tidyverse – это семейство пакетов (метапакет), разработанных Хадли Уикхемом и др., которое включает в себя в том числе пакеты dplyr, ggplot2 и многие другие.
library(tidyverse)
Warning: package 'ggplot2' was built under R version 4.5.2
Warning: package 'readr' was built under R version 4.5.2
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.6
✔ forcats 1.0.0 ✔ stringr 1.6.0
✔ ggplot2 4.0.1 ✔ tibble 3.3.0
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.2.0
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
2.1 Импорт табличных данных
Файл можно скачать вручную по ссылке выше или воспользоваться специальной функцией.
В окружении появится объект url. Это строка, т.е. последовательность символов. Передаем ее в качестве аргумента функции download.file(); вторым аргументом указываем название файла-назначения:
download.file(url, destfile ="elegies.tab")
После этого можно прочитать файл в окружение:
elegies_tbl <-read_tsv("elegies.tab")
Rows: 509 Columns: 20
── Column specification ────────────────────────────────────────────────────────
Delimiter: "\t"
chr (18): Signature, Author, Title, First line, Meter, Razmer, Razmer_wclaus...
dbl (2): id, Year1
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
2.2 Анализ и обобщение данных
2.2.1 Tibble
Основная структура данных в tidyverse – это tibble, современный вариант датафрейма. Тиббл, как говорят его разработчики, это ленивые и недовольные датафреймы: они делают меньше и жалуются больше. Это позволяет решать проблемы на более ранних этапах, что, как правило, приводит к созданию более чистого и выразительного кода.
Основные отличия от обычного датафрейма:
усовершенствованный метод print(), не нужно постоянно вызывать head();
нет имен рядов;
допускает синтаксически “неправильные” имена столбцов;
при индексировании не превращается в вектор.
Преобразуем наш тиббл в датафрейм для сравнения.
elegies_df <-as.data.frame(elegies_tbl)
2.2.2 Dplyr
“Грамматика манипуляции данных”, лежащая в основе dplyr, предоставляет последовательный набор глаголов, которые помогают решать наиболее распространенные задачи манипулирования данными:
mutate() добавляет новые переменные, которые являются функциями существующих переменных;
select() выбирает переменные (столбцы) на основе их имен;
filter() выбирает наблюдения (ряды) на основе их значений;
summarise() обобщает значения;
arrange() изменяет порядок следования строк.
Все эти глаголы естественным образом сочетаются с функцией group_by(), которая позволяет выполнять любые операции “по группам”, и с оператором pipe |> из пакета magrittr.
В итоге получается лаконичный и читаемый код. Узнаем, за какие года у нас есть элегии.
Сначала напишем небольшую вспомогательную функцию read_text. Тело функции всегда заключается в фигурные скобки. Эта функция читает построчно каждый файл, а затем “схлопывает” строки в единый вектор через пробел (это делает функция str_c() из пакета stringr). Функция map_chr() из пакета purrr позволяет запустить нашу “доморощенную” функцию 509 раз, по числу файлов (их список отдаем ей первым аргументом). Результат возвращается в виде длинного вектора, который мы превращаем в столбец нового тиббла.
read_text <-function(file){read_lines(file) |>str_c(collapse =" ") }elegies_texts <-tibble(title = elegies_files, # в столбец title кладем имена файловtext =map_chr(elegies_files, read_text) # в столбец text кладем тексты элегий )elegies_texts |>print()
# A tibble: 509 × 2
title text
<chr> <chr>
1 corpus/1_DGlebov_1818.txt "Надеясь сердца грусть разлукой облегчить, Беж…
2 corpus/10_Baratynsky_1820.txt "Мечты волшебные, вы скрылись от очей! Сбылися…
3 corpus/100_Pushkin_1825.txt "Когда, любовию и негой упоенный, Безмолвно пр…
4 corpus/101_Jazykov_1825.txt "Счастлив, кто с юношеских дней, Живыми чувств…
5 corpus/102_Jazykov_1825.txt "Свободен я: уже не трачу Ни дня, ни ночи, ни …
6 corpus/103_Jazykov_1825.txt "Я знал живое заблужденье; Любовь певал я - бы…
7 corpus/104_Jazykov_1825.txt "Моя Камена ей певала; Но сила взора красоты Н…
8 corpus/105_Unknown_1826.txt "Время быстро Пролетает; Пламя жизни Угасает. …
9 corpus/11_Pushkin_1820.txt "Погасло дневное светило; На море синее вечер…
10 corpus/112_Jazykov_1824.txt "Скажи: воротишься ли ты, Моя пленительная ра…
# ℹ 499 more rows
Теперь преобразуем столбец title: оставим только id.
elegies_sep <- elegies_texts |>mutate(title =str_remove(title, "corpus/")) |>separate(title, into =c("id", NA)) |># отбрасываем все после id mutate(id =as.numeric(id))
# A tibble: 509 × 2
id text
<dbl> <chr>
1 1 "Надеясь сердца грусть разлукой облегчить, Бежал я милых мест, неверно…
2 10 "Мечты волшебные, вы скрылись от очей! Сбылися времени угрозы! Хладеет…
3 100 "Когда, любовию и негой упоенный, Безмолвно пред тобой коленопреклонен…
4 101 "Счастлив, кто с юношеских дней, Живыми чувствами убогой, Идет просело…
5 102 "Свободен я: уже не трачу Ни дня, ни ночи, ни стихов За милый взгляд, …
6 103 "Я знал живое заблужденье; Любовь певал я - были дни: Теперь умчалися …
7 104 "Моя Камена ей певала; Но сила взора красоты Не мучала, не услаждала М…
8 105 "Время быстро Пролетает; Пламя жизни Угасает. Нет замены Наслажденьям;…
9 11 "Погасло дневное светило; На море синее вечерний пал туман. Шуми, шу…
10 112 "Скажи: воротишься ли ты, Моя пленительная радость? Ужель моя погасн…
# ℹ 499 more rows
2.4 Объединение данных
Теперь мы можем объединить метаданные с конкретными текстами.
Отберем из датасета только Пушкина и Баратынского (Пушкиных там двое, так что указываем инициалы. Вертикальная черта - это логичеческий оператор “ИЛИ”. Функция str_detect() возвращает логический вектор, который используется для фильтрации.
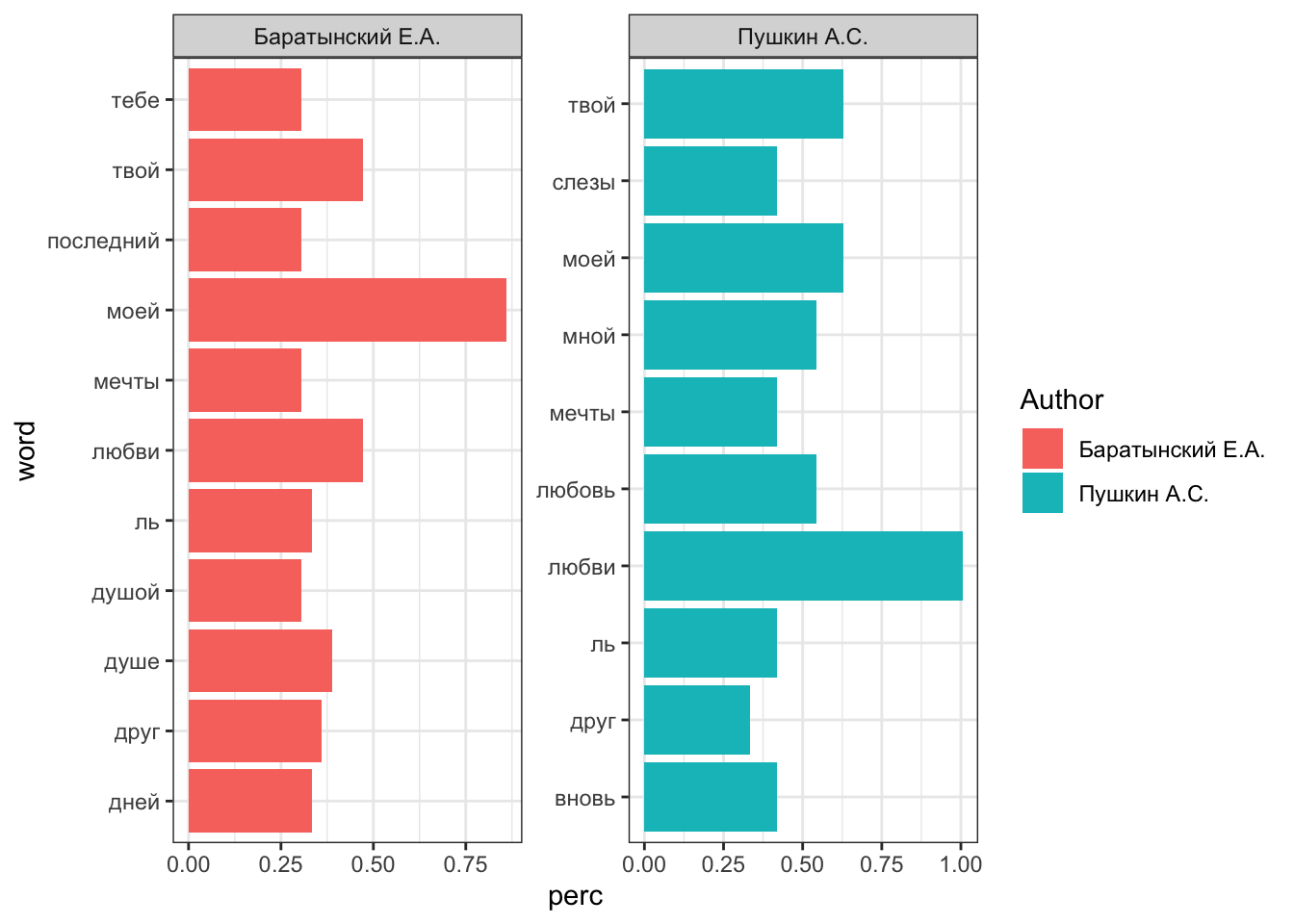
# A tibble: 21 × 4
# Groups: Author [2]
Author word n perc
<chr> <chr> <int> <dbl>
1 Баратынский Е.А. моей 31 0.860
2 Баратынский Е.А. любви 17 0.472
3 Баратынский Е.А. твой 17 0.472
4 Баратынский Е.А. душе 14 0.388
5 Баратынский Е.А. друг 13 0.361
6 Баратынский Е.А. дней 12 0.333
7 Баратынский Е.А. ль 12 0.333
8 Баратынский Е.А. душой 11 0.305
9 Баратынский Е.А. мечты 11 0.305
10 Баратынский Е.А. последний 11 0.305
# ℹ 11 more rows
2.8 Визуализации
В tidyverse входит пакет ggplot2 для визуализации данных. В его основе лежит идея “грамматики графических элементов” Лиланда Уилкинсона (Мастицкий 2017) (отсюда “gg” в названии).
Функция ggplot() имеет два основных аргумента: data и mapping. Аргумент mapping задает эстетические атрибуты геометрических объектов. Обычно используется в виде mapping = aes(x, y), где aes() означает aesthetics.
Под “эстетикой” подразумеваются графические атрибуты, такие как размер, форма или цвет. Вы не увидите их на графике, пока не добавите какие-нибудь “геомы” – геометрические объекты (точки, линии, столбики и т.п.). Эти объекты могут слоями накладываться друг на друга (Wickham и Grolemund 2016).
Каждый геометрический объект может иметь свои специфические параметры. Например, geom_point() может варьировать размер, цвет, форму и прозрачность точек, а geom_line() — тип, толщину и цвет линии. Эти параметры можно задавать как внутри aes() (когда они зависят от данных), так и вне её (когда задаются константы).
В этом задании вы исследуете корпус русской песни. Источник.
Оценка 0-10. Выполнять все пункты задания не обязательно: на оценку 9-10 требования очень высокие (так и задумано).
Сам корпус и заготовку для кода вы найдете, приняв задание по ссылке: https://classroom.github.com/a/zlrC_zDL. Если вы не видите себя в списке студентов, напишите преподавателю.
После этого GitHub создаст репозиторий для сдачи домашнего задания. Клонируйте его (т.е. создайте локальный проект под контролем версий, как мы делали в первом уроке).
Внесите необходимые изменения в файл hw2.R, после чего закоммитьте изменения и сделайте push. Если не получится, используйте кнопку Upload files.
Критерии оценивания:
Весь код должен запускаться без ошибок (в противном случае – минус 4 балла).
В случае выявления плагиата всем соучастникам ставится оценка 0 без возможности пересдачи.
После дедлайна (3 октября 21-00 мск) задание не принимается.