library(tidyverse)Warning: package 'ggplot2' was built under R version 4.5.2Warning: package 'readr' was built under R version 4.5.2library(xml2)XML (от англ. eXtensible Markup Language) — расширяемый язык разметки. Слово “расширяемый” означает, что список тегов не зафиксирован раз и навсегда: пользователи могут вводить свои собственные теги и создавать так называемые настраиваемые языки разметки (Холзнер 2004, 29). Один из таких настраиваемых языков – это TEI (Text Encoding Initiative), о котором будет сказано дальше.
Для работы нам понадобятся следующие библиотеки:
library(tidyverse)Warning: package 'ggplot2' was built under R version 4.5.2Warning: package 'readr' was built under R version 4.5.2library(xml2)Назначение языков разметки заключается в описании структурированных документов. Структура документа представляется в виде набора вложенных в друг друга элементов (дерева XML). У элементов есть открывающие и закрывающие теги. Все составляющие части документа обобщаются в пролог и корневой элемент. Корневой элемент — обязательная часть документа, в которую вложены все остальные элементы. Пролог может включать объявления, инструкции обработки, комментарии.
В правильно сформированном XML открывающий и закрывающий тег вложенного элемента всегда находятся внутри одного родительского элемента.
Создадим простой XML из строки. Сначала идет инструкция по обработке XML (со знаком вопроса), за ней следует объявление типа документа (с восклицательным знаком) и открывающий тег корневого элемента. В этот корневой элемент вложены все остальные элементы.
string_xml <- '<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE recipe>
<recipe name="хлеб" preptime="5min" cooktime="180min">
<title>
Простой хлеб
</title>
<composition>
<ingredient amount="3" unit="стакан">Мука</ingredient>
<ingredient amount="0.25" unit="грамм">Дрожжи</ingredient>
<ingredient amount="1.5" unit="стакан">Тёплая вода</ingredient>
</composition>
<instructions>
<step>
Смешать все ингредиенты и тщательно замесить.
</step>
<step>
Закрыть тканью и оставить на один час в тёплом помещении.
</step>
<step>
Замесить ещё раз, положить на противень и поставить в духовку.
</step>
</instructions>
</recipe>'xml2Для работы с xml понадобится установить библиотеку xml2. Функция read_xml() создаст объект, представляющий дерево XML.
doc <- read_xml(string_xml)
class(doc)[1] "xml_document" "xml_node" Функция xml_root() позволяет извлечь корневой элемент вместе со всеми детьми.
rootnode <- xml_root(doc)
rootnode{xml_document}
<recipe name="хлеб" preptime="5min" cooktime="180min">
[1] <title>\n Простой хлеб\n </title>
[2] <composition>\n <ingredient amount="3" unit="стакан">Мука</ingredient>\n ...
[3] <instructions>\n <step>\n Смешать все ингредиенты и тщательно зам ...У корневого элемента есть “дети”. Это набор узлов.
xml_children(rootnode){xml_nodeset (3)}
[1] <title>\n Простой хлеб\n </title>
[2] <composition>\n <ingredient amount="3" unit="стакан">Мука</ingredient>\n ...
[3] <instructions>\n <step>\n Смешать все ингредиенты и тщательно зам ...У детей есть имена, которые можно извлечь специальной функцией.
xml_name(xml_children(rootnode))[1] "title" "composition" "instructions"Обращаться к узлам можно по имени или по индексу.
# 1. Выбрать узел по имени:
composition_node <- xml_find_first(rootnode, "composition")
composition_node{xml_node}
<composition>
[1] <ingredient amount="3" unit="стакан">Мука</ingredient>
[2] <ingredient amount="0.25" unit="грамм">Дрожжи</ingredient>
[3] <ingredient amount="1.5" unit="стакан">Тёплая вода</ingredient># 2. Выбрать узел по индексу (например, второй дочерний узел):
composition_node <- xml_children(rootnode)[[2]]
composition_node{xml_node}
<composition>
[1] <ingredient amount="3" unit="стакан">Мука</ingredient>
[2] <ingredient amount="0.25" unit="грамм">Дрожжи</ingredient>
[3] <ingredient amount="1.5" unit="стакан">Тёплая вода</ingredient># 3. Комбинировать выбор: второй узел -> первый элемент:
ingr_node_1 <- xml_find_first(composition_node, "ingredient")
ingr_node_1{xml_node}
<ingredient amount="3" unit="стакан">Но обычно нам нужен не элемент как таковой, а его содержание (значение). Чтобы добраться до него, используем функцию xml_text():
xml_children(composition_node) |>
xml_text()[1] "Мука" "Дрожжи" "Тёплая вода"Можно уточнить атрибуты узла при помощи xml_attrs():
xml_children(composition_node) |>
xml_attrs()[[1]]
amount unit
"3" "стакан"
[[2]]
amount unit
"0.25" "грамм"
[[3]]
amount unit
"1.5" "стакан" Чтобы извлечь значение атрибута, используем функцию xml_attr(). Первым аргументом функции передаем xml-узел, вторым – имя атрибута.
xml_attr(xml_children(composition_node), "unit")[1] "стакан" "грамм" "стакан"Добраться до узлов определенного уровня можно также при помощи синтаксиса XPath. XPath – это язык запросов к элементам XML-документа. С его помощью можно описать “путь” до нужного узла: абсолютный (начиная с корневого элемента) или относительный. В пакете xml синтаксис XPath поддерживает функция xml_find_all().
# абсолютный путь
xml_find_all(rootnode, "/recipe//composition//ingredient"){xml_nodeset (3)}
[1] <ingredient amount="3" unit="стакан">Мука</ingredient>
[2] <ingredient amount="0.25" unit="грамм">Дрожжи</ingredient>
[3] <ingredient amount="1.5" unit="стакан">Тёплая вода</ingredient># относительный путь
xml_find_all(rootnode, "//composition//ingredient"){xml_nodeset (3)}
[1] <ingredient amount="3" unit="стакан">Мука</ingredient>
[2] <ingredient amount="0.25" unit="грамм">Дрожжи</ingredient>
[3] <ingredient amount="1.5" unit="стакан">Тёплая вода</ingredient># атрибут unit == "стакан"
xml_find_all(rootnode, "//composition//ingredient[@unit='стакан']"){xml_nodeset (2)}
[1] <ingredient amount="3" unit="стакан">Мука</ingredient>
[2] <ingredient amount="1.5" unit="стакан">Тёплая вода</ingredient>При работе с xml в большинстве случаев наша задача – извлечь значения определеннных узлов или их атрибутов и сохранить их в прямоугольном формате.
# Получаем узлы:
title <- xml_find_all(rootnode, "title") |>
xml_text() |>
trimws()
ingredient_ns <- xml_find_all(rootnode, "//composition//ingredient")
tibble(
title = title,
ingredients = xml_text(ingredient_ns),
unit = xml_attr(ingredient_ns, "unit"),
amount = xml_attr(ingredient_ns, "amount")
) |>
print()# A tibble: 3 × 4
title ingredients unit amount
<chr> <chr> <chr> <chr>
1 Простой хлеб Мука стакан 3
2 Простой хлеб Дрожжи грамм 0.25
3 Простой хлеб Тёплая вода стакан 1.5 Теперь рассмотрим более сложные примеры.
TEI (Text Encoding Initiative) — специализированный язык разметки на основе XML, разработанный как средство формального кодирования наиболее значимых текстологических свойств документа: физических параметров рукописи, критического аппарата, лингвистической информации, выходных данных, сведений об авторе, обстоятельствах публикации и первоисточнике (Скоринкин 2016). TEI появился в 1987 г. и в наши дни стал де-факто стандартом для создания цифровых гуманитарных ресурсов.
Основная задача структурированной разметки — формальное эксплицитное представление некоторых свойств документа, заложенных в нем имплицитно. Например, для человека очевидно, где в тексте романа кончается одна часть и начинается другая, какие герои упоминаются в той или иной главе, какие реплики кем произнесены. Однако для машины ничего из этого не является «очевидным» — электронный текст без разметки остается не более чем цепочкой символов.
Большая часть размеченных литературных корпусов хранится именно в формате XML. Это очень удобно, и вот почему: с помощью тегов XML мы можем достать из документа именно то, что нам интересно: определенную главу, речи конкретных персонажей, слова на иностранных языках и т.п.
Использование TEI обеспечивает:
Добавлять и удалять разметку может любой пользователь в редакторе XML кода или даже в простом текстовом редакторе. Стандарт TEI предоставляет исследователям универсальный метаязык для обмена текстологической информацией и встраивает документы в мировую коллекцию машиночитаемых текстов.
Корневой элемент в документах TEI называется TEI, внутри него располагается элемент teiHeader с метаинформацией о документе и элемент text. Последний содержит текст документа с элементами, определяющими его структурное членение.
<TEI>
<teiHeader></teiHeader>
<text></text>
</TEI>Пример оформления документа можно посмотреть по ссылке.
У teiHeader есть четыре главных дочерних элемента:
fileDesc (описание документа c библиографической информацией)encodingDesc (описание способа кодирование первоисточника)profileDesc (“досье” на текст, например отправитель и получатель для писем, жанр, используемые языки, обстоятельства создания, место написания и т.п.)revisionDesc (история изменений документа).Элемент fileDesc должен содержать полную библиографическую информацию о первоисточнике. Пример для повести Л.Н. Толстого «Детство»:
<fileDesc>
<titleStmt>
<title>Повесть «Детство». Электронное издание.</title>
<author>Толстой Л.Н.</author>
<editor>Иванов И.И.</editor>
<respStmt>
<resp>Подготовка и разметка метаинформации для электронного издания</resp>
<name>Иванов И.И.</name>
</respStmt>
</titleStmt>
<publicationStmt>
<publisher>Школа лингвистики <orgName>НИУ ВШЭ</orgName></publisher>
<availability>
<p>Распространяется свободно</p>
</availability>
</publicationStmt>
<sourceDesc>
<biblStruct>
<author>Толстой Л.Н.</author>
<title level="a">Детство</title>
<monogr>
<title level="m">Полное собрание сочинений. Том 1</title>
<imprint>
<pubPlace>Москва</pubPlace>
<publisher>Государственное издательство "Художественная литература"</publisher>
<date when="1935"/>
</imprint>
</monogr>
</biblStruct>
</sourceDesc>
</fileDesc>Элемент <profileDesc> содержит метаданные, относящиеся непосредственно к тексту:
<profileDesc>
<creation>
<date when="1852">1852</date>
<placeName>Москва</placeName>
<placeName>станица Старогладковская</placeName>
<placeName>Тифлис</placeName>
</creation>
<langUsage>
<language ident="rus" usage="99">Русский</language>
<language ident="fra" usage="0,5">Французский</language>
<language ident="deu" usage="0,5">Немецкий</language>
</langUsage>
<textClass>
<catRef type="type" target="#short_novel"/>
</textClass>
</profileDesc>В самом тексте язык TEI дает возможность представлять разные варианты (авторские, редакторские, корректорские и др.) Основным средством параллельного представления является элемент choice. Например, в тексте Лукреция вы можете увидеть такое:
sic calor atque <choice><reg>aer</reg><orig>aër</orig></choice> et venti caeca potestasЗдесь reg указывает на нормализованное написание, а orig – на оригинальное.
Для исправления ошибок используются элементы <sic> («так у автора») и <corr> («исправленное написание»):
<choice>
<sic>вихремъ</sic>
<corr resp="#editor1">верхомъ</corr>
</choice>Атрибут resp содержит ссылку на идентификатор редактора.
TEI предоставляет богатый набор элементов для разметки структуры текста:
<text> — текст целиком<body> — основное содержание текста<div> — структурное деление (глава, часть, раздел)<p> — параграф<l> — стихотворная строка<lg> — группа стихотворных строк (строфа)<sp> — речь персонажа в драме<stage> — ремаркаПример разметки поэзии:
<lg type="quatrain">
<l met="+-|+-|+-|+-">Дар напрасный, дар случайный,</l>
<l met="+-|+-|+-|+">Жизнь, зачем ты мне дана?</l>
<l met="+-|+-|+-|+-">Иль зачем судьбою тайной</l>
<l met="+-|+-|--|+">Ты на казнь осуждена?</l>
</lg>Скачаем по из репозитория проекта Dracor “Горе от ума” Грибоедова и преобразуем xml в прямоугольный формат таким образом, чтобы для каждой реплики был указан акт, сцена и действующее лицо.
url <- "https://raw.githubusercontent.com/dracor-org/rusdracor/main/tei/griboyedov-gore-ot-uma.xml"
download_xml(url, file = "griboedov.xml")doc <- read_xml("griboedov.xml")
# определить пространство имён
ns <- xml_ns(doc)
nsd1 <-> http://www.tei-c.org/ns/1.0Пространство имён (namespace) в XML — это механизм, который позволяет однозначно различать элементы и атрибуты с одинаковыми именами, но из разных словарей или стандартов. Оно действует как “фамилия” для элемента. Чтобы задать “фамилию”, её связывают с уникальным идентификатором (обычно это URI, в нашем случае http://www.tei-c.org/ns/1.0). Для удобства этому идентификатору присваивают короткий префикс.
# Найти все строки (tei:l)
line_nodes <- xml_find_all(doc, "//d1:l", ns)
# Извлечь текст каждой строки
line_text <- xml_text(line_nodes)
line_text |>
head()[1] "Светает!.. Ах! как скоро ночь минула!"
[2] "Вчера просилась спать — отказ."
[3] "«Ждем друга». — Нужен глаз да глаз,"
[4] "Не спи, покудова не скатишься со стула."
[5] "Теперь вот только что вздремнула,"
[6] "Уж день!.. сказать им..." Теперь нам надо для каждой реплики найти информацию о том, кто говорит: она хранится в теге <speaker>. То есть нам надо подняться на два этажа вверх (на уровень <sp>), а потом спуститься к его другому “ребенку”, <speaker>. Для этого используем синтаксис XPath: сначала при помощи ancestor::d1:sp поднимаемся вверх по дереву и выбираем всех предков узла, которые являются элементами sp, а затем спускаемся к ребенку speaker этого найденного sp. Так список спикеров будет равно числу стихов.
# line_nodes — вектор узлов <l>
speakers <- xml_find_first(line_nodes, "ancestor::d1:sp/d1:speaker", ns = ns) |>
xml_text()
speakers |>
head()[1] "Лизанька" "Лизанька" "Лизанька" "Лизанька" "Лизанька" "Лизанька"Аналогичным образом находим явление и акт.
scenes <- xml_find_first(line_nodes, "ancestor::d1:div[@type='scene']/d1:head", ns = ns) |>
xml_text()
scenes |>
tail()[1] "Явление 15" "Явление 15" "Явление 15" "Явление 15" "Явление 15"
[6] "Явление 15"acts <- xml_text(
xml_find_first(line_nodes, "ancestor::d1:div[@type='act']/d1:head", ns = ns)
)
acts |>
sample(6)[1] "Действие второе" "Действие четвертое" "Действие четвертое"
[4] "Действие четвертое" "Действие первое" "Действие третье" Нам осталось объединить все векторы в одну таблицу.
woe_from_wit <- tibble(
act = acts,
scene = scenes,
speaker = speakers,
text = line_text
)| act | scene | speaker | text |
|---|---|---|---|
| Действие первое | Явление 1 | Лизанька | Светает!.. Ах! как скоро ночь минула! |
| Действие первое | Явление 1 | Лизанька | Вчера просилась спать — отказ. |
| Действие первое | Явление 1 | Лизанька | «Ждем друга». — Нужен глаз да глаз, |
| Действие первое | Явление 1 | Лизанька | Не спи, покудова не скатишься со стула. |
| Действие первое | Явление 1 | Лизанька | Теперь вот только что вздремнула, |
| Действие первое | Явление 1 | Лизанька | Уж день!.. сказать им... |
Дедлайн: 14 ноября 21-00.
Оценивание: 0/1
Данные, подробные инструкции и заготовку для скрипта вы найдете в репозитории. Репозиторий надо клонировать (создать новый локальный проект под контролем версий), отредактировать скрипт согласно инструкции (не переименовывайте файл!), запушить изменения.
Проверка автоматическая, обычно занимает до 20 минут, выполняется после каждого коммита / пуша. Можно пушить сколько угодно раз до дедлайна. В случае прохождения всех тестов (после обновления страницы) вы увидите зеленую галочку.
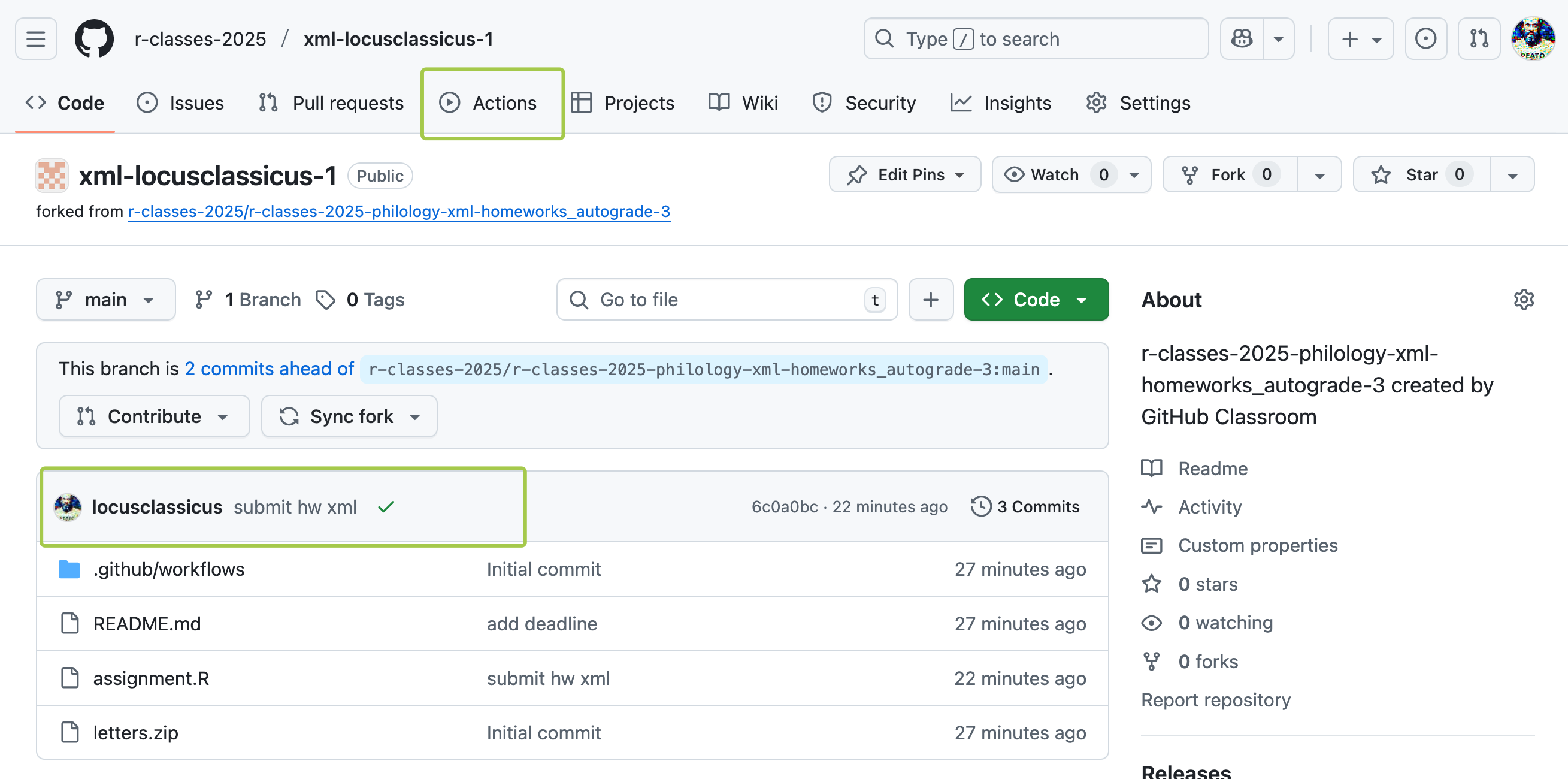
Почему это не быстро? Потому что GitHub Actions при каждой проверке запускает “чистую” виртуальную машину (как правило, Ubuntu), где установлены только базовые вещи типа R, Python и т.д.
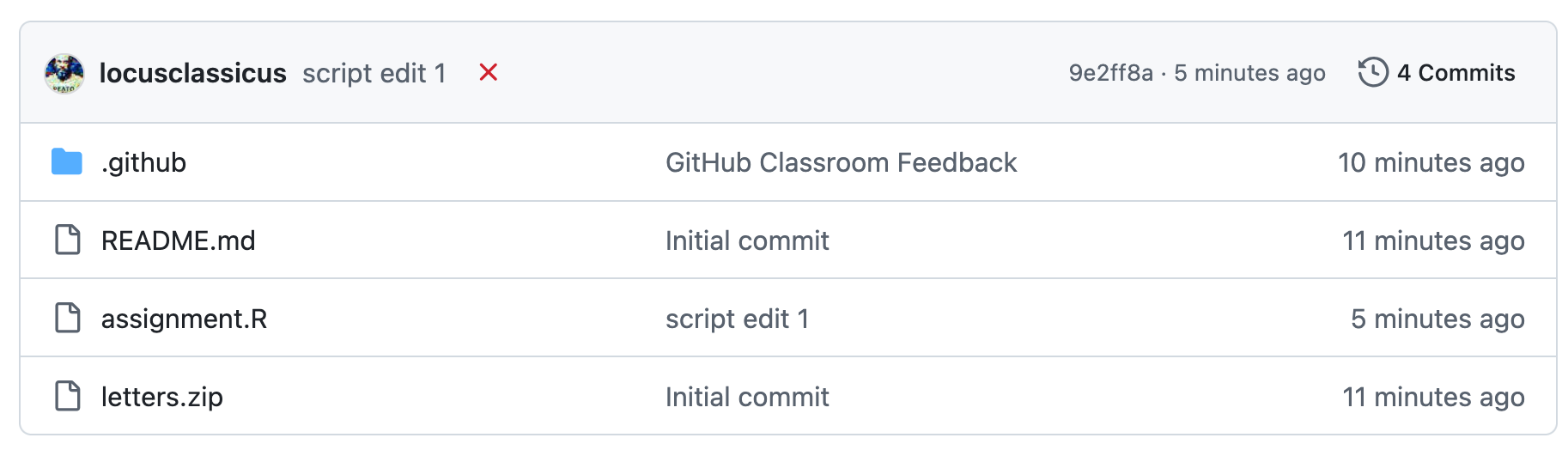
Если тесты не пройдены, напротив коммита будет красный крест.
Вот так выглядит вкладка Actions. Желтый цвет означает, что workflow в работе.
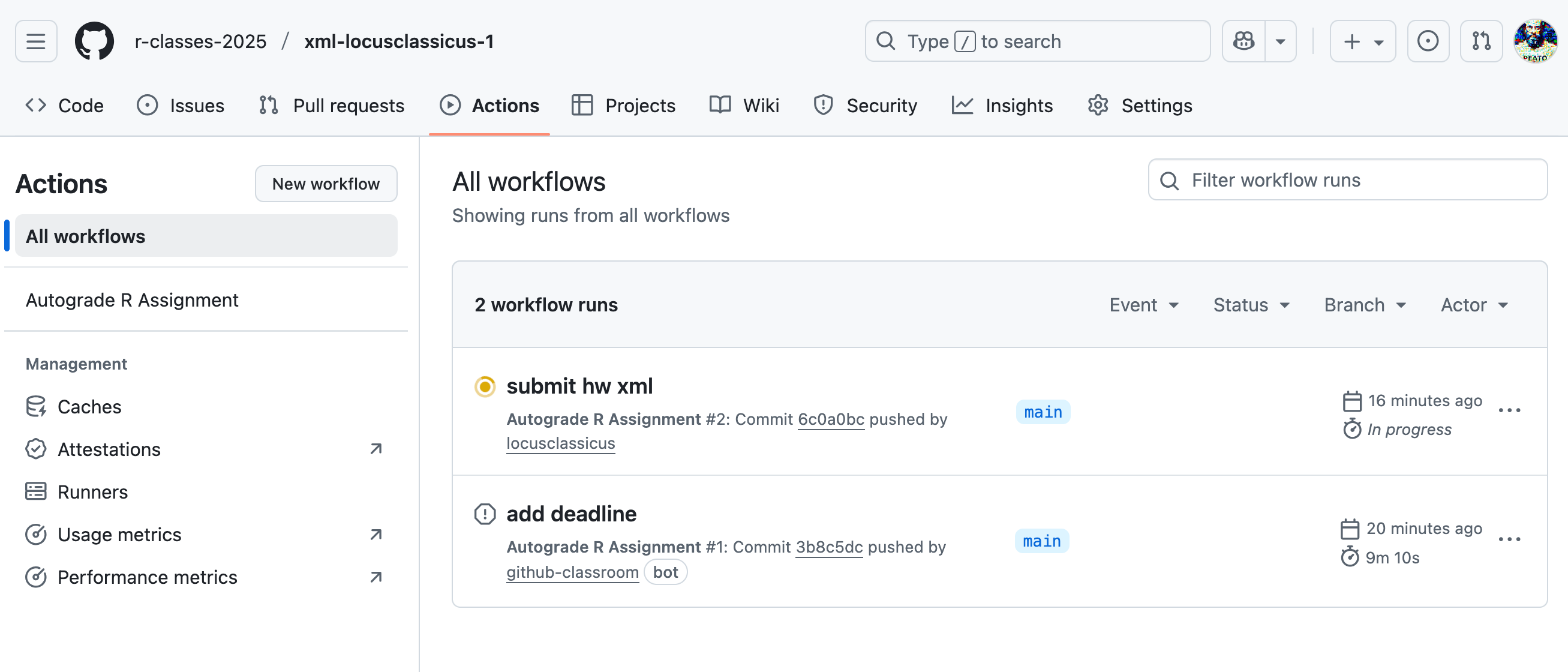 Если нажать на коммит (здесь:
Если нажать на коммит (здесь: sumbit hw xml) -> test -> Run tests, можно увидеть детали проверки.
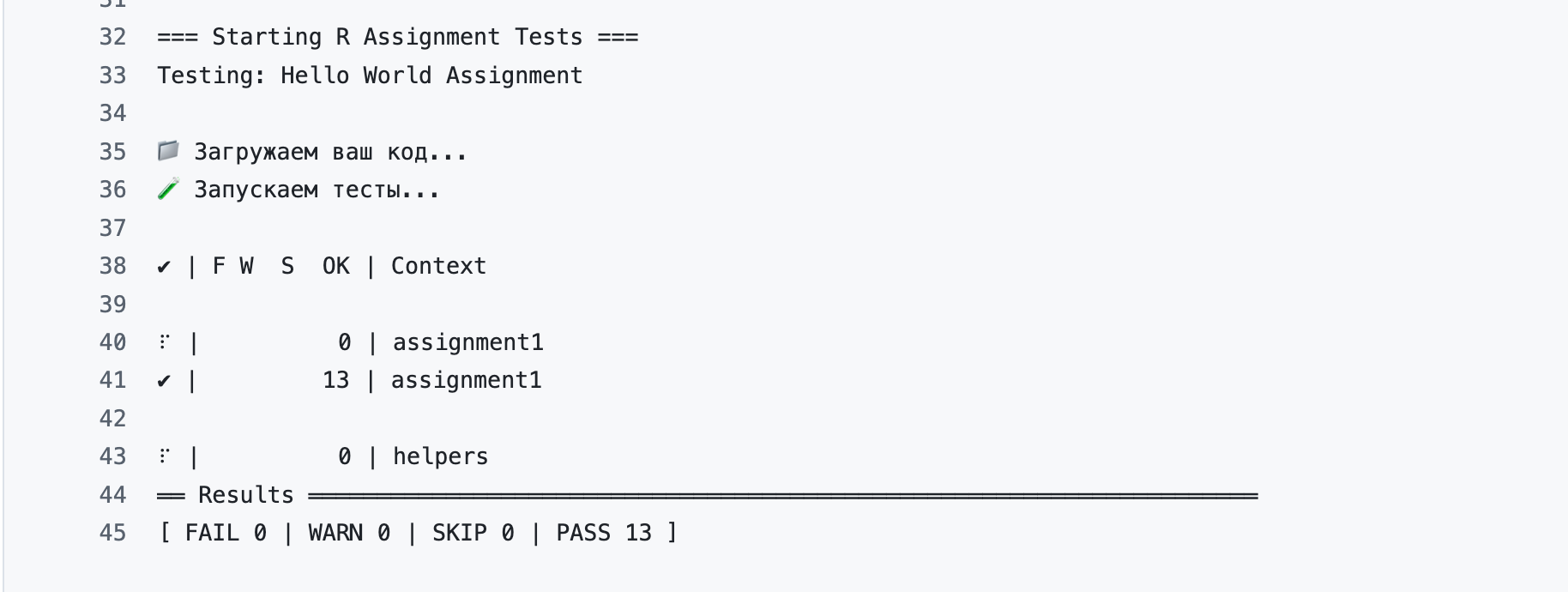
Внимательно читайте сообщения об ошибках! Их можно и нужно показывать LLM (например, DeepSeek), которые помогут доработать код.
Ваша задача: добиться прохождения всех тестов! В противном случае задание не засчитывается.
Подбробнее о структуре XML документов и способах работы с ними вы можете прочитать в книгах: (Nolan и Lang 2014) и (Холзнер 2004).