Тема 4 Опрятные данные
Tidy datasets are all alike, but every messy dataset is messy in its own way.
— Hadley Wickham
4.1 Синтаксис tidyverse
Существуют два основных “диалекта” R, один из которых опирается главным образом на функции и структуры данных базового R, а другой пользуется синтаксисом tidyverse (Winter 2020). Tidyverse – это семейство пакетов (метапакет), разработанных Хадли Уикхемом и др., которое включает в себя в том числе пакеты dplyr, ggplot2 и многие другие.
4.1.1 Tibble
Основная структура данных в tidyverse – это tibble, современный вариант датафрейма7. Тиббл, как говорят его разработчики, это ленивые и недовольные датафреймы: они делают меньше и жалуются больше8. Это позволяет решать проблемы на более ранних этапах, что, как правило, приводит к созданию более чистого и выразительного кода.
Основные отличия от обычного датафрейма:
- текст по умолчанию конвертируется в строки, а не в факторы;9
- усовершенствованный метод
print(), не нужно постоянно вызыватьhead(); - нет имен рядов;
- допускает синтаксически “неправильные” имена столбцов;
- при индексировании не меняет тип данных на вектор и др.
load("./data/DiorisisMeta.Rdata")
# распечатывает только первые 10 рядов, для каждого столбца указан тип данных, строки пронумерованы
as_tibble(diorisis_meta)## # A tibble: 784 × 5
## name title date genre subgenre
## <chr> <chr> <dbl> <chr> <chr>
## 1 Achilles Tatius Leucippe and Clitop… 120 Narr… Novel
## 2 Aelian De Natura Animalium 230 Tech… Natural…
## 3 Aelian Epistulae Rusticae 230 Lett… Letters
## 4 Aelian Varia Historia 200 Essa… Miscell…
## 5 Aeneas Tacticus Poliorcetica -350 Tech… Military
## 6 Aeschines Against Ctesiphon -330 Orat… Oratory
## 7 Aeschines Against Timarchus -347 Orat… Oratory
## 8 Aeschines The Speech on the E… -336 Orat… Oratory
## 9 Aeschylus Agamemnon -458 Trag… Tragedy
## 10 Aeschylus Eumenides -458 Trag… Tragedy
## # ℹ 774 more rows## [1] "Achilles Tatius" "Aelian" "Aelian"
## [4] "Aelian" "Aeneas Tacticus" "Aeschines"## # A tibble: 784 × 1
## name
## <chr>
## 1 Achilles Tatius
## 2 Aelian
## 3 Aelian
## 4 Aelian
## 5 Aeneas Tacticus
## 6 Aeschines
## 7 Aeschines
## 8 Aeschines
## 9 Aeschylus
## 10 Aeschylus
## # ℹ 774 more rows## var.1 two
## 1 1 3
## 2 2 4## # A tibble: 2 × 2
## `var 1` two
## <int> <int>
## 1 1 3
## 2 2 4Пора тренироваться.
Установите курс swirl::install_course("Getting and Cleaning Data"). Загрузите библиотеку library(swirl), запустите swirl(), выберите этот курс и пройдите из него урок 1 Manipulating Data with dplyr.
При попытке загрузить урок вы можете получить сообщение об ошибке: /Library/Frameworks/R.framework/Versions/4.1-arm64/Resources/library/swirl/Courses/Getting_and_Cleaning_Data/Manipulating_Data_with_dplyr/lesson.yaml) Scanner error: while scanning a tag at line 205, column 9 did not find expected whitespace or line break at line 205, column 19. Скопируйте путь до папки с курсом. На MacOS откройте Finder > Go > Go to Folder. Вставьте путь до папки в открывшееся окно, найдите там файл lesson.yaml. Скачайте исправленный файл по ссылке и замените его в папке. Не меняйте название! Обсуждение проблемы здесь.
Все попробовали, не получилось?
Ну и ладно. Двигайтесь дальше.
Все получилось?
Классно! Двигайтесь дальше.
Время вопросов! Обычный датафрейм или тиббл?
По умолчанию распечатывает только первые 10 рядов в консоль.
Молчаливо исправляет некорректные названия столбцов.
По умолчанию конвертирует строки в факторы при импорте данных.
Не имеет названий рядов.
Кстати, обратили внимание, как работает оператор <= с символьным вектором?
4.1.2 Dplyr
В уроке swirl выше вы уже немного познакомились с “грамматикой манипуляции данных”, лежащей в основе dplyr10. Здесь об этом будет сказано подробнее. Эта грамматика предоставляет последовательный набор глаголов, которые помогают решать наиболее распространенные задачи манипулирования данными:
mutate()добавляет новые переменные, которые являются функциями существующих переменных;select()выбирает переменные на основе их имен;filter()выбирает наблюдения на основе их значений;summarise()обобщает значения;arrange()изменяет порядок следования строк.
Все эти глаголы естественным образом сочетаются с функцией group_by(), которая позволяет выполнять любые операции “по группам”, и с оператором pipe %>% из пакета magrittr.
В итоге получается более лаконичный и читаемый код, что можно показать на примере.
diorisis_meta %>%
select(-subgenre) %>%
filter(genre == "Narrative") %>%
group_by(name) %>%
count() %>%
arrange(-n)## # A tibble: 20 × 2
## # Groups: name [20]
## name n
## <chr> <int>
## 1 Plutarch 71
## 2 Appian 14
## 3 Flavius Josephus 4
## 4 Xenophon 4
## 5 Arrian 3
## 6 Diodorus Siculus 3
## 7 Philostratus the Athenian 2
## 8 Achilles Tatius 1
## 9 Cassius Dio 1
## 10 Chariton 1
## 11 Diogenes Laertius 1
## 12 Dionysius of Halicarnassus 1
## 13 Eusebius of Caesarea 1
## 14 Herodotus 1
## 15 Longus 1
## 16 Lucian 1
## 17 Polybius 1
## 18 Pseudo Apollodorus 1
## 19 Thucydides 1
## 20 Xenophon of Ephesus 1В базовом R мы бы делали то же самое вот так:
diorisis_df <- as.data.frame(diorisis_meta)
diorisis_select <- diorisis_df[,-5] # remove column
diorisis_filter <- diorisis_select[diorisis_select$genre == "Narrative", ]
diorisis_names <- diorisis_filter$name
diorisis_count <- as.data.frame(table(diorisis_names))
diorisis_sort <- diorisis_count[order(diorisis_count$Freq, decreasing =T),]
head(diorisis_sort)## diorisis_names Freq
## 15 Plutarch 71
## 2 Appian 14
## 10 Flavius Josephus 4
## 19 Xenophon 4
## 3 Arrian 3
## 6 Diodorus Siculus 3Тут должен быть какой-то поучительный вывод. Но вместо него будет задание на кодинг. Вам придется редактировать код, который предложит программа, так что сгруппируйтесь.
Запустите swirl(), выберите курс Getting and Cleaning Data и пройдите из него урок 2 Grouping and Chaining with dplyr.
Правда или ложь?
Функция n_distinct() возвращает все уникальные значения.
Если x <- 1:100, то функция quantile(x, probs = 0.9) вернет значения от 91 до 100.
Кванти́ль в математической статистике — значение, которое заданная случайная величина не превышает с фиксированной вероятностью. В нашем случае 90% данных ниже 90.1.
Это было сложное задание, можно сделать перерыв ☕
4.2 Опрятные данные
Но tidyverse – это не только особый синтаксис, но и отдельная идеология “опрятных данных”. “Сырые” данные, с которыми мы работаем, редко бывают опрятны, и перед анализом их следует “почистить” и преобразовать11.
Основные принципы опрятных данных:
- отдельный столбец для каждой переменной;
- отдельный ряд для каждого наблюдения;
- у каждого значения отдельная ячейка;
- один датасет – одна таблица.

Посмотрите на учебные тибблы из пакета tidyr и подумайте, какое из этих правил нарушено в каждом случае.
## # A tibble: 12 × 4
## country year type count
## <chr> <dbl> <chr> <dbl>
## 1 Afghanistan 1999 cases 745
## 2 Afghanistan 1999 population 19987071
## 3 Afghanistan 2000 cases 2666
## 4 Afghanistan 2000 population 20595360
## 5 Brazil 1999 cases 37737
## 6 Brazil 1999 population 172006362
## 7 Brazil 2000 cases 80488
## 8 Brazil 2000 population 174504898
## 9 China 1999 cases 212258
## 10 China 1999 population 1272915272
## 11 China 2000 cases 213766
## 12 China 2000 population 1280428583## # A tibble: 6 × 3
## country year rate
## <chr> <dbl> <chr>
## 1 Afghanistan 1999 745/19987071
## 2 Afghanistan 2000 2666/20595360
## 3 Brazil 1999 37737/172006362
## 4 Brazil 2000 80488/174504898
## 5 China 1999 212258/1272915272
## 6 China 2000 213766/1280428583## # A tibble: 3 × 3
## country `1999` `2000`
## <chr> <dbl> <dbl>
## 1 Afghanistan 745 2666
## 2 Brazil 37737 80488
## 3 China 212258 213766## # A tibble: 3 × 3
## country `1999` `2000`
## <chr> <dbl> <dbl>
## 1 Afghanistan 19987071 20595360
## 2 Brazil 172006362 174504898
## 3 China 1272915272 1280428583Важные функции для преобразования данных из пакета tidyr:12
separate()делит один столбец на новые;unite()объединяет столбцы;pivot_longer()удлиняет таблицу;pivot_wider()расширяет таблицу;drop_na()иreplace_na()указывают, что делать с NA и др.
Также упомянем функцию distinct() из dplyr, которая оставляет только уникальные наблюдения и предсталяет собой аналог базовой unique() для таблиц.
Кроме того, в dplyr есть полезное семейство функций _join, позволяющих объединять данные в различных таблицах.13 Дальше мы потренируемся с ними работать, но сначала пройдем урок swirl. Это достаточно сложный урок (снова понадобится редактировать скрипт), но он нам дальше здорово поможет.
Запустите swirl(), выберите курс Getting and Cleaning Data и пройдите из него урок 3 Tidying Data with tidyr.
Правда или ложь?
Функция separate() обязательно требует указать разделитель.
Принципы опрятных данных требуют, чтобы одному наблюдению соответствовал один столбец.
Функция contains() используется вместе с filter() для выбора рядов.
Отличная работа! Прежде чем двигаться дальше, приведите в порядок table2, 3, 4a-4b (последние две также объедините) в единый датасет.
ПРАКТИЧЕСКОЕ ЗАДАНИЕ 3: БИБЛИОТЕКА GUTENBERG
devtools::install_github("ropensci/gutenbergr")
library(gutenbergr)
library(dplyr)
library(tidyr)
works <- gutenberg_works()
# Отберите ряды, в которых gutenberg_author_id равен 65;
# после этого выберите два столбца: author, title
my_data <- works %>%
# ваш код здесь
# Загрузите данные об авторах и выберите столбцы: author, deathdate
authors <- gutenberg_authors %>%
# ваш код здесь
# Соедините my_data с данными о смерти автора из authors,
# так чтобы к my_data добавился новый столбец.
# После этого используйте функцию separate,
# чтобы разделить столбец с именем и фамилией на два новых: author, name.
# Удалите столбец с именем автора, оставив только фамилию.
# Добавьте новый столбец century,
# используя функцию mutate и данные из столбца deathdate.
# Используйте оператор pipe, не сохраняйте промежуточные результаты!
my_data %>%
# ваш код здесь4.3 Пример: буккроссинг
4.3.1 Смотрим на данные
Загрузим пример неопрятных данных и попробуем их преобразовать для анализа. Book-Crossing – датасет с рейтингами миллионов книг и обезличенными демографическими данными о более 250 тысячах их читателей. Этот датасет хранится в трех разных таблицах.
ratings <- read_delim("files/BX/BX-Book-Ratings.csv", delim = ";")
ratings
books <- read_delim("files/BX/BX-Books.csv", delim = ";")
books
users <- read_delim("files/BX/BX-Users.csv", delim = ";")
userssave(users, file = "data/UsersBX.Rdata")
save(books, file = "data/BooksBX.Rdata")
save(ratings, file = "data/RatingsBX.Rdata")## # A tibble: 6 × 3
## `User-ID` ISBN `Book-Rating`
## <dbl> <chr> <dbl>
## 1 276725 034545104X 0
## 2 276726 0155061224 5
## 3 276727 0446520802 0
## 4 276729 052165615X 3
## 5 276729 0521795028 6
## 6 276733 2080674722 0## # A tibble: 6 × 3
## `User-ID` Location Age
## <dbl> <chr> <chr>
## 1 1 nyc, new york, usa NULL
## 2 2 stockton, california, usa 18
## 3 3 moscow, yukon territory, russia NULL
## 4 4 porto, v.n.gaia, portugal 17
## 5 5 farnborough, hants, united kingdom NULL
## 6 6 santa monica, california, usa 61## # A tibble: 6 × 8
## ISBN `Book-Title` `Book-Author` `Year-Of-Publication`
## <chr> <chr> <chr> <dbl>
## 1 01951534… Classical M… Mark P. O. M… 2002
## 2 00020050… Clara Callan Richard Bruc… 2001
## 3 00609731… Decision in… Carlo D'Este 1991
## 4 03741570… Flu: The St… Gina Bari Ko… 1999
## 5 03930452… The Mummies… E. J. W. Bar… 1999
## 6 03991357… The Kitchen… Amy Tan 1991
## # ℹ 4 more variables: Publisher <chr>, `Image-URL-S` <chr>,
## # `Image-URL-M` <chr>, `Image-URL-L` <chr>Что не так с этими данными?
usersсодержит больше одного значения в столбце Location- много отсутствующих значений
- данные вводятся самими пользователями через сайт https://www.bookcrossing.com/ ; они могут содержать недостоверную информацию, см. напр.
moscow, yukon territory, russia(Юкон – это территория Канады). - Age представляет собой строку и др.
Прежде чем начинать преобразование, надо сформулировать примерный вопрос и понять, что для нас важно, а что нет.
Например: - Сколько читателей старше 30 лет пользуются сервисом в Австралии? - В какие года опубликованы самые популярные книги? - Кто популярнее у читателей, Роулинг или Толкин? - Какой процент пользователей никогда не оставляет отзывы? - Есть ли связь между возрастом и количеством оценок? и т.п.
Чтобы объединить данные, надо понять, через какие переменные они связаны.
Ответ: ratings и books связаны через переменную isbn, ratings и users связаны через переменную User-ID.
4.3.2 Трансформируем данные
Начнем с пользователей.
users_separated <- users %>%
mutate(Age = as.numeric(Age)) %>%
filter(!is.na(Age)) %>% # drop_na(Age) тоже решил бы нашу задачу
separate(Location, into = c(NA, NA, "country"), sep = ",")
head(users_separated) # можно было бы не сохранять, но так нагляднее## # A tibble: 6 × 3
## `User-ID` country Age
## <dbl> <chr> <dbl>
## 1 2 " usa" 18
## 2 4 " portugal" 17
## 3 6 " usa" 61
## 4 10 " spain" 26
## 5 11 " australia" 14
## 6 13 " spain" 26Здесь можно сразу посмотреть, из каких стран и какого возраста пользователи.
## # A tibble: 543 × 2
## # Groups: country [543]
## country n
## <chr> <int>
## 1 " usa" 67138
## 2 " united kingdom" 10935
## 3 " canada" 9877
## 4 " spain" 9505
## 5 " germany" 8016
## 6 " australia" 7824
## 7 <NA> 5914
## 8 " italy" 4754
## 9 " france" 2395
## 10 " portugal" 2175
## # ℹ 533 more rowsПоследние ряды этого тибла выглядят достаточно причудливо:
## # A tibble: 543 × 2
## # Groups: country [543]
## country n
## <chr> <int>
## 1 " pasig city." 1
## 2 " 中国" 1
## 3 " 美国" 1
## 4 " 5057chadwick ct." 1
## 5 " 600 083" 1
## 6 " \\n/a\\\"" 1
## 7 " a new year is ahead" 1
## 8 " aberdeenshire" 1
## 9 " agusan del sur" 1
## 10 " alabama" 1
## # ℹ 533 more rowsЗдесь возможно несколько стратегий. Можно выбрать все ряды с названиями реальных стран либо (если это соответствует исследовательской задаче) какую-то одну страну. Можно и проигнорировать, если происхождение пользователей не так важно.
Допустим, мы решаем сосредоточиться на Испании. Обратите внимание, что в название страны после разделения функцией separate() попали пробелы, и от них надо избавиться. Это делается при помощи регулярных выражений (о них в другой раз) и функции mutate().
spain_data <- users_separated %>%
mutate(country = str_replace_all(country, pattern = "\\s+", "")) %>% # это означает, что пробел мы меняем на "ничто", т.е. убираем
filter(country == "spain") %>%
group_by(Age) %>%
count() %>%
arrange(-n)
head(spain_data)## # A tibble: 6 × 2
## # Groups: Age [6]
## Age n
## <dbl> <int>
## 1 25 514
## 2 26 510
## 3 23 480
## 4 24 467
## 5 28 459
## 6 27 450Столбиковая диаграмма подходит для визуализации подобных данных:
spain_data %>%
ggplot(aes(Age, n)) +
geom_bar(stat = "identity", col = "blue", fill = "white") +
theme_bw()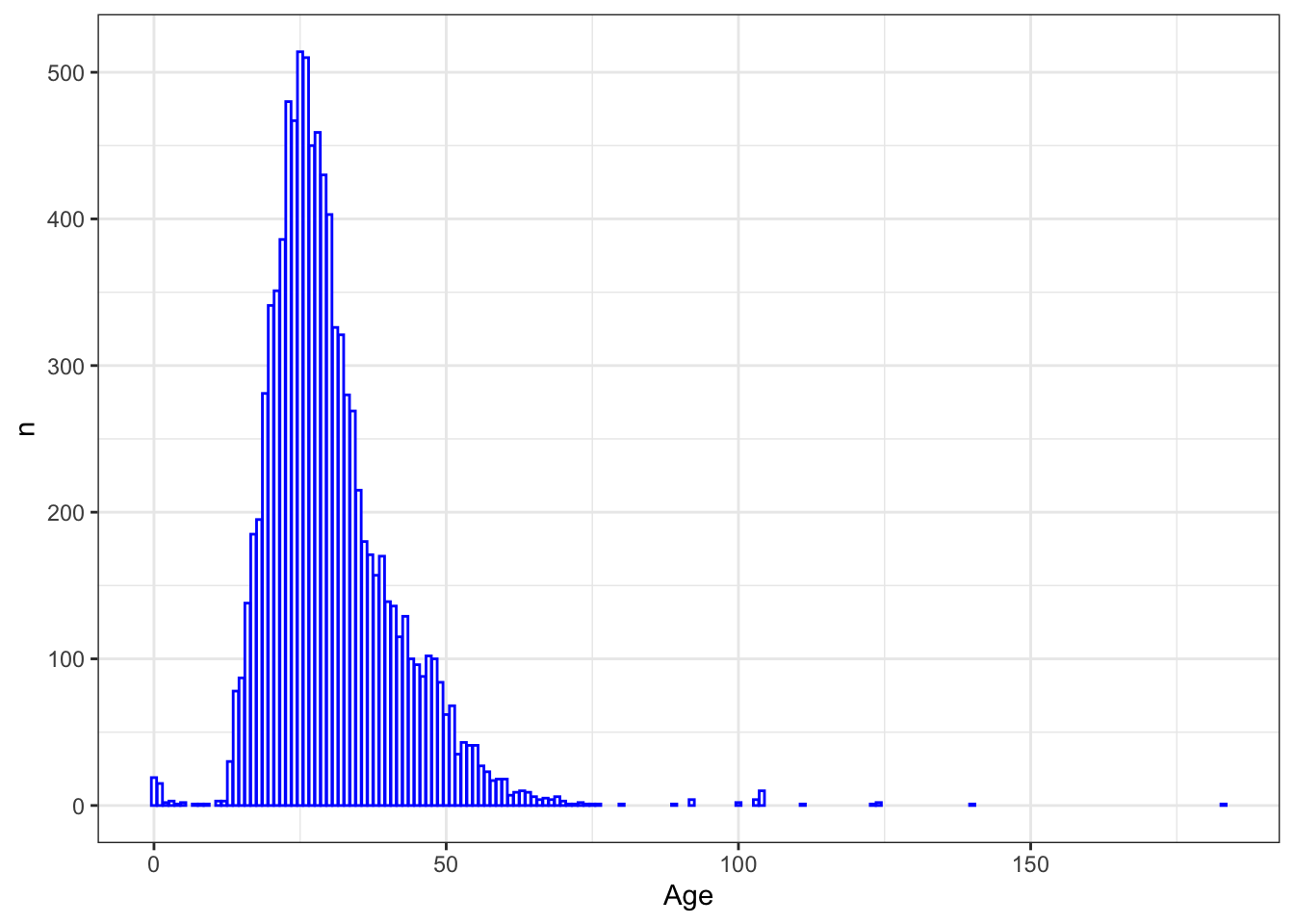
Какие целеустремленные испанцы! Читают от 0 до 183 лет 😵
После того, как мы убрали лишние пробелы из названий стран, можно фильтровать:
4.3.3 Объединяем данные
Мы уже выяснили, что ratings и users связаны через переменную User-ID, и в ratings хотели бы оставить только те id, которые отвечают заданному условию (страна, возраст и т.п.). Для такого рода объединений как раз подходят функции _join14.
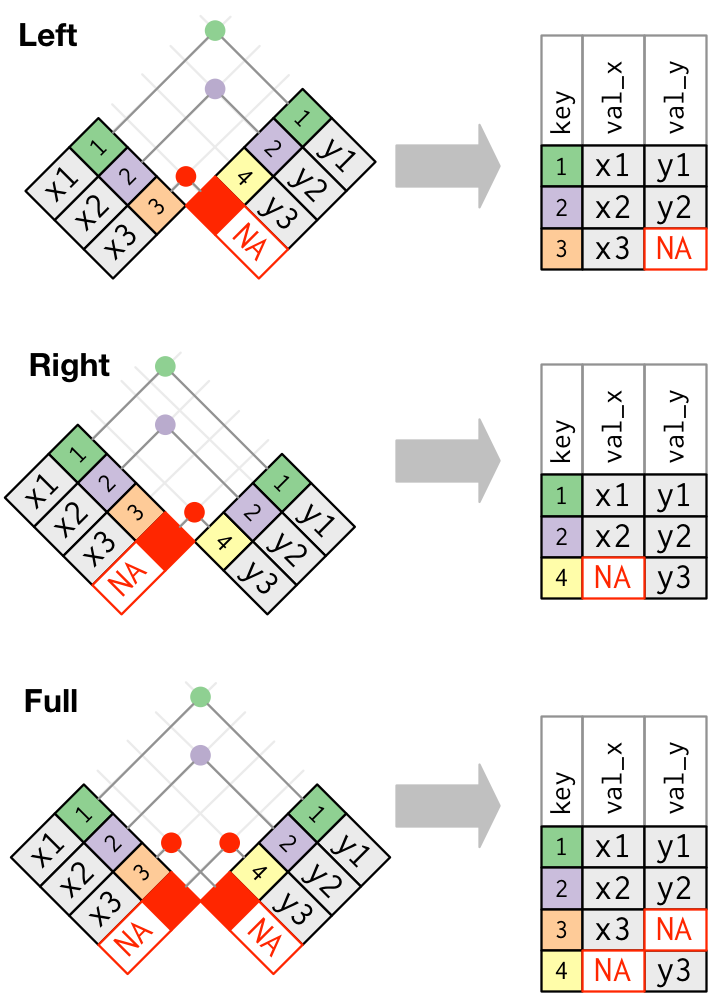{kind=link}
spain_ratings <- spain_id %>%
left_join(ratings) %>%
filter(!is.na(ISBN)) %>%
filter(`Book-Rating` > 7) %>% # имена синтаксически неправильные, поэтому требуется знак "`"
group_by(ISBN) %>%
count() %>%
arrange(-n)## Joining with `by = join_by(`User-ID`)`## # A tibble: 1,281 × 2
## # Groups: ISBN [1,281]
## ISBN n
## <chr> <int>
## 1 8432206407 4
## 2 8433969978 4
## 3 846630679X 4
## 4 8472236552 4
## 5 8495501198 4
## 6 840149186X 3
## 7 8401499585 3
## 8 8423310353 3
## 9 8423662152 3
## 10 8432215007 3
## # ℹ 1,271 more rowsОсталось выяснить, что это за книги. Для этого объединяем spain_ratings и books.
spain_books <- spain_ratings %>%
filter(n > 2) %>%
left_join(books) %>%
filter(!is.na(`Book-Title`), !is.na(`Book-Author`)) %>%
ungroup()
spain_books## # A tibble: 15 × 9
## ISBN n `Book-Title` `Book-Author`
## <chr> <int> <chr> <chr>
## 1 8432206407 4 Sin Noticias De Gurb (Bib… Eduardo Mend…
## 2 8433969978 4 El Libro de Las Ilusiones Paul Auster
## 3 846630679X 4 La caverna = A caverna Jose Saramago
## 4 8472236552 4 UN Viejo Que Leia Novelas… Luis Sepulve…
## 5 8495501198 4 Memorias de una geisha Arthur Golden
## 6 840149186X 3 El Club de Los Poetas Mue… N. H. Kleinb…
## 7 8401499585 3 Los Pilares de La Tierra Ken Follett
## 8 8423310353 3 El Camino (Coleccion Dest… Miguel Delib…
## 9 8432215007 3 El perfume Patrick Susk…
## 10 8445071408 3 El Senor De Los Anillos: … J. R. R. Tol…
## 11 8445071416 3 El Hobbit J. R. R. Tol…
## 12 8477204055 3 El caballero de la armadu… Robert Fisher
## 13 8478884459 3 Harry Potter y la piedra … J. K. Rowling
## 14 8484602508 3 Diario de Un Skin: Un Top… Antonio Salas
## 15 8495501112 3 Son De Mar Manuel Vicent
## # ℹ 5 more variables: `Year-Of-Publication` <dbl>,
## # Publisher <chr>, `Image-URL-S` <chr>,
## # `Image-URL-M` <chr>, `Image-URL-L` <chr>Как минимум мы выяснили, что испанцы предпочитают читать по-испански! (Здесь снова можно подумать. Возможно, у одной книги разные ISBN, и стоило группировать не по ISBN, а по названию или автору?)
Осталось избавиться от неинформативных столбцов (это ссылки, часто битые, на изображения обложки). Если мы знаем номера этих столбцов, то это можно сделать по индексу:
## # A tibble: 15 × 3
## title author `Year-Of-Publication`
## <chr> <chr> <dbl>
## 1 Sin Noticias De Gurb (Bibli… Eduar… 1995
## 2 El Libro de Las Ilusiones Paul … 2003
## 3 La caverna = A caverna Jose … 2002
## 4 UN Viejo Que Leia Novelas D… Luis … 1993
## 5 Memorias de una geisha Arthu… 2001
## 6 El Club de Los Poetas Muert… N. H.… 1995
## 7 Los Pilares de La Tierra Ken F… 1995
## 8 El Camino (Coleccion Destin… Migue… 1991
## 9 El perfume Patri… 1997
## 10 El Senor De Los Anillos: LA… J. R.… 2001
## 11 El Hobbit J. R.… 1991
## 12 El caballero de la armadura… Rober… 2000
## 13 Harry Potter y la piedra fi… J. K.… 1999
## 14 Diario de Un Skin: Un Topo … Anton… 2003
## 15 Son De Mar Manue… 2002Однако у select() есть функции-помощники15, которые подходят для таких случаев:
starts_with()ends_with()contains()matches()num_range()
spain_books %>%
select(-contains("URL"), -matches("Publisher")) %>% # удалим заодно и издателя
rename(title = `Book-Title`,
author = `Book-Author`,
published = `Year-Of-Publication`) # чиним имена## # A tibble: 15 × 5
## ISBN n title author published
## <chr> <int> <chr> <chr> <dbl>
## 1 8432206407 4 Sin Noticias De Gurb (… Eduar… 1995
## 2 8433969978 4 El Libro de Las Ilusio… Paul … 2003
## 3 846630679X 4 La caverna = A caverna Jose … 2002
## 4 8472236552 4 UN Viejo Que Leia Nove… Luis … 1993
## 5 8495501198 4 Memorias de una geisha Arthu… 2001
## 6 840149186X 3 El Club de Los Poetas … N. H.… 1995
## 7 8401499585 3 Los Pilares de La Tier… Ken F… 1995
## 8 8423310353 3 El Camino (Coleccion D… Migue… 1991
## 9 8432215007 3 El perfume Patri… 1997
## 10 8445071408 3 El Senor De Los Anillo… J. R.… 2001
## 11 8445071416 3 El Hobbit J. R.… 1991
## 12 8477204055 3 El caballero de la arm… Rober… 2000
## 13 8478884459 3 Harry Potter y la pied… J. K.… 1999
## 14 8484602508 3 Diario de Un Skin: Un … Anton… 2003
## 15 8495501112 3 Son De Mar Manue… 2002Возможно, сюда стоит добавить что-то про работу с факторами. Но не сейчас.
Литература
Подробнее о том, почему так вообще происходит: https://simplystatistics.org/posts/2015-07-24-stringsasfactors-an-unauthorized-biography/↩︎