[1] 0.604888Стилометрия
2024-05-17
1851: шведский математик и логик Огастес де Морган предположил, что споры о подлинности Послания к евреям святого ап. Павла можно разрешить путем измерения средней длины слов.


1887: Американский геофизик Томас К. Менденхолл проверил гипотезу о том, что длина слов может быть отличительной характеристикой писателей. Он изложил свои идеи в журнале Science.
1859: изобретен спектральный анализ
1901: Менденхолл публикует статью в Popular Science Monthly, в которой показывает, что “характеристическая кривая” Кристофера Марлоу…
…совпадает с Шекспиром примерно так же, как Шекспир совпадает с самим собой.


1897: Винценты Лютославский, обобщая предыдущие исследования, вывел “Закон стилистической близости”: \(A = x1 + 2 \times x2 + 3 \times x3 + 4 \times x4\)

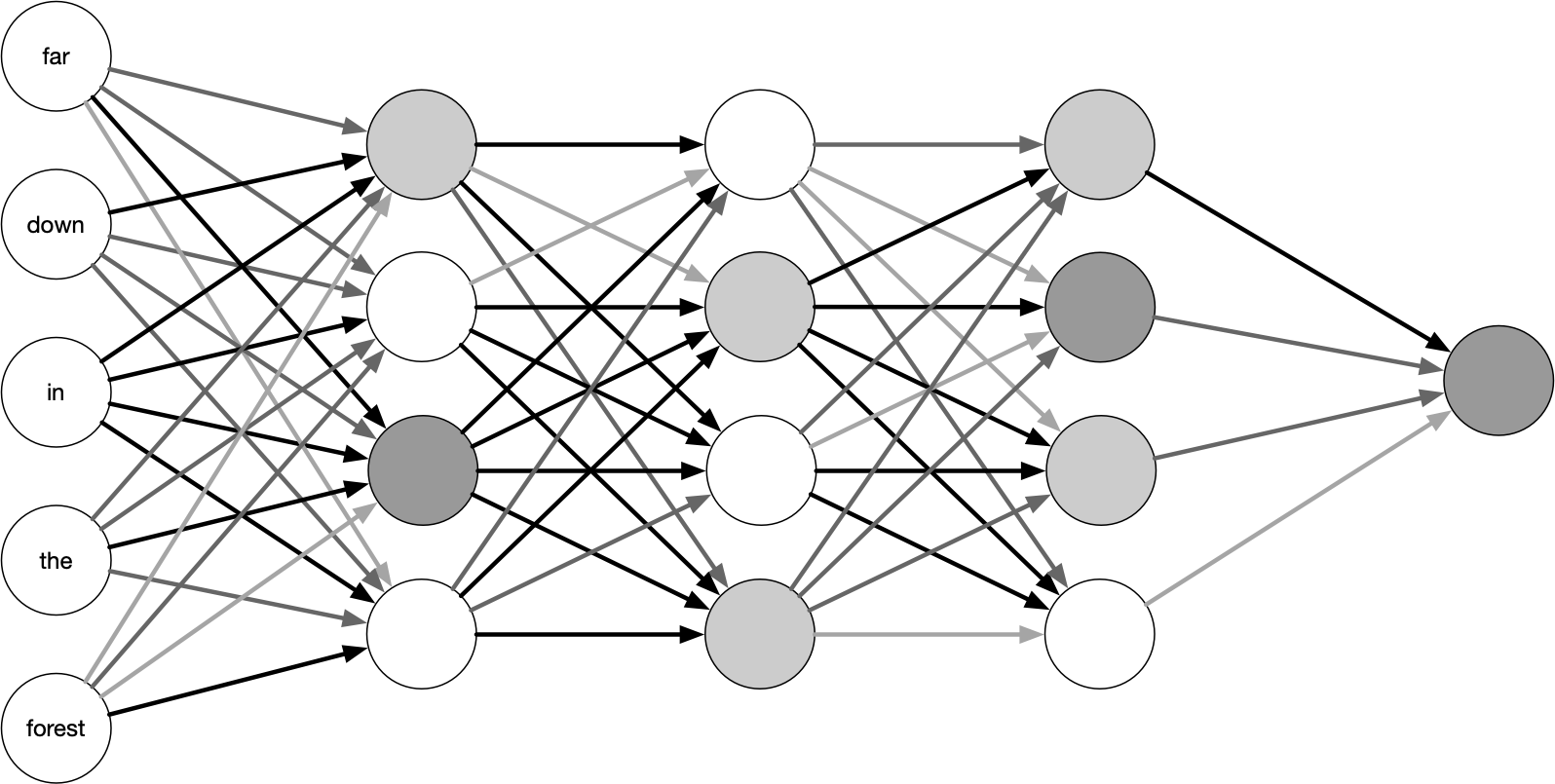
Метод кумулятивных сумм





Как это работает

NB: Современные имплементации алгоритма отличаются от метода, предложенного Р. Фишером в 1936 г.
Байесовские методы в стилометрии

Формула Байеса позволяет «переставить причину и следствие»: по известному факту события вычислить вероятность того, что оно было вызвано данной причиной.
Но слов-признаков много, и нам нужно все учесть:

Знаменатель будет для всех групп одинаков, поэтому:

Отсюда название “наивный Байес”: перемножение вероятностей покоится на допущении их независимости.
Вопрос: Что если в обучающем корпусе слово у какого-то автора не встречается?
Наивный Байес и конструирование признаков:


Линейно-дискриминантный анализ тоже достаточно привередливый:


2002: Джон Берроуз предлагает метод классификации под названием Delta. Смотри очень простой пример расчета.

Как считаются расстояния между векторами?

Rolling Delta
KNN - это алгоритм МО, в котором для отнесения объекта к классу используется информация о его соседях:


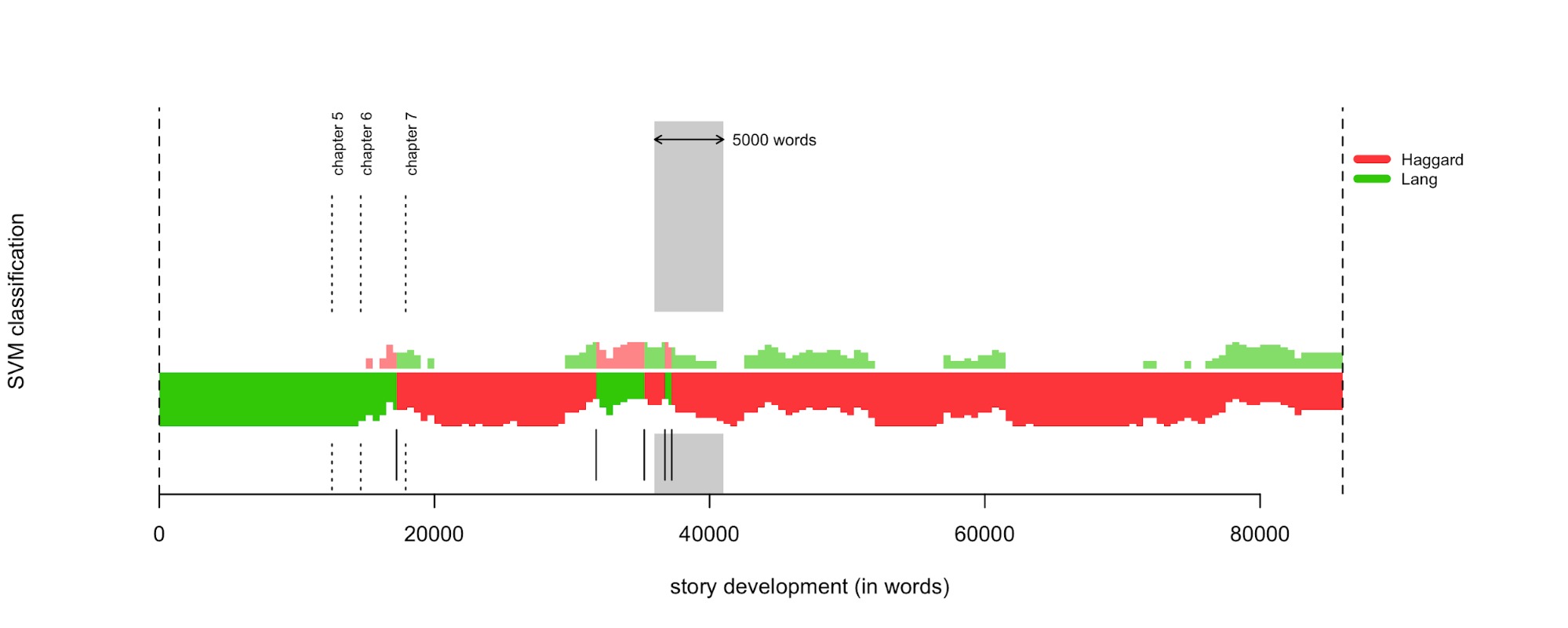
И “Зов кукушки” уходит… Роулинг!
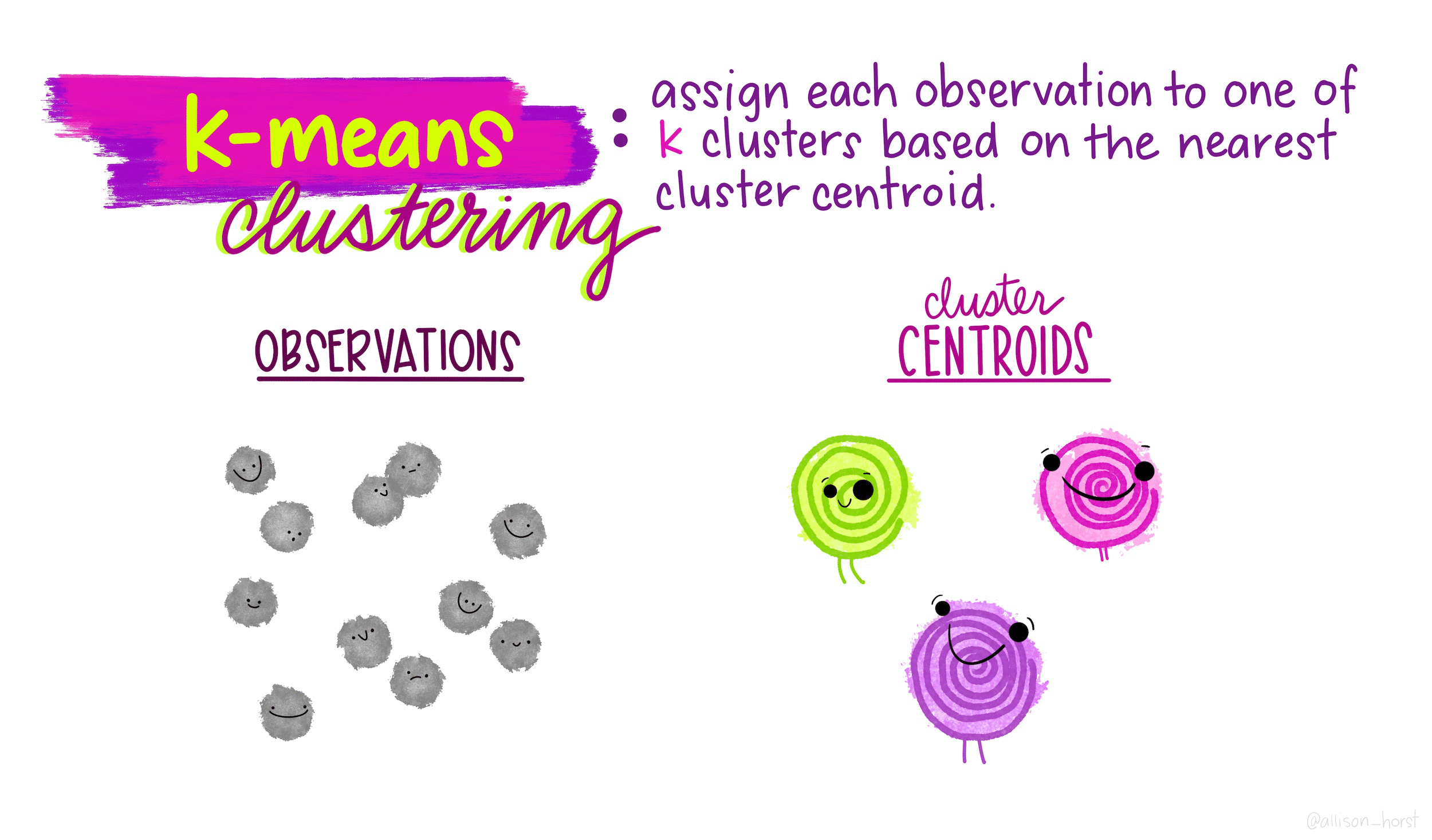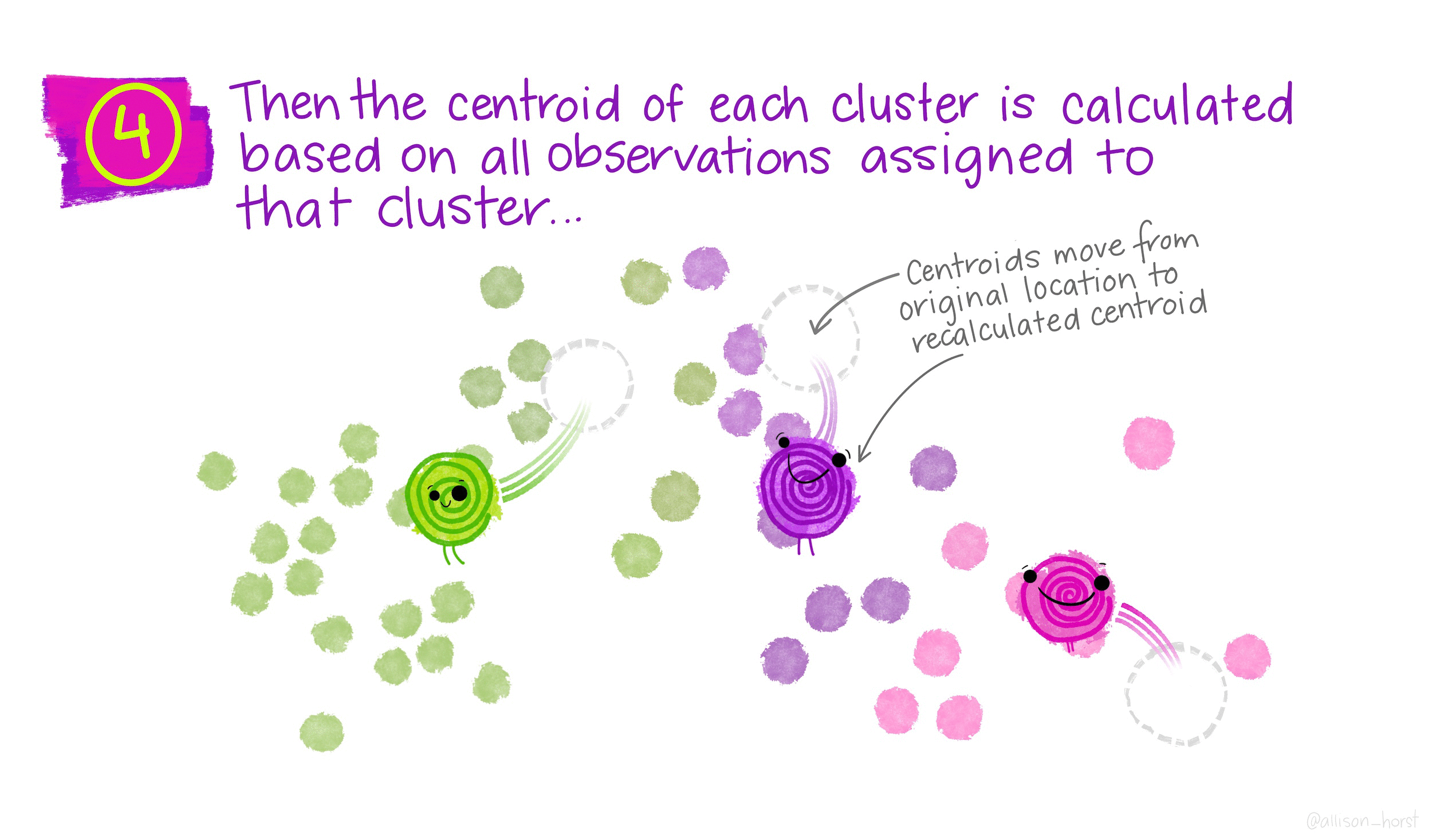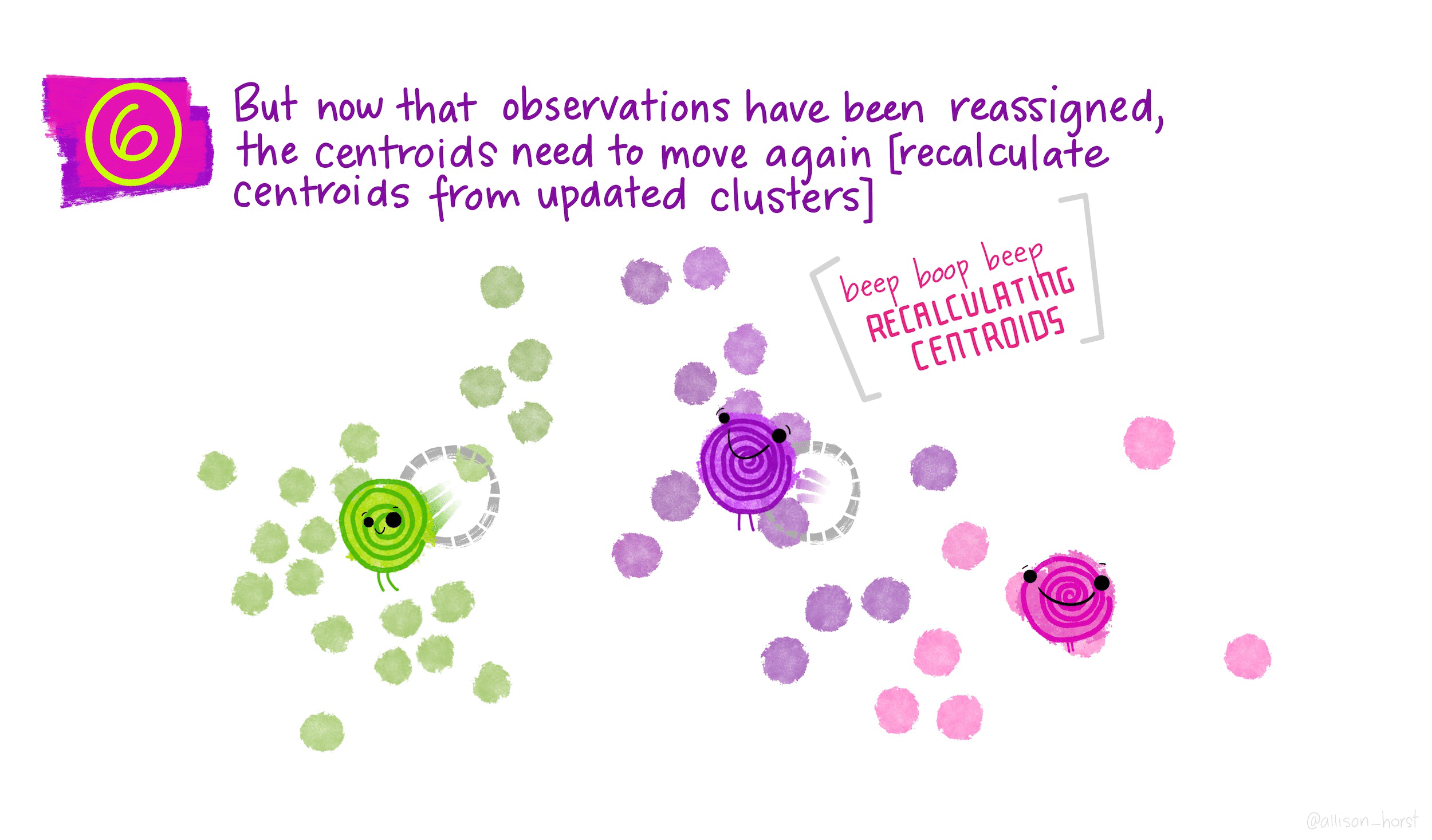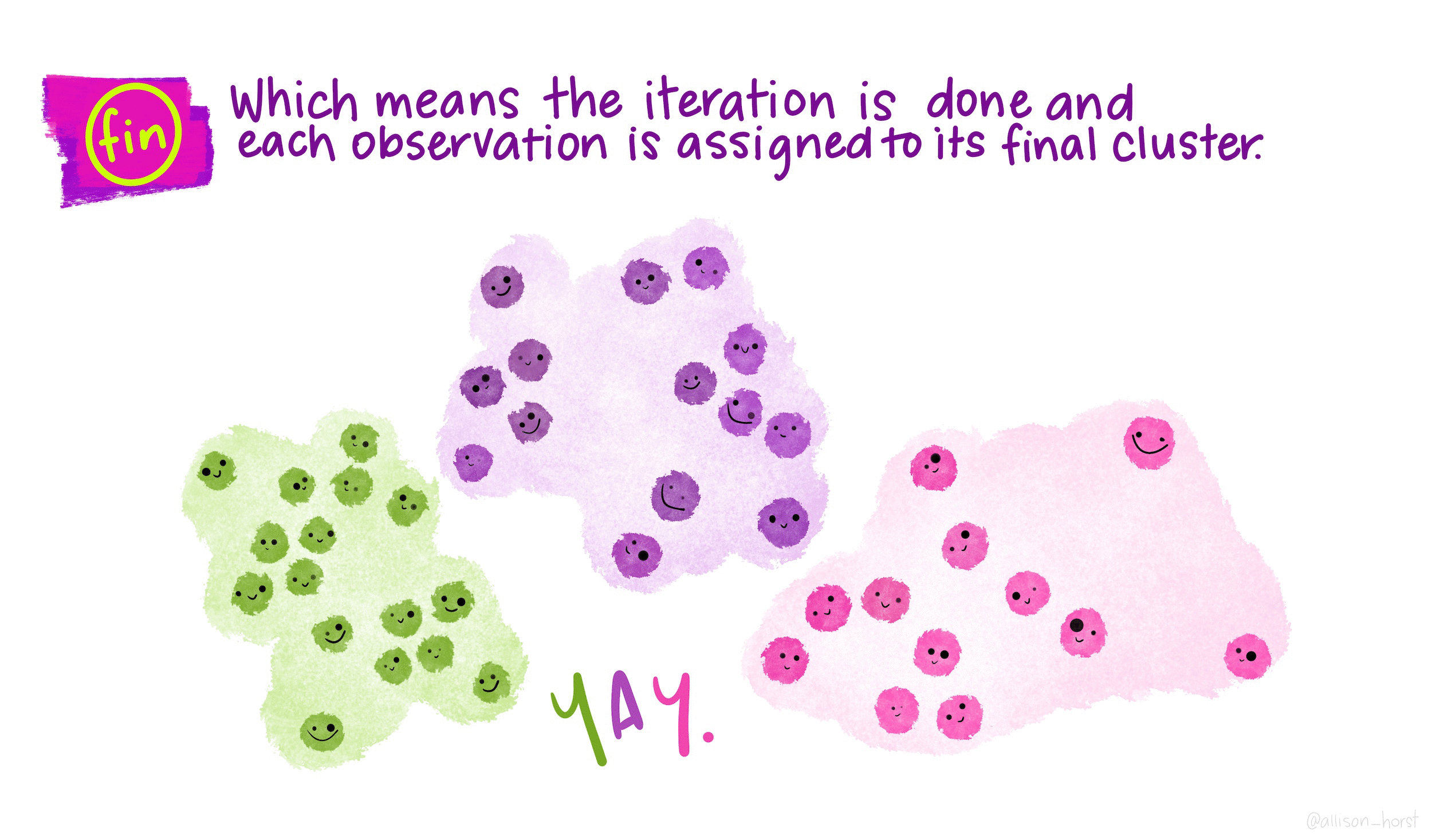
Вид дерева зависит от способа присоединения: среднее, полное, одиночное.

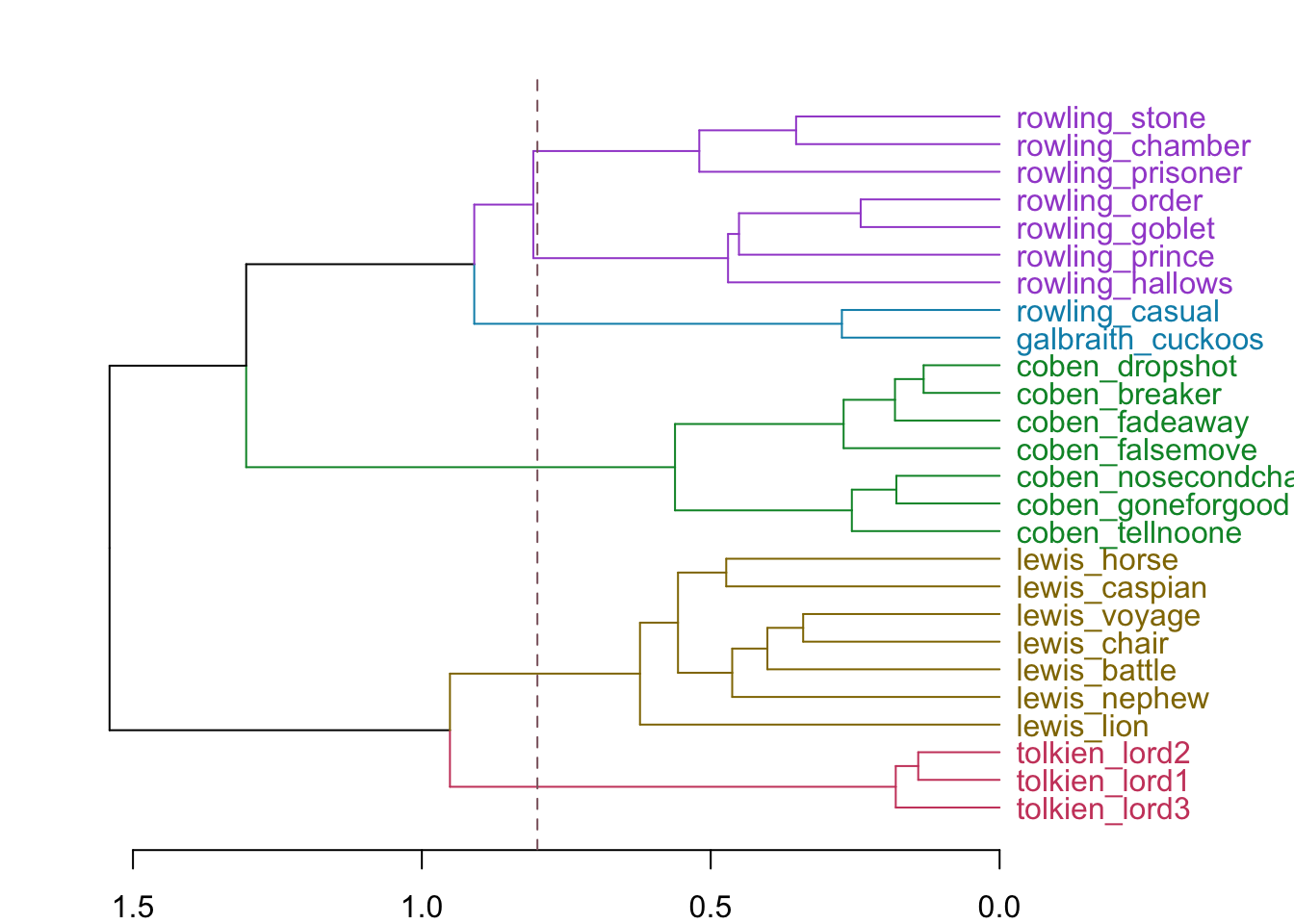


Вид дерева может меняться в зависимости от:
метрики расстояния
способа присоединения
числа признаков
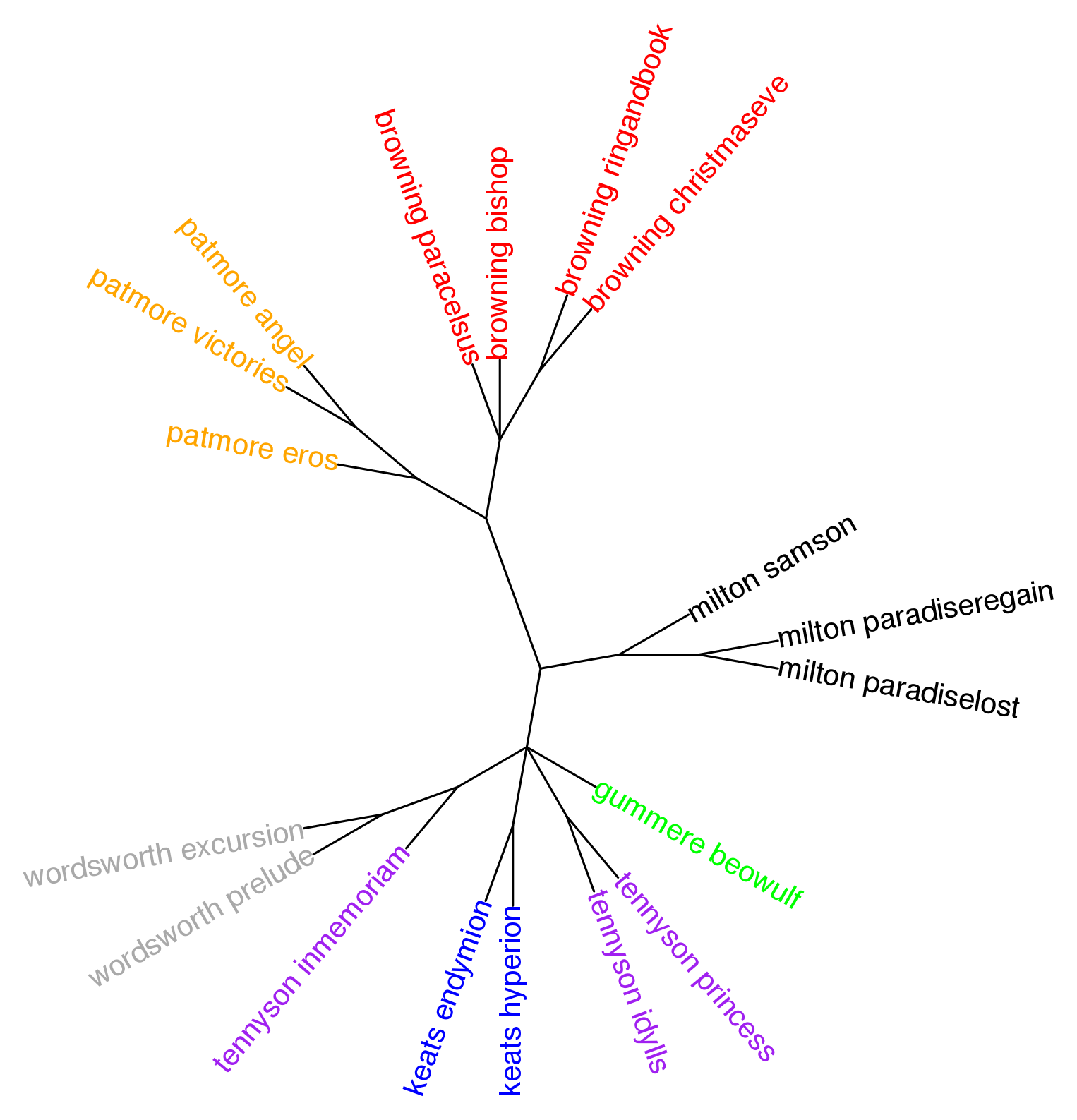
Консенсусное дерево
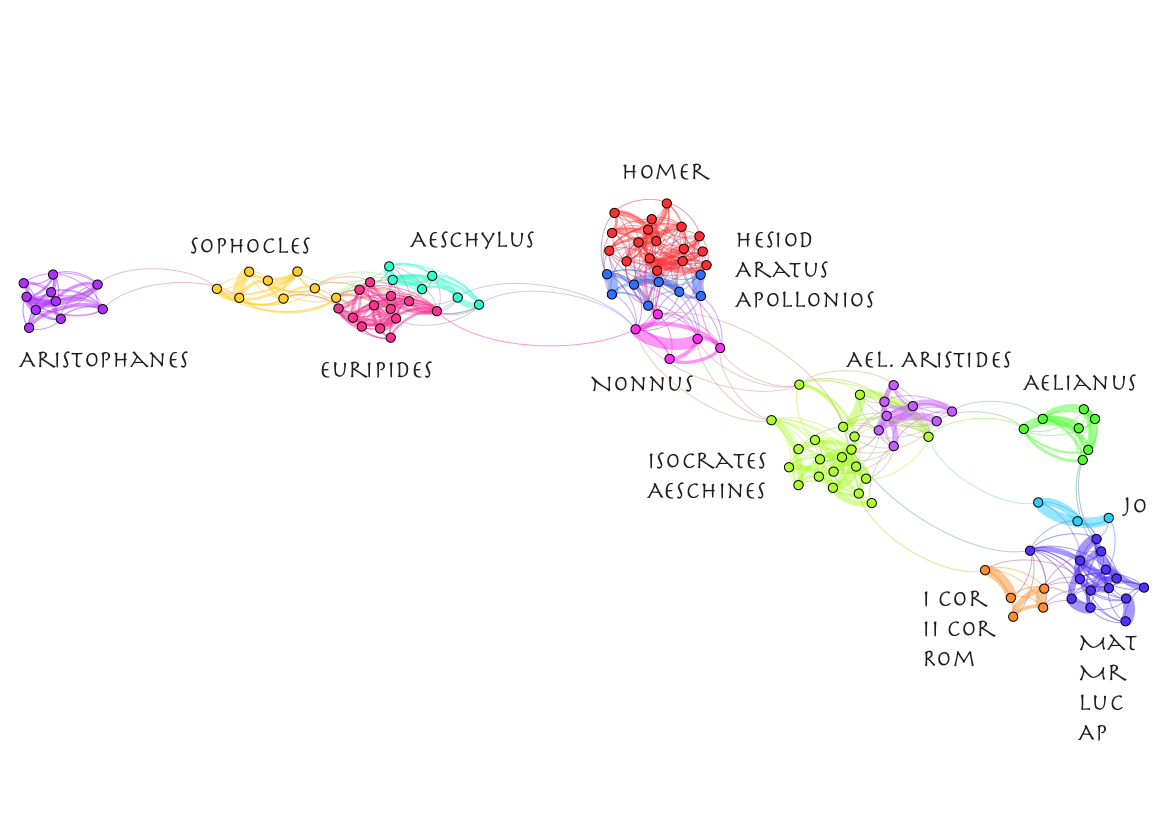
Консенсусная сеть. Источник.
:max_bytes(150000):strip_icc():format(webp)/friends-2000-a91360be0cbb460984bd179871081c32.jpg)
![]()

Классификация с использованием LDA: точность 0.292 (нулевая модель = 0.18)

Chose your fighter

У меня все
